The world is (not) flat 7 Feb 2024 11:50 AM (last year)
Vision Pro is not capable of delivering the level of low-strain fidelity needed to work long hours on anything related editing text. I think it is fair to say a 4k display or near equivalent is the minimum generally needed for this now, particularly for programming. [1]
Spatial Computing is not about arranging windows and using interfaces designed for flat surface devices.
It is about addressing problems using a three dimensional space. Instead of dashboard panels showing graphs in a window floating in the air, there are zones laid out in front of you showing data illustrated using 3D infographics
Apple has had to provide many examples and artful ways to work with windows because it is the only way people understand multi-tasking applications today.
“This device has to be good at window management or it isn’t a useful device” is the reasonable thinking of a person who will continue to spend most of their time in flat-land, relating to others who also live in flat-land computing.
I think Apple knows very well that traditional application presentation is not actually where visionOS / spatial computing aspires to be. You can almost derive this from the types of games they put in the Apple Arcade of the app store. These do more than anything else to show where productivity will go.
Even for programming, spatial computing will shine by providing intuitive and interactive visualizations of software systems and infrastructure. Not because it renders an IDE in a window really well. That’s what monitors are for!
In some way, how we solve problems has to evolve to make use of what spatial computing can provide.
Focusing on how the Vision Pro falls short of presenting the old interaction model served via hardware designed for that model is missing the true intent of the product and where it is all headed.
Apple is in a tough spot with this, because without handling some of the old way, the Vision Pro doesn’t solve any “real world” problems. However, spatial computing solutions to old problems do not really exist yet. Most VP apps are just rebuilt iPad stuff in windows.
I think this is why the home screen apps are locked and Apple is so careful to subjugate apps not designed for VP. Also, why the App Store doesn’t just show you a list of all apps published with VP entitlements.
I suspect they already have internal disagreement between product and marketing on what the low bar should be to qualify for an app getting to be listed as a Vision Pro-ready at all.
[1] I use an XDR Pro at my home office and a Dell U2723QE at my coworking space and the 4k is cringe-worthy in comparison. The VP comes nowhere near the experience of the Dell.









Rate Throttling in Django AllAuth while running Unit Tests 23 Oct 2023 2:17 PM (last year)
If you use Django AllAuth and have a custom account adapter, you may find you run up to against rate limits that prevent successful testing of the many unhappy paths of user signup workflows.
allauth.account.adapter.DefaultAccountAdapter I did not notice this until I overrode the clean_email() method of my custom adapter, after noticing some unhandled pentest reconnaissance in user signup on a production system.
This can show up as a Warning: Too Many Requests with the test assertion failure on a subsequent line related to some expected state for user account creation or maintenance.
Builtin rate limiting was added to the package in 0.48.0 (early 2022) and can be disabled in your custom test runner or elsewhere by ensuring the following is set in your settings.py:
ACCOUNT_RATE_LIMITS = {}
There are a variety of different behaviors that can have rate limits set to them in normal production usage. See documentation on ACCOUNT_RATE_LIMITS here.
Staying Hydrated in VR Workouts is Problematic 27 Jan 2023 10:41 PM (2 years ago)
A new report was published in The Information about the new Apple headset mentions the following:
People familiar with Apple’s content strategy for the headset say Apple executives are emphasizing health and wellness including proposals for AR apps that assist with meditation and exercise.
Apple Devising Software to Help Anyone Build AR Apps, to Drive Headset Sales by Wayne Ma
This reporting fits with my thinking that a fitness application like Supernatural would be a beachhead for the new Apple headset.
But the new report contains another key dimension that underscores a problem with VR workout apps and the limitations of what Meta/Facebook is working with.
Apple is focused on AR and doesn’t have much interest in VR, which senior executives find too isolating, say the people familiar with Apple’s efforts. That’s different from Meta’s approach, which has pushed VR games as a big feature of its consumer headsets.
The trick here is to not think of isolation as being a purely social problem. A go-to response to people bearish on headsets of any kind is the presumption that they will lock you away from other people.
For working out, VR is too isolating because you can’t stop to take a drink of water. Supernatural has some rather intense workouts and you really must stop to hydrate to get through one of any substantial length.
Except this means you must remove the headset, which breaks the experience completely, possibly throwing your sweatband into disarray.
The other option, which I’ve taken to is memorizing where in the room the cup is and cautiously extending your arms to break your guardian boundary and grab your water while replacing it carefully, sliding it on the table.
This is still a jarring and not-relaxing way to relax during a break–but at least you don’t have to readjust the headset.
Apple’s intent to provide exercise in AR overcomes this simple yet crucial isolation that VR imposes: You can step over to a glass of water and its not problem. It has been there the whole time.
I suspect the second half of the above quote about Meta’s approach is also a bit of a read-between-the-lines thing. It isn’t that Meta’s looked at AR and VR and found VR gaming is superior.
Meta looked at their market and the way Android was able to effectively compete with Apple. They will be forced to go low-cost and at least today that is a non-starter for any decent AR experience.
The Supernatural Lawsuit and Apple 10 Nov 2022 9:37 PM (2 years ago)
This is part two of a series XR, VR, AR 2022. See also my prior post, Dragon’s Lair and Hologram Time Traveler.
It is not a coincidence or a mistake that US Federal Government is suing Facebook (Meta) over the company’s acquisition of Within–the company behind the virtual reality exercise app “Supernatural.”
Venture capital friendly startups have multi-billion dollar ambitions. These companies must believe and proclaim they will deliver a product or service can serve as the gateway to entirely new markets by unleashing pent up, undiscovered demand inside everyday people.
Supernatural is not an obvious market making product. This is part of the reason the lawsuit by the FTC might be seen as unusual or even strange.
However, Supernatural combined with a low cost mixed reality headset (like Oculus Quest 2) is a market making product.
Despite being cheesy, and rather low-rent in its production, the product is a breakthrough combination of gamified movement, immersive coaching and music.
It represents the biggest threat to Apple’s beachhead application for the new mixed reality product.
Apple Fitness, Apple Music, Apple watch and the new Apple mixed reality headset are primed and ready to deliver a product experience from the Reality OS App Store that Within could never afford.
However, Facebook (Meta) is prepared to provide bet-the-company resources and support because Within has already built a following in a niche that can crack open the entire fitness category.
Peloton is a tiny concept compared to what Supernatural could become under Meta.
Things happen fairly slowly, you know? They do. These waves of technology, you can see them way before they happen.
Steve Jobs, 2008
XR, VR, AR 2022 Pt. 1: Dragon’s Lair and Hologram Time Traveler 15 Sep 2022 11:40 PM (2 years ago)
The first 3D experience I remember was Sega’s 1991 LaserDisc interactive movie arcade game, Hologram Time Traveler at the Whistler Village arcade in the early 1990s.
Our family made annual spring break trips to Whistler back then and the village arcade was something I looked forward to every time.
I was too young to be interested in the village’s bar scene but old enough for my parents to let my older brother and me stay out as long as we wanted.
Most importantly the arcade had games I had never seen or heard of back at the Wunderland nickle arcades in Portland, Oregon.
As for Time Traveler, I only put coins in a few of times to play myself. It was really expensive (like either $1 or $1.50 per game which is something like like $30 in 2022!) so it meant not getting to try a lot of other great games.
It was also very difficult to get beyond the first couple levels of Time Traveler. You just kept dying as you failed to to memorize and execute the required control sequences.
To anyone else who experienced Time Traveler back then, it would come as no surprise that the same game designer also created the Dragon’s Lair series with Don Bluth.
Now Dragon’s Lair 2, was also at Whistler Arcade. (It was a fancy resort town) but that game was much more popular. In that game Lair you could seemingly play as a cartoon on a large television screen. It was unreal.
But even as a thirteen-year-old video game “enthusiast” these titles didn’t have the game play to hold up.
You could watch the attract mode enough loop and see the foibles of so many people and realize no matter how cool they looked the technology did not support much of anything beyond expensive novelty.
Any sense of immersion they might have offered fell away as the practical limitations of their game play were realized.
Thirty years later we are on the verge of the first major computing platform jump since the smartphone: Virtual Reality, (VR), Augmented Reality and Extended Reality (XR) experiences delivered in the first headsets with actual adoption.
I’ve been using an Oculus Quest 2 for several months now, and been tracking the open secrets framing Apple’s forthcoming headset release.
It is clear to me that XR/VR/AR is not like the expensive novelties of LaserDisc arcades but actually represents a major step in our potential.
Max Size of Django message Data in Cookie Storage 14 Sep 2021 1:46 PM (3 years ago)
I responded to a little challenge from Matt Layman of the Django Riffs podcast Episode 15, User Session Data.
Toward the end of the episode, Matt asked what might happen if over 4k worth of text was passed into messages if the backend storage method was cookies?
What I found was unexpected.
First, you can put way more than 4 kb worth of text into a messages message with a cookie backend and sail right on by. The actual max limit is much higher.
But more importantly, looking into this demonstrated exactly the point of the episode overall: diving into a framework can teach you a lot about what governs high level behavior.
I put a sample Django project up, over4kmessages along with my exploratory path on this topic on github. The README is as follows:
over4kmessages
This is a test project to demo Django’s behavior when large amounts of data are passed through the messages application.
Why
Episode 15 of Django Riffs podcast focuses on auth, which includes a detailed look at session.
Toward the end of the episode, Matt Layman (@mblayman) mentions a limit on the size of cookies and asks listeners to report what happens if too much message data is passed through.
How this test project works
In settings.py sets the MESSAGE_STORAGE setting to cookie storage, then the main view takes a trivial form POST and includes a very long string of text.
The contacts.const.py file contains increasingly large strings that are duplications of Charles Bukowski’s poem, “Style” These were created using this online text size calculator and verified by saving on disk.
The contacts.views.py file contains an easy way to toggle use any of these text blobs to messages. The project is by default set to use the 166 kb text.
Result
Increasingly large text blocks well beyond the believed 4k max were still allowed to pass through the cookie storage.
However, somewhere between 72kb and 166kb is too much text.
When the 166kb of text is passed as the message in contacts.views Django throws an exception:
Not all temporary messages could be stored.
This occurs in django.contrib.messages.middleware.py

Digging
It turns out django limits the max cookie size to 2048, in django.contrib.messages.storage.cooky.CookieStorage.
A comment in the code point out a decade old Django ticket #18781 which details a need to reduce the max cookie size from what was then 3072 created by django to make room for large headers.
This doesn’t explain why 72kb+ sized message would make it through a cookie. Perhaps, compression is involved here!
Searching contrib.messages.storage.cookie.py for ‘compress’ yields the _encode() method which passes message along and a compress=True argument to django.core.signing.Signer.sign_object.
sign_object() has a conditional for compress that shows the python standard library, zlib is being used.
That is what is allowing these larger messages to make it through.
New questions
- What is the true max text size that can be compressed using
zlib.compress()to duck the 2048 threshold for cookie
storage? - Should django still be using
zlib.compress()to pack data into cookies? - Really, if we’re passing a long a message to our user on page load, should it be longer than 140 chars anyway?
(Probably not but that’s the opposite of the point of all of this!)
A few more thoughts
After realizing some compression was being done, I wondered why Django chose zlib.compress and whether a faster, more efficient algorithm might exist. I have a few links I came across looking at this idea below.
However, what was more interesting was how deep you can go to find out how a web framework is designed and why. It pointed out a Django core method I wasn’t aware of, and touched on using the Python standard library to get something done.
I used Pycharm to jump into routines and pause the debugger where the exception occurred. A simple question can lead to a deep exploration if you’re willing to debug.
References for more on compression
- Writing a custom compression method to outperform
zlib.compress():
Don Cross, Winning the Data Compression Game - Question related to improving on
zlib.compress():
Stack Overflow, zlib compress() produces awful compression rate
Interspeech 2021 Conference Sessions, Speakers and Papers 29 Aug 2021 6:55 PM (3 years ago)
The UX for the Interspeech 2021 virtual conference platform could be more straightforward.
Here’s a quick list of sessions speakers and papers planned for the 9/30/21.
Microsoft
via: MSFTResearch site, see also @MSFTResearch
Tuesday, August 31, 2021
13:30 15:30
Improving Weakly Supervised Sound Event Detection with Self-Supervised Auxiliary Tasks Soham Deshmukh, Bhiksha Raj, Rita Singh
13:30 15:30
Explaining Deep Learning Models for Speech Enhancement Sunit Sivasankaran, Emmanuel Vincent, Dominique Fohr
13:30 15:30
Improving RNN-T for Domain Scaling Using Semi-Supervised Training with Neural TTS Yan Deng, Rui Zhao, Zhong Meng, Xie Chen, Bing Liu, Jinyu Li, Yifan Gong, Lei He
19:00 21:00
Data Augmentation for Spoken Language Understanding via Pretrained Language Models Baolin Peng, Chenguang Zhu, Michael Zeng, Jianfeng Gao
19:00 21:00
Rapid Speaker Adaptation for Conformer Transducer: Attention and Bias Are All You Need Yan Huang, Guoli Ye, Jinyu Li, Yifan Gong
19:00 21:00
One-Shot Voice Conversion with Speaker-Agnostic StarGAN Sefik Emre Eskimez, Dimitrios Dimitriadis, Kenichi Kumatani, Robert Gmyr
Wednesday, September 1, 2021
11:00 13:00
Multiple Softmax Architecture for Streaming Multilingual End-to-End ASR Systems Vikas Joshi, Amit Das, Eric Sun, Rupesh Mehta, Jinyu Li, Yifan Gong
11:00 13:00
Streaming Multi-Talker Speech Recognition with Joint Speaker Identification Liang Lu, Naoyuki Kanda, Jinyu Li, Yifan Gong
16:00 18:00
A Light-Weight Contextual Spelling Correction Model for Customizing Transducer-Based Speech Recognition Systems Xiaoqiang Wang, Yanqing Liu, Sheng Zhao, Jinyu Li
16:00 18:00
Subjective Evaluation of Noise Suppression Algorithms in Crowdsourcing Babak Naderi, Ross Cutler
19:00 21:00
MUCS 2021: Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages Anuj Diwan, Rakesh Vaideeswaran, Sanket Shah, Ankita Singh, Srinivasa Raghavan, Shreya Khare, Vinit Unni, Saurabh Vyas, Akash Rajpuria, Chiranjeevi Yarra, Ashish Mittal, Prasanta Kumar Ghosh, Preethi Jyothi, Kalika Bali, Vivek Seshadri, Sunayana Sitaram, Samarth Bharadwaj, Jai Nanavati, Raoul Nanavati, Karthik Sankaranarayanan, Tejaswi Seeram, Basil Abraham
19:00 21:00
Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition Zhong Meng, Yu Wu, Naoyuki Kanda, Liang Lu, Xie Chen, Guoli Ye, Eric Sun, Jinyu Li, Yifan Gong
19:00 21:00
Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement Sefik Emre Eskimez, Xiaofei Wang, Min Tang, Hemin Yang, Zirun Zhu, Zhuo Chen, Huaming Wang, Takuya Yoshioka
19:00 21:00Single-Channel Speech Enhancement Using Learnable Loss Mixup Oscar Chang, Dung N. Tran, Kazuhito Koishida
19:00 21:00
INTERSPEECH 2021 Deep Noise Suppression Challenge Chandan K A Reddy, Hari Dubey, Kazuhito Koishida, Arun Nair, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, Sriram Srinivasan
Thursday, September 2, 2021
11:00 13:00
Analyzing Short Term Dynamic Speech Features for Understanding Behavioral Traits of Children with Autism Spectrum Disorder Young-Kyung Kim, Rimita Lahiri, Md Nasir, So Hyun Kim, Somer Bishop, Catherine Lord, Shrikanth Narayanan
11:00 13:00Source Separation I
Related Publications
- Ultra Fast Speech Separation Model with Teacher Student Learning Sanyuan Chen, Yu Wu, Zhuo Chen, Jian Wu, Takuya Yoshioka, Shujie Liu, Jinyu Li, Xiangzhan Yu
- Investigation of Practical Aspects of Single Channel Speech Separation for ASR Jian Wu, Zhuo Chen, Sanyuan Chen, Yu Wu, Takuya Yoshioka, Naoyuki Kanda, Shujie Liu, Jinyu Li
- Continuous Speech Separation Using Speaker Inventory for Long Recording Cong Han, Yi Luo, Chenda Li, Tianyan Zhou, Keisuke Kinoshita, Shinji Watanabe, Marc Delcroix, Hakan Erdogan, John R. Hershey, Nima Mesgarani, Zhuo Chen
16:00 18:00Multi- and cross-lingual ASR, other topics in ASR
Related Publications
- Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching Wenxin Hou, Jindong Wang, Xu Tan, Tao Qin, Takahiro Shinozaki
- Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone Naoyuki Kanda, Guoli Ye, Yu Wu, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Zhuo Chen, Takuya Yoshioka
- On Minimum Word Error Rate Training of the Hybrid Autoregressive Transducer Liang Lu, Zhong Meng, Naoyuki Kanda, Jinyu Li, Yifan Gong
- Improving Multilingual Transformer Transducer Models by Reducing Language Confusions Eric Sun, Jinyu Li, Zhong Meng, Yu Wu, Jian Xue, Shujie Liu, Yifan Gong
16:00 18:00
Target-Speaker Voice Activity Detection with Improved i-Vector Estimation for Unknown Number of Speaker Maokui He, Desh Raj, Zili Huang, Jun Du, Zhuo Chen, Shinji Watanabe
16:00 18:00
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration Chuanxin Tang, Chong Luo, Zhiyuan Zhao, Dacheng Yin, Yucheng Zhao, Wenjun Zeng
16:00 18:00
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario Yihui Fu, Luyao Cheng, Shubo Lv, Yukai Jv, Yuxiang Kong, Zhuo Chen, Yanxin Hu, Lei Xie, Jian Wu, Hui Bu, Xin Xu, Jun Du, Jingdong Chen
Friday, September 3, 2021
11:00 13:00
Sequence-Level Confidence Classifier for ASR Utterance Accuracy and Application to Acoustic Models Amber Afshan, Kshitiz Kumar, Jian Wu
16:00 18:00
End-to-End Speaker-Attributed ASR with Transformer Naoyuki Kanda, Guoli Ye, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Zhuo Chen, Takuya Yoshioka
16:00 18:00
Speech Synthesis: Speaking Style and Emotion
Related Publications
- Adaptive Text to Speech for Spontaneous Style Yuzi Yan, Xu Tan, Bohan Li, Guangyan Zhang, Tao Qin, Sheng Zhao, Yuan Shen, Wei-Qiang Zhang, Tie-Yan Liu
- Cross-speaker Style Transfer with Prosody Bottleneck in Neural Speech Synthesis Shifeng Pan, Lei He
- Improving Performance of Seen and Unseen Speech Style Transfer in End-to-end Neural TTS Xiaochun An, Frank Soong, Lei Xie
16:00 18:00
INTERSPEECH 2021 Acoustic Echo Cancellation Challenge
Ross Cutler, Ando Saabas, Tanel Panarmaa, Markus Loide, Sten Sootla, Marju Purin, Hannes Gamper, Sebastian Braun, Robert Aichner, Sriram Srinivasan
Monday, September 6, 2021
Workshop 11:00 Workshop on Machine Learning in Speech and Language Processing 2021
Speaker: Chengyi Wang (Intern)
Organizing Committee: Yao Qian
Scientific Committee: Liang Lu
NVIDIA
via NVIDIA at INTERSPEECH 2021 site,
Tuesday, August 31, 2021
07:00 – 09:00 p.m. CET
Scene-Agnostic Multi-Microphone Speech Dereverberation
Yochai Yemini, Ethan Fetaya, Haggai Maron, Sharon Gannot
Wednesday, September 1, 2021
11:00 a.m. – 01:00 p.m. CET
SPGISpeech: 5,000 Hours of Transcribed Financial Audio for Fully Formatted End-to-End Speech Recognition
Patrick K. O’Neill, Vitaly Lavrukhin, Somshubra Majumdar, Vahid Noroozi, Yuekai Zhang, Oleksii Kuchaiev, Jagadeesh Balam, Yuliya Dovzhenko, Keenan Freyberg, Michael D. Shulman, Boris Ginsburg, Shinji Watanabe, Georg Kucsko
07:00 – 09:00 p.m. CET
Hi-Fi Multi-Speaker English TTS Dataset
Evelina Bakhturina, Vitaly Lavrukhin, Boris Ginsburg, Yang Zhang
Thursday, September 2nd, 2021
04:00 – 06:00 p.m. CET
TalklkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Stanislav Beliaev, Boris Ginsburg
Friday, September 3rd, 2021
04:00 – 06:00 p.m. CET
Compressing 1D Time-Channel Separable Convolutions Using Sparse Random Ternary Matrices
Gonçalo Mordido, Matthijs Van Keirsbilck, Alexander Keller
04:00 – 06:00 p.m. CET
NeMo Inverse Text Normalization: From Development To Production
Yang Zhang, Evelina Bakhturina, Kyle Gorman, Boris Ginsburg
Apple
Conference Accepted Papers
A Discriminative Entity Aware Language Model forAssistants
Mandana Saebi, Ernie Pusateri, Aaksha Meghawat, Christophe Van Gysel
Analysis and Tuning of a Voice Assistant System for Dysfluent Speech
Vikramjit Mitra, Zifang Huang, Colin Lea, Lauren Tooley, Panayiotis Georgiou, Sachin Kajarekar, Jefferey Bigham
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition inAssistants
Deepak Muralidharan, Joel Ruben Antony Moniz, Weicheng Zhang, Stephen Pulman, Lin Li, Megan Barnes, Jingjing Pan, Jason Williams, Alex Acero
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
Vineet Garg, Wonil Chang, Siddharth Sigtia, Saurabh Adya, Pramod Simha, Pranay Dighe, Chandra Dhir
Talks and Workshops
Meet Apple will be an opportunity to learn more about our ML teams, working at Apple, and how to apply to full-time positions. This talk will be held virtually on Wednesday, September 1 at 9:30 am PDT.
Apple is hosting a panel on internships, where attendees can learn more about internship opportunities across our machine learning teams. It will be held virtually on September 2 at 9:30 am PDT.
All registered Interspeech attendees are invited to each event. Check back for more information on how to join.
Affinity Events
Sunday August 29, 2021
Apple is a sponsor of the Workshop for Young Female Researchers in Speech Science & Technology which will take place virtually on Sunday, August 29.
Thursday, September 2nd, 2021
Matthias Paulik will be participating in the 8th Students Meet Experts event as a panelist. This event will take place virtually on Thursday, September 2.
Amazon
via Amazon Science
Accepted Publications
A learned conditional prior for the VAE acoustic space of a TTS system
Penny Karanasou, Sri Karlapati, Alexis Moinet, Arnaud Joly, Ammar Abbas, Simon Slangen, Jaime Lorenzo-Trueba, Thomas Drugman
Acted vs. improvised: Domain adaptation for elicitation approaches in audio-visual emotion recognition
Haoqi Li, Yelin Kim, Cheng-hao Kuo, Shrikanth Narayanan
Adapting long context NLM for ASR rescoring in conversational agents
Ashish Shenoy, Sravan Bodapati, Monica Sunkara, Srikanth Ronanki, Katrin Kirchhoff
Adjunct-emeritus distillation for semi-supervised language model adaptation
Scott Novotney, Yile Gu, Ivan Bulyko
Amortized neural networks for low-latency speech recognition
Jonathan Macoskey, Grant P. Strimel, Jinru Su, Ariya Rastrow
Best of both worlds: Robust accented speech recognition with adversarial transfer learning
Nilaksh Das, Sravan Bodapati, Monica Sunkara, Sundararajan Srinivasan, Duen Horng Chau
Manuel Giollo, Deniz Gunceler, Yulan Liu, Daniel Willett
CoDERT: Distilling encoder representations with co-learning for transducer-based speech recognition
Rupak Vignesh Swaminathan, Brian King, Grant P. Strimel, Jasha Droppo, Athanasios Mouchtaris
Correcting automated and manual speech transcription errors using warped language models
Mahdi Namazifar, John Malik, Erran Li, Gokhan Tur, Dilek Hakkani-Tür
Detection of lexical stress errors in non-native (L2) English with data augmentation and attention
Daniel Korzekwa, Roberto Barra-Chicote, Szymon Zaporowski, Grzegorz Beringer, Jaime Lorenzo-Trueba, Jasha Droppo, Thomas Drugman, Bozena Kostek
End-to-end neural diarization: From Transformer to Conformer
Yi Chieh Liu, Eunjung Han, Chul Lee, Andreas Stolcke
End-to-end spoken language understanding for generalized voice assistants
Michael Saxon, Samridhi Choudhary, Joseph McKenna, Athanasios Mouchtaris
Muhammad A. Shah, Joseph Szurley, Markus Mueller, Athanasios Mouchtaris
Event specific attention for polyphonic sound event detection
Harshavardhan Sundar, Ming Sun, Chao Wang
Factorization-aware training of transformers for natural language understanding on the edge
Hamidreza Saghir, Samridhi Choudhary, Sepehr Eghbali, Clement Chung
FANS: Fusing ASR and NLU for on-device SLU
Martin Radfar, Athanasios Mouchtaris, Siegfried Kunzmann, Ariya Rastrow
Ruirui Li, Chelsea J.-T. Ju, Zeya Chen, Hongda Mao, Oguz Elibol, Andreas Stolcke
Graph-based label propagation for semi-supervised speaker identification
Long Chen, Venkatesh Ravichandran, Andreas Stolcke
Improving multi-speaker TTS prosody variance with a residual encoder and normalizing flow
Iván Vallés-Pérez, Julian Roth, Grzegorz Beringer, Roberto Barra-Chicote, Jasha Droppo
Improving RNN-T ASR accuracy using context audio
Andreas Schwarz, Ilya Sklyar, Simon Wiesler
Improving the expressiveness of neural vocoding with non-affine normalizing flows
Adam Gabrys, Yunlong Jiao, Daniel Korzekwa, Roberto Barra-Chicote
Intra-sentential speaking rate control in neural text-to-speech for automatic dubbing
Mayank Sharma, Yogesh Virkar, Marcello Federico, Roberto Barra-Chicote, Robert Enyedi
Learning a neural diff for speech models Jonathan Macoskey, Grant P. Strimel, Ariya Rastrow
Leveraging ASR N-best in deep entity retrieval Haoyu Wang,
John Chen, Majid Laali, Jeff King, Kevin Durda, William M. Campbell, Yang Liu
Listen with intent: Improving speech recognition with audio-to-intent front-end
Swayambhu Nath Ray, Minhua Wu, Anirudh Raju, Pegah Ghahremani, Raghavendra Bilgi, Milind Rao, Harish Arsikere, Ariya Rastrow, Andreas Stolcke, Jasha Droppo
Lukas Drude, Jahn Heymann, Andreas Schwarz, Jean-Marc Valin
Multi-channel transformer transducer for speech recognition
Feng-Ju Chang, Martin Radfar, Athanasios Mouchtaris, Maurizio Omologo
Paraphrase label alignment for voice application retrieval in spoken language understanding
Zheng Gao, Radhika Arava, Qian Hu, Xibin Gao, Thahir Mohamed, Wei Xiao, Mohamed AbdelHady
Personalized PercepNet: Real-time, low-complexity target voice separation and enhancement
Ritwik Giri, Shrikant Venkataramani, Jean-Marc Valin, Umut Isik, Arvindh Krishnaswamy
Phonetically induced subwords for end-to-end speech recognition
Vasileios Papadourakis, Markus Mueller, Jing Liu, Athanasios Mouchtaris, Maurizio Omologo
Predicting temporal performance drop of deployed production spoken language understanding models
Quynh Ngoc Thi Do, Judith Gaspers, Daniil Sorokin, Patrick Lehnen
Scaling effect of self-supervised speech models
Jie Pu, Yuguang Yang, Ruirui Li, Oguz Elibol, Jasha Droppo
Scaling laws for acoustic models
SmallER: Scaling neural entity resolution for edge devices
Ross McGowan, Jinru Su, Vince DiCocco, Thejaswi Muniyappa, Grant P. Strimel
Speaker-conversation factorial designs for diarization error analysis
Scott Seyfarth, Sundararajan Srinivasan, Katrin Kirchhoff
SynthASR: Unlocking synthetic data for speech recognition
Amin Fazel, Wei Yang, Yulan Liu, Roberto Barra-Chicote, Yixiong Meng, Roland Maas, Jasha Droppo
The impact of intent distribution mismatch on semi-supervised spoken language understanding
Judith Gaspers, Quynh Ngoc Thi Do, Daniil Sorokin, Patrick Lehnen
Wav2vec-C: A self-supervised model for speech representation learning
Samik Sadhu, Di Hu, Che-Wei Huang, Sri Harish Mallidi, Minhua Wu, Ariya Rastrow, Andreas Stolcke, Jasha Droppo, Roland Maas
Weakly-supervised word-level pronunciation error detection in non-native English speech
The UX for the Interspeech 2021 virtual conference platform could be more straightforward.
Here’s a quick list of sessions speakers and papers planned for the 9/30/21, if you have some I’ve missed please email me rob@ this domain.
Microsoft
via: MSFTResearch site, see also @MSFTResearch
Tuesday, August 31, 2021
13:30 15:30
Improving Weakly Supervised Sound Event Detection with Self-Supervised Auxiliary Tasks Soham Deshmukh, Bhiksha Raj, Rita Singh
13:30 15:30
Explaining Deep Learning Models for Speech Enhancement Sunit Sivasankaran, Emmanuel Vincent, Dominique Fohr
13:30 15:30
Improving RNN-T for Domain Scaling Using Semi-Supervised Training with Neural TTS Yan Deng, Rui Zhao, Zhong Meng, Xie Chen, Bing Liu, Jinyu Li, Yifan Gong, Lei He
19:00 21:00
Data Augmentation for Spoken Language Understanding via Pretrained Language Models Baolin Peng, Chenguang Zhu, Michael Zeng, Jianfeng Gao
19:00 21:00
Rapid Speaker Adaptation for Conformer Transducer: Attention and Bias Are All You Need Yan Huang, Guoli Ye, Jinyu Li, Yifan Gong
19:00 21:00
One-Shot Voice Conversion with Speaker-Agnostic StarGAN Sefik Emre Eskimez, Dimitrios Dimitriadis, Kenichi Kumatani, Robert Gmyr
Wednesday, September 1, 2021
11:00 13:00
Multiple Softmax Architecture for Streaming Multilingual End-to-End ASR Systems Vikas Joshi, Amit Das, Eric Sun, Rupesh Mehta, Jinyu Li, Yifan Gong
11:00 13:00
Streaming Multi-Talker Speech Recognition with Joint Speaker Identification Liang Lu, Naoyuki Kanda, Jinyu Li, Yifan Gong
16:00 18:00
A Light-Weight Contextual Spelling Correction Model for Customizing Transducer-Based Speech Recognition Systems Xiaoqiang Wang, Yanqing Liu, Sheng Zhao, Jinyu Li
16:00 18:00
Subjective Evaluation of Noise Suppression Algorithms in Crowdsourcing Babak Naderi, Ross Cutler
19:00 21:00
MUCS 2021: Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages Anuj Diwan, Rakesh Vaideeswaran, Sanket Shah, Ankita Singh, Srinivasa Raghavan, Shreya Khare, Vinit Unni, Saurabh Vyas, Akash Rajpuria, Chiranjeevi Yarra, Ashish Mittal, Prasanta Kumar Ghosh, Preethi Jyothi, Kalika Bali, Vivek Seshadri, Sunayana Sitaram, Samarth Bharadwaj, Jai Nanavati, Raoul Nanavati, Karthik Sankaranarayanan, Tejaswi Seeram, Basil Abraham
19:00 21:00
Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition Zhong Meng, Yu Wu, Naoyuki Kanda, Liang Lu, Xie Chen, Guoli Ye, Eric Sun, Jinyu Li, Yifan Gong
19:00 21:00
Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement Sefik Emre Eskimez, Xiaofei Wang, Min Tang, Hemin Yang, Zirun Zhu, Zhuo Chen, Huaming Wang, Takuya Yoshioka
19:00 21:00Single-Channel Speech Enhancement Using Learnable Loss Mixup Oscar Chang, Dung N. Tran, Kazuhito Koishida
19:00 21:00
INTERSPEECH 2021 Deep Noise Suppression Challenge Chandan K A Reddy, Hari Dubey, Kazuhito Koishida, Arun Nair, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, Sriram Srinivasan
Thursday, September 2, 2021
11:00 13:00
Analyzing Short Term Dynamic Speech Features for Understanding Behavioral Traits of Children with Autism Spectrum Disorder Young-Kyung Kim, Rimita Lahiri, Md Nasir, So Hyun Kim, Somer Bishop, Catherine Lord, Shrikanth Narayanan
11:00 13:00Source Separation I
Related Publications
- Ultra Fast Speech Separation Model with Teacher Student Learning Sanyuan Chen, Yu Wu, Zhuo Chen, Jian Wu, Takuya Yoshioka, Shujie Liu, Jinyu Li, Xiangzhan Yu
- Investigation of Practical Aspects of Single Channel Speech Separation for ASR Jian Wu, Zhuo Chen, Sanyuan Chen, Yu Wu, Takuya Yoshioka, Naoyuki Kanda, Shujie Liu, Jinyu Li
- Continuous Speech Separation Using Speaker Inventory for Long Recording Cong Han, Yi Luo, Chenda Li, Tianyan Zhou, Keisuke Kinoshita, Shinji Watanabe, Marc Delcroix, Hakan Erdogan, John R. Hershey, Nima Mesgarani, Zhuo Chen
16:00 18:00Multi- and cross-lingual ASR, other topics in ASR
Related Publications
- Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching Wenxin Hou, Jindong Wang, Xu Tan, Tao Qin, Takahiro Shinozaki
- Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone Naoyuki Kanda, Guoli Ye, Yu Wu, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Zhuo Chen, Takuya Yoshioka
- On Minimum Word Error Rate Training of the Hybrid Autoregressive Transducer Liang Lu, Zhong Meng, Naoyuki Kanda, Jinyu Li, Yifan Gong
- Improving Multilingual Transformer Transducer Models by Reducing Language Confusions Eric Sun, Jinyu Li, Zhong Meng, Yu Wu, Jian Xue, Shujie Liu, Yifan Gong
16:00 18:00
Target-Speaker Voice Activity Detection with Improved i-Vector Estimation for Unknown Number of Speaker Maokui He, Desh Raj, Zili Huang, Jun Du, Zhuo Chen, Shinji Watanabe
16:00 18:00
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration Chuanxin Tang, Chong Luo, Zhiyuan Zhao, Dacheng Yin, Yucheng Zhao, Wenjun Zeng
16:00 18:00
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario Yihui Fu, Luyao Cheng, Shubo Lv, Yukai Jv, Yuxiang Kong, Zhuo Chen, Yanxin Hu, Lei Xie, Jian Wu, Hui Bu, Xin Xu, Jun Du, Jingdong Chen
Friday, September 3, 2021
11:00 13:00
Sequence-Level Confidence Classifier for ASR Utterance Accuracy and Application to Acoustic Models Amber Afshan, Kshitiz Kumar, Jian Wu
16:00 18:00
End-to-End Speaker-Attributed ASR with Transformer Naoyuki Kanda, Guoli Ye, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Zhuo Chen, Takuya Yoshioka
16:00 18:00
Speech Synthesis: Speaking Style and Emotion
Related Publications
- Adaptive Text to Speech for Spontaneous Style Yuzi Yan, Xu Tan, Bohan Li, Guangyan Zhang, Tao Qin, Sheng Zhao, Yuan Shen, Wei-Qiang Zhang, Tie-Yan Liu
- Cross-speaker Style Transfer with Prosody Bottleneck in Neural Speech Synthesis Shifeng Pan, Lei He
- Improving Performance of Seen and Unseen Speech Style Transfer in End-to-end Neural TTS Xiaochun An, Frank Soong, Lei Xie
16:00 18:00
INTERSPEECH 2021 Acoustic Echo Cancellation Challenge
Ross Cutler, Ando Saabas, Tanel Panarmaa, Markus Loide, Sten Sootla, Marju Purin, Hannes Gamper, Sebastian Braun, Robert Aichner, Sriram Srinivasan
Monday, September 6, 2021
Workshop 11:00 Workshop on Machine Learning in Speech and Language Processing 2021
Speaker: Chengyi Wang (Intern)
Organizing Committee: Yao Qian
Scientific Committee: Liang Lu
NVIDIA
via NVIDIA at INTERSPEECH 2021 site,
Tuesday, August 31, 2021
07:00 – 09:00 p.m. CET
Scene-Agnostic Multi-Microphone Speech Dereverberation
Yochai Yemini, Ethan Fetaya, Haggai Maron, Sharon Gannot
Wednesday, September 1, 2021
11:00 a.m. – 01:00 p.m. CET
SPGISpeech: 5,000 Hours of Transcribed Financial Audio for Fully Formatted End-to-End Speech Recognition
Patrick K. O’Neill, Vitaly Lavrukhin, Somshubra Majumdar, Vahid Noroozi, Yuekai Zhang, Oleksii Kuchaiev, Jagadeesh Balam, Yuliya Dovzhenko, Keenan Freyberg, Michael D. Shulman, Boris Ginsburg, Shinji Watanabe, Georg Kucsko
07:00 – 09:00 p.m. CET
Hi-Fi Multi-Speaker English TTS Dataset
Evelina Bakhturina, Vitaly Lavrukhin, Boris Ginsburg, Yang Zhang
Thursday, September 2nd, 2021
04:00 – 06:00 p.m. CET
TalklkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Stanislav Beliaev, Boris Ginsburg
Friday, September 3rd, 2021
04:00 – 06:00 p.m. CET
Compressing 1D Time-Channel Separable Convolutions Using Sparse Random Ternary Matrices
Gonçalo Mordido, Matthijs Van Keirsbilck, Alexander Keller
04:00 – 06:00 p.m. CET
NeMo Inverse Text Normalization: From Development To Production
Yang Zhang, Evelina Bakhturina, Kyle Gorman, Boris Ginsburg
Apple
Conference Accepted Papers
A Discriminative Entity Aware Language Model forAssistantsMandana Saebi, Ernie Pusateri, Aaksha Meghawat, Christophe Van Gysel
Analysis and Tuning of a Voice Assistant System for Dysfluent SpeechVikramjit Mitra, Zifang Huang, Colin Lea, Lauren Tooley, Panayiotis Georgiou, Sachin Kajarekar, Jefferey Bigham
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition inAssistantsDeepak Muralidharan, Joel Ruben Antony Moniz, Weicheng Zhang, Stephen Pulman, Lin Li, Megan Barnes, Jingjing Pan, Jason Williams, Alex Acero
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger MitigationVineet Garg, Wonil Chang, Siddharth Sigtia, Saurabh Adya, Pramod Simha, Pranay Dighe, Chandra Dhir
Talks and Workshops
Meet Apple will be an opportunity to learn more about our ML teams, working at Apple, and how to apply to full-time positions. This talk will be held virtually on Wednesday, September 1 at 9:30 am PDT.
Apple is hosting a panel on internships, where attendees can learn more about internship opportunities across our machine learning teams. It will be held virtually on September 2 at 9:30 am PDT.
All registered Interspeech attendees are invited to each event. Check back for more information on how to join.
Affinity Events
Sunday August 29, 2021
Apple is a sponsor of the Workshop for Young Female Researchers in Speech Science & Technology which will take place virtually on Sunday, August 29.
Thursday, September 2nd, 2021
Matthias Paulik will be participating in the 8th Students Meet Experts event as a panelist. This event will take place virtually on Thursday, September 2.
Amazon
via Amazon Science
Accepted Publications
A learned conditional prior for the VAE acoustic space of a TTS system
Penny Karanasou, Sri Karlapati, Alexis Moinet, Arnaud Joly, Ammar Abbas, Simon Slangen, Jaime Lorenzo-Trueba, Thomas Drugman
Acted vs. improvised: Domain adaptation for elicitation approaches in audio-visual emotion recognition
Haoqi Li, Yelin Kim, Cheng-hao Kuo, Shrikanth Narayanan
Adapting long context NLM for ASR rescoring in conversational agents
Ashish Shenoy, Sravan Bodapati, Monica Sunkara, Srikanth Ronanki, Katrin Kirchhoff
Adjunct-emeritus distillation for semi-supervised language model adaptation
Scott Novotney, Yile Gu, Ivan Bulyko
Amortized neural networks for low-latency speech recognition
Jonathan Macoskey, Grant P. Strimel, Jinru Su, Ariya Rastrow
Best of both worlds: Robust accented speech recognition with adversarial transfer learning
Nilaksh Das, Sravan Bodapati, Monica Sunkara, Sundararajan Srinivasan, Duen Horng Chau
Manuel Giollo, Deniz Gunceler, Yulan Liu, Daniel Willett
CoDERT: Distilling encoder representations with co-learning for transducer-based speech recognition
Rupak Vignesh Swaminathan, Brian King, Grant P. Strimel, Jasha Droppo, Athanasios Mouchtaris
Correcting automated and manual speech transcription errors using warped language models
Mahdi Namazifar, John Malik, Erran Li, Gokhan Tur, Dilek Hakkani-Tür
Detection of lexical stress errors in non-native (L2) English with data augmentation and attention
Daniel Korzekwa, Roberto Barra-Chicote, Szymon Zaporowski, Grzegorz Beringer, Jaime Lorenzo-Trueba, Jasha Droppo, Thomas Drugman, Bozena Kostek
End-to-end neural diarization: From Transformer to Conformer
Yi Chieh Liu, Eunjung Han, Chul Lee, Andreas Stolcke
End-to-end spoken language understanding for generalized voice assistants
Michael Saxon, Samridhi Choudhary, Joseph McKenna, Athanasios Mouchtaris
Muhammad A. Shah, Joseph Szurley, Markus Mueller, Athanasios Mouchtaris
Event specific attention for polyphonic sound event detection
Harshavardhan Sundar, Ming Sun, Chao Wang
Factorization-aware training of transformers for natural language understanding on the edge
Hamidreza Saghir, Samridhi Choudhary, Sepehr Eghbali, Clement Chung
FANS: Fusing ASR and NLU for on-device SLU
Martin Radfar, Athanasios Mouchtaris, Siegfried Kunzmann, Ariya Rastrow
Ruirui Li, Chelsea J.-T. Ju, Zeya Chen, Hongda Mao, Oguz Elibol, Andreas Stolcke
Graph-based label propagation for semi-supervised speaker identification
Long Chen, Venkatesh Ravichandran, Andreas Stolcke
Improving multi-speaker TTS prosody variance with a residual encoder and normalizing flow
Iván Vallés-Pérez, Julian Roth, Grzegorz Beringer, Roberto Barra-Chicote, Jasha Droppo
Improving RNN-T ASR accuracy using context audio
Andreas Schwarz, Ilya Sklyar, Simon Wiesler
Improving the expressiveness of neural vocoding with non-affine normalizing flows
Adam Gabrys, Yunlong Jiao, Daniel Korzekwa, Roberto Barra-Chicote
Intra-sentential speaking rate control in neural text-to-speech for automatic dubbing
Mayank Sharma, Yogesh Virkar, Marcello Federico, Roberto Barra-Chicote, Robert Enyedi
Learning a neural diff for speech models Jonathan Macoskey, Grant P. Strimel, Ariya Rastrow
Leveraging ASR N-best in deep entity retrieval Haoyu Wang,
John Chen, Majid Laali, Jeff King, Kevin Durda, William M. Campbell, Yang Liu
Listen with intent: Improving speech recognition with audio-to-intent front-end
Swayambhu Nath Ray, Minhua Wu, Anirudh Raju, Pegah Ghahremani, Raghavendra Bilgi, Milind Rao, Harish Arsikere, Ariya Rastrow, Andreas Stolcke, Jasha Droppo
Lukas Drude, Jahn Heymann, Andreas Schwarz, Jean-Marc Valin
Multi-channel transformer transducer for speech recognition
Feng-Ju Chang, Martin Radfar, Athanasios Mouchtaris, Maurizio Omologo
Paraphrase label alignment for voice application retrieval in spoken language understanding
Zheng Gao, Radhika Arava, Qian Hu, Xibin Gao, Thahir Mohamed, Wei Xiao, Mohamed AbdelHady
Personalized PercepNet: Real-time, low-complexity target voice separation and enhancement
Ritwik Giri, Shrikant Venkataramani, Jean-Marc Valin, Umut Isik, Arvindh Krishnaswamy
Phonetically induced subwords for end-to-end speech recognition
Vasileios Papadourakis, Markus Mueller, Jing Liu, Athanasios Mouchtaris, Maurizio Omologo
Predicting temporal performance drop of deployed production spoken language understanding models
Quynh Ngoc Thi Do, Judith Gaspers, Daniil Sorokin, Patrick Lehnen
Scaling effect of self-supervised speech models
Jie Pu, Yuguang Yang, Ruirui Li, Oguz Elibol, Jasha Droppo
Scaling laws for acoustic models
SmallER: Scaling neural entity resolution for edge devices
Ross McGowan, Jinru Su, Vince DiCocco, Thejaswi Muniyappa, Grant P. Strimel
Speaker-conversation factorial designs for diarization error analysis
Scott Seyfarth, Sundararajan Srinivasan, Katrin Kirchhoff
SynthASR: Unlocking synthetic data for speech recognition
Amin Fazel, Wei Yang, Yulan Liu, Roberto Barra-Chicote, Yixiong Meng, Roland Maas, Jasha Droppo
The impact of intent distribution mismatch on semi-supervised spoken language understanding
Judith Gaspers, Quynh Ngoc Thi Do, Daniil Sorokin, Patrick Lehnen
Wav2vec-C: A self-supervised model for speech representation learning
Samik Sadhu, Di Hu, Che-Wei Huang, Sri Harish Mallidi, Minhua Wu, Ariya Rastrow, Andreas Stolcke, Jasha Droppo, Roland Maas
Weakly-supervised word-level pronunciation error detection in non-native English speech
Daniel Korzekwa, Jaime Lorenzo-Trueba, Thomas Drugman, Shira Calamaro, Bozena Kostek
Visit the Amazon Science page for more info on eight workshops by Amazon.
- ByteDance ?
- Facebook ?
- Google ?
- Phonexia ?
- 3M ?
- Baidu ?
- Human Language Technology (Johns Hopkins) ?
- IBM?
wp:paragraph –>
Daniel Korzekwa, Jaime Lorenzo-Trueba, Thomas Drugman, Shira Calamaro, Bozena Kostek
Visit the Amazon Science page for more info on eight workshops by Amazon.
- ByteDance ?
- Facebook ?
- Google ?
- Phonexia ?
- 3M ?
- Baidu ?
- Human Language Technology (Johns Hopkins) ?
- IBM?
Apple Spatial Audio 25 Feb 2021 9:39 AM (4 years ago)
People are sleeping on Apple Spatial Audio.
The mistake is thinking that audio channel technology such as 5.1, 7.1 surround sound can be separated from the audio delivery hardware technology.
Olivia Tambini has a recent piece focused on audio technology products including Sony 360 Reality Audio and Dolby Atmos.
As Olivia mentions, a company like Sony is going to have to not only sell hardware that plays Reality Audio, the company will have to convince media producers to use the branded format and then distributors to offer support for it in their apps.
That plan seems unlikely to succeed. The better bet would be to try and be the premier partner of Samsung Android phones, which is a pretty weak play compared to the audience they’ll give up on iOS.
Speaking of iOS and Apple, Spatial Audio has to be delivered using CMHeadphoneMotionManager. And you’ll need Airpods Pro or Airpods Max and an iPhone or iPad running iOS 14+ to hear it.
Some of my most tech forward pals have yet to even experience Apple Spatial Audio even though they have the equipment needed to play it back. So, early days still.
Interestingly, Final Cut Pro X has literally no mention of Spatial Audio in its help documents. It is as though the technology doesn’t exist. I found an example of filmmaker Gary Yost, a serious OG of 3D everything who managed to map spatial audio into Final Cut Pro back in 2018. I love this quote in that blog entry:
“Audio is as important as video, people!”
Gary Yost
3D OG
Big film and game productions are already mixing audio for the tech though. Sound Particles seems to be the premier software solution, advertising some huge films that have used their tool to mix (program?) spherical audio.
Yet while there seems to be plenty of traditional media ready for this, traditional films can’t possibly offer the immersion expected from spatial audio because the viewer is never in the scene. We’re observers of scenes from constantly shifting vantage points.
In that way, Apple’s head tracking technology, which is undoubtedly part of a future AR platform almost points away from the way media was, or rather is:
There’s a recent interview with Joel Douek discussing “Spatial Audio and Immersive Content” on the 2nd Level Podcast. Notably, the podcast plays back in the same way as all others.
It isn’t that the production of audio that is not mixed for spatiality is wrong. Nor is it wrong to be lacking a device capable of playing back spatial audio with head tracking.
But I suspect we’ll see audio production from today the way we see 480i SD video or that square stuff of 80s and 90s TV.
Given there is a huge amount of amazing audio, I wonder what remasterings for spatial audio will look like. They can change the art dramatically.
David Simon’s blog entry on HBO’s “remastering” of The Wire speaks some to how important it is that content creators retain creative control over their work.
Can the remaining Beatles remaster Sgt. Peppers Lonely Hearts Club Band for spherical, 3d audio? Would Lennon have put himself on the left side? Does the French horn quartet over the bridge play in a group over to the right or are they surprisingly up on a balcony behind us?
Who has the authority to make decisions about how Purple Rain’s intro should be mapped into a 3d space? And how mad would Prince have been that anyone was even considering doing such a thing.
Edit: My brother Ryan pointed out that Sgt. Peppers has already been remixed for 3D audio, in part through the Cirque du Soleil “Love” production.
A trivial amount of searching reveals that the 50th anniversary editions of Sgt. Peppers and Abbey Road include 5.1 audio. The official page suggests that Dolby Atmos mixes were created by Giles Martin and Max Okell:
The anxiety from fans was perhaps that Martin could have gotten trigger-happy and experimented a little too much with the mix. There is a great balance struck on this master, with plenty of subtlety in the use of the Dolby Atmos 5.1 mix.
Giles Martin even spoke of some of the adjustments he had to make to stay relatively true to the original recordings; “Now, modern-day recordings, they have all drums in the center, because they sound stronger. And actually we did that with “Come Together,” and then we realized it that it didn’t sound as good. The drums need to be slightly to one side — they need to be slightly off-kilter, if you like — in order to make it sound cool.”
Abbey Road – 50th Anniversary 5.1 Mix – Giles Martin, By Ben Jacklin
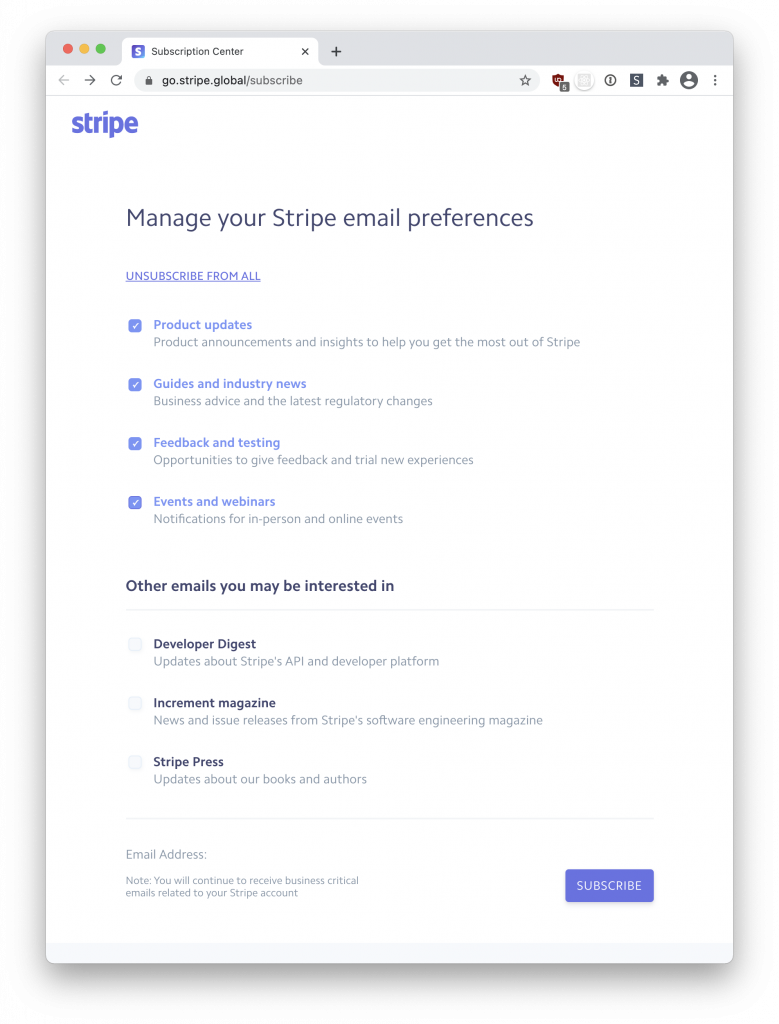
Stripe’s Okay Email Unsubscribe UX 8 Feb 2021 11:01 AM (4 years ago)
Stripe has a nice user experience for unsubscribing from their marketing and onboarding emails. This is called “Manage your Stripe email preferences”
The Good
Unsubscribe from all
There are subject specific choices, with a single “unsubscribe from all” link at the top. Clicking unsubscribe from all does not require a second click, it just submits the form.
Other emails you may be interested in
Offer up stuff normal users don’t get subscribed to alongside anything that came auto-opt-in with the signup.
Reminder about “business critical emails”
Unsubscribing from a company’s emails doesn’t mean you won’t hear from them. Its good to remind users that this is the case. That said, some companies abuse this by sneaking marketing into account emails.
Clear and simple design
Many companies choose to make email preferences pages look terrible. It is a mistake to do this when this is a touch point where your customer is considering how much of a relationship they want with your company.
Ways to Improve
Acknowledge user actions
Offer better visual feedback resulting from user interaction with the page.
Offer direct link in emails that unsubs from list type
One click to this page saying you’ve been successful with the unsubscribe and “here are the rest of the settings you can also change.”
Ask on any auto-opt-in
Canada requires this with CASL but US companies should get explicit permission to mail due to a sign up event. In this case, I have used stripe many times and don’t want any email on a new account.
Email frequency or triggers
Set expectations for users on how often these arrive or what causes them to be sent.
The Fundamental Dishonesty of Facebook 16 Dec 2020 10:50 AM (4 years ago)
Apple will soon be showing a pop-up in the Facebook app that it requires permission to track you across apps and websites and Facebook is not happy about it.
In a blog post today, “Speaking Up for Small Businesses,” Dan Levy, VP of Ads posted a video trotting out small business owners to defend Facebook’s use of advertising and a list bullet points about why Apple should not remind users that Facebook tracks you everywhere you go on the internet.
A point Facebook makes in their blog post is this:
“It will force businesses to turn to subscriptions and other in-app payments for revenue, meaning Apple will profit and many free services will have to start charging or exit the market.”
“Speaking Up for Small Businesses” Facebook Newsroom 12/16/2020
This is fundamental dishonesty by Mark Zuckerberg and the executive team at Facebook.
The product “Facebook” and its relative, Instagram are not free. They come with the cost of an intrusive violation of privacy that is opaque or misunderstood by their users.
Facebook’s harm isn’t just selling access to you based on demographic and personal interests, it includes research Facebook does to trigger you into more engagement that will cause more ad viewing.
Facebook’s need to trigger engagement was a major factor in the rise of QAnon.
“Free” services are a falsehood. Businesses should charge so they do not fall into the trap of generating increasingly triggering content and user experiences that are neither healthy nor desired by “users.”
If your product is good enough, people will pay for a pro version. We know this from products like Spotify.
It is Facebook’s fault that it will not provide a pro version of its own product because the most valuable users will no longer be available to advertisers which will greatly undermine the profit it makes from tracking-based advertising.
More simply, the most valuable people don’t want to be tracked and they are more valuable to sell to advertisers than Facebook could charge for a subsription.
Facebook is mad that Apple is pointing in this direction when they continue to use the Facebook, Instagram or its other associated enterprises.
Despite its technical excellence and open source contributions, Facebook has a putrid business model that stains the entire company.
Both Facebook’s leadership and its shareholders deserve to lose for their continued support and enablement of this horrendous blight on the internet.