We’ve moved! Come see our new home! 5 Aug 2018 11:00 PM (6 years ago)
Ten years, three months and 30 days ago, we wrote our first post on this blog, and now, we’re writing our last at this particular web address. Today, it’s with great excitement that we present to you the Google Cloud blog, your home for all the latest GCP product news, how-to’s, perspectives and customer stories that you’re used to, all living happily on a shiny, new mobile-friendly platform.

We’re really excited about this change. Not only does the new blog look really nice, but it includes all the content from across the entire Google Cloud family—GCP, G Suite, Google Maps Platform and Chrome Enterprise—so you can see how they all fit together. And because data analysis and artificial intelligence are so central to everything people are building today, we’ve also folded our Big Data and Machine Learning blog into this new platform.
Besides collecting all Google Cloud blog content in one place, we think you’ll really benefit from the blog’s rich tagging capabilities. Now, you can view blog posts by platform, and also drill down to specific technology areas like Application Development, Networking or Open Source, so you can quickly find related content. There are also dedicated pages for partners, customers, trainings and certifications, and solutions and how-to’s, to name a few. And because we can also tag posts to multiple products and topics, you’ll be sure to find what you’re looking for.
Those are just the high-level changes. There are a whole lot of new features to use and explore, and we encourage you to browse the site and get familiar with it. What’s not new is our mission: to provide you with honest, technical content to show you how to build your business on GCP.
To date, we’ve migrated over two year’s worth of GCP blog posts to this new home, with more to come. Let us know if you find any broken links, typos, or just flat-out missing content. And of course, we’d love your feedback on our content, the design, or any features you’d like to see. Thanks for reading!










Last month today: July on GCP 3 Aug 2018 6:00 AM (6 years ago)
The month of July saw our Google Cloud Next ‘18 conference come and go, and there was plenty of exciting news, updates and demos to share from the show. Here’s a look at some of the most-read blog posts from July.
What caught your attention this month: Creating the open cloud
- One of the most-read posts this month covered the launch of our Cloud Services Platform, which allows you to build a true hybrid cloud infrastructure. Some of the key components of Cloud Services Platform include the managed Istio service mesh, Google Kubernetes Engine (GKE) On-Prem and GKE Policy Management, Cloud Build for fully managed CI/CD, and several serverless offerings (more on that below). Combined, these technologies can help you gain consistency, security, speed and flexibility of the cloud in your local data center, along with the freedom of workload portability to the environment of your choice.
- Another popular read was a rundown of Google Cloud’s new serverless offerings. These include core serverless compute announcements such as new App Engine runtimes, Cloud Functions general availability and more. It also included serverless containers, so you can run serverless workloads in a fully managed container environment; GKE Serverless add-on to easily run serverless workloads on Kubernetes Engine; and Knative, the open-source project on which that add-on is built. There are even more features included in this post, too, like Cloud Build, Stackdriver monitoring and Cloud Firestore integration with GCP.
- Another must-read post this month for many of you was Transparent SLIs: See Google Cloud the way your application experiences it, announcing the availability of detailed data insights on GCP services that your workloads use—helping you see like a Google site reliability engineer (SRE). These new service-level indicators (SLIs) go way beyond basic uptime and downtime to delve into response codes, latency and more. You can then separate out metrics by GCP service to see things like API version, location and protocol. The result is that you can filter and sort to get extremely fine-grained information on your software and the GCP services you use, which helps cut resolution times and improve the support experience. Transparent SLIs are available now through the Stackdriver monitoring console. Learn more here about the basics of using SLIs and other SRE tools to measure and manage availability.
- It’s also now faster and easier to find production-ready commercial Kubernetes apps in the GCP Marketplace. These apps are prepackaged and configured to get up and running easily, whether on Kubernetes Engine or other Kubernetes clusters, and run the gamut from security, data analytics and developer tools to storage, machine learning and monitoring.
- For all of you developing cloud apps with Java, the availability of Jib was an exciting announcement last month. This open-source container image builder, available as Gradle and Maven plugins, cuts out several steps from the Docker build flow. Jib does all the work required to package your app into a container image—you don’t need to write a Dockerfile or even have Docker installed. You end up with faster builds and reproducible container images.
- And on that topic, this best practices for building containers post was a hit, too, giving you tips that will set you up to run your environment more smoothly. The tips in this blog post cover graceful application shutdowns, how to simplify containers and how to choose and tag the container images you’ll use.

Repairing network hardware at scale with SRE principles 1 Aug 2018 6:00 AM (6 years ago)
By James O’Keeffe, Senior Site Reliability Engineer
To support our Google Cloud Platform (GCP) customers, we run a complex global network that depends on multiple providers and a lot of hardware. Google network engineering uses a diverse set of vendor equipment to route user traffic from an internet service provider to one of our serving front ends inside a GCP data center. This equipment is proprietary and made by external networking vendors such as Arista, Cisco and Juniper. Each vendor has distinct operational methods, configurations and operational consoles.
With hundreds of distinct components utilized across our global network, we routinely deal with hardware failures—for example, a failed power supply, line card or control plane card. The complexity of today’s cloud networks means that there are a huge number of places where failure can occur. When we first began building and operating our own data centers, Google had a team of engineers, network engineers and site reliability engineers (SREs) who performed fault detection, mitigation and repair work on these devices, using manual processes guided by a ticket system. Google’s SRE principles are prescriptive, and aim to guide developers and operations teams toward better systems reliability. As with DevOps, avoiding toil—the manual tasks that can eat up too much time—is an essential goal.
We realized after becoming familiar with common hardware problems that any ticket type that we encountered repeatedly and that follows a predetermined sequence of steps can easily be automated. Our team created a list of playbooks over time that detailed steps of how to deal with each hardware failure scenario, taking into account relevant software and hardware bugs and typical steps to resolution. Each playbook is used when an alert is received. Given that we already knew in advance how to deal with each issue as it arose, it made sense to automate the work. Here’s how we did it.
Building the automation interface
“In the old way of doing things, we treat our servers like pets, for example, Bob the mail server. If Bob goes down, it’s all hands on deck. The CEO can’t get his email and it’s the end of the world. In the new way, servers are numbered, like cattle in a herd. For example, www001 to www100. When one server goes down, it’s taken out back, shot, and replaced on the line.”
- Randy Bias
The above quote describes a classic engineering scenario often applied within SRE: "Pets vs. cattle," which describes a way of looking at data center hardware as either individual components or a herd of them. The two categories of equipment can be described as follows:
Pet:
- An individual device you work on. You're familiar with all of its particular failure modes.
- When it gets sick, you come to the rescue.
Cattle:
- A fleet of devices with a common interface.
- You manage the "herd" of devices as a group.
- The common interface lets you perform the same basic operations on any device, regardless of its manufacturer.
type Linecard interface {
Online() error
Offline() error
Status() error
}
We then realized that we could apply the same interface to many hardware components—for example, a fan. For certain vendors, the Online() and Offline() functions did nothing, because those vendors didn't support turning a fan off, so we just used the interface to check the status.
type Fan interface {
Online() error
Offline() error
Status() error
}
type Component interface {
Online() error
Offline() error
Status() error
}
Deciding what to automate
The system needed to interact with humans at various stages of the automation. To decide what to automate, we drew a flow chart of the normal human-based repair sequence and drew boxes around stages we believed we could replace with automation. We used the task of replacing a vendor control plane board as an example. Many of the steps have self-explanatory names, but these are definitions of some of the more complex ones:- Determine control plane: Find faulty control plane unit.
- Determine state: Is it the master or the backup?
- Copy image to control plane: Copy the appropriate software image to the master control plane.
- Offline control plane: Send the backup control plane offline.
- Toggle mastership: Make the replaced control plane the new master.
 |
| Figure 1: Manual workflow for replacing a vendor control plane board |
 |
| Figure 2: Automated workflow for replacing a vendor control plane board |
 |
| Figure 3: High-level system view. |
On the day of the operation:
- The data center technician would click “start” on the change management system to begin the repair.
- Our system picks up this change and is ready to begin the repair.
- The technician clicks “start” on our UI.
- An “offline” state machine starts proceeding through the various steps to take the component offline safely.
- The UI notifies the user each step of the way.
- Once the state machine has completed, it notifies the technician, who can safely replace the component.
- Once the component is replaced and re-cabled, the technician returns to the UI and begins the “online” state machine, which safely returns the component into production.
Automation lessons learned

Tips for reducing toil through automation
- Measure your toil.
- Tackle the biggest sources of toil first, and don't try to solve all problems at once.
- Carefully consider whether to enhance existing tools or build new ones. Even if you can partially repurpose another team's work, would creating a tool from scratch actually make more sense cost- or resource-wise?
- Take a design-driven approach. Iterate on the design, starting small and iterating quickly. Don't try to design the perfect approach from the start.
- Measure your time savings to determine your return on investment.
Istio reaches 1.0: ready for prod 31 Jul 2018 8:00 AM (6 years ago)
By Dan Ciruli, Product Manager
Today, Google Cloud is proud to announce, together with our collaborators, that the Istio open-source project has reached the 1.0 milestone. This is a key step toward delivering the Cloud Services Platform that we discussed last week, helping you manage your services in a hybrid world where some of your infrastructure runs on VMs and some in Kubernetes, some services run in the cloud and some on-premises.
Istio: a service mesh
Istio is at its heart a service mesh—software that layers transparently onto an existing distributed application. It collects logs, traces and telemetry, and adds security and policy without embedding client libraries. Moreover, Istio is also a platform, complete with APIs that let you integrate with systems for logging, telemetry and policy.Istio delivers a service-based view of the service interactions across the mesh. Whereas traditional monitoring gives you low-level metrics such as nodes’ CPU consumption, Istio measures the actual traffic between services: requests per second, error rates and latency. It also generates a dependency graph so you can see how services affect one another.
With Istio, your DevOps team gets the tools it needs to run distributed apps smoothly. Istio does canary rollouts, letting you smoke-test a new build to make sure it’s performing well before ramping up. It also offers fault-injection, retry logic and circuit breaking so DevOps teams can do more testing and change network behavior at runtime to keep applications up and running.
And finally, Istio adds security. It can be used to layer mTLS on every call, adding encryption-in-flight and giving you the ability to authorize every single call on your cluster and in your mesh.
Istio in action
Istio provides foundational capabilities for your infrastructure, freeing developers to work on code that is critical to your business. But there’s only one way to prove that Istio is ready for the enterprise: by running real workloads on it in production. Already, there are at least a dozen companies running Istio in production, including several on GCP. We worked with them through early hurdles, incorporated their feedback, and they’re reaping the benefits of Istio already. A great example is Auto Trader UK, which used Istio to help accelerate their move to containers and the public cloud.Auto Trader UK is not only migrating from private cloud to public cloud, but also moving from virtual machines to Kubernetes. The level of control and visibility that Istio provides has enabled us to significantly de-risk this ambitious work, and in several cases has actually helped surface issues we were previously unaware of. We've been able to accelerate the delivery of capabilities such as mutual TLS, that previously would have taken significant engineering effort, allowing us to focus on our market differentiators.
- Karl Stoney, Delivery Infrastructure Lead, Auto Trader UK
A true joint effort
We first released Istio as open source last year, and what a year it’s been. Since that first 0.1 release, Istio has improved and matured significantly, with eight versions, 200+ contributors, and 4,000+ check-ins adding an ever growing set of functionality.Getting to version 1.0 was truly a community-driven effort. IBM was a key collaborator and co-founder, and Lyft’s Envoy proxy is a key component of the project. Since then, the number of companies involved in Istio has skyrocketed, including Cisco, Red Hat, and VMware consolidating industry support with the goal of accelerating adoption and meeting the service mesh needs of their customers.
“The growth of Istio since its launch last year has been tremendous, and it’s quickly taking its place as the standard way to manage microservices in the cloud,” said Jason McGee, IBM Fellow and VP, IBM Cloud. “Our mission since Istio’s launch has been to enable everyone to succeed with microservices, especially in the enterprise. This is why we’ve focused the community around improving security and scale, and heavily leaned our contributions on what we’ve learned from building agile cloud architectures for companies of all sizes.”
- Jason McGee, IBM Fellow and VP, IBM Cloud
"We see Istio's potential to be able to solve some of the most complex aspects of application development and deployment. It brings a control plane for service mesh, cluster orchestration, and network control that will support and enable developers to focus on the more important aspects of their application development. We are looking forward to leveraging Istio in Red Hat OpenShift to enable developers to deploy their applications in a more secure and efficient manner."
- Brian 'Redbeard' Harrington, product manager, Istio, Red Hat
“VMware has been an integral part of the community developing Istio service mesh. We see great potential in Istio’s service-based approach to connectivity, security, and observability. We believe it will become an infrastructure cornerstone, spanning across vSphere and Kubernetes platforms and multiple private and public clouds, and helping our enterprise customers improve development efficiencies and deliver on their SLAs / SLOs in a secure manner. Istio’s application layer complements the network virtualization layer, and together allow enterprises to achieve defense in depth, improve performance and scalability, and speed time to application value.”
- Pere Monclus, CTO Network and Security, VMware
We’re also thrilled with the number of companies writing adapters for Istio—from observability software from SolarWinds and Datadog, to deployment tools from Weaveworks and CodeFresh, to policy and security offerings from Aspenmesh and Octarine. While Istio is transparent to application developers, it provides a standard integration interface for anyone writing observability tools or policy engines.
Working and integrating with other open source projects in the community drives our success, as well. Integrations with SPIFFE, the Open Policy Agent and OpenTracing all improve the state of open source and the lives of developers.
Istio on GCP
While the open-source Istio project is a major undertaking, we’re also intent on making it especially easy to use on Google Cloud Platform. Last week at Google Cloud Next we announced the alpha release of Managed Istio: open-source Istio that’s automatically installed and upgraded on your Kubernetes Engine clusters as a part of the Cloud Services Platform. Managed Istio will help provide the visibility, security and control you need over services running in hybrid environments, and it integrates with other Google products like Stackdriver and Apigee.Achieving 1.0 is just a first step, both for the project and for us at Google Cloud. We have ambitious plans for adding features and improving Istio’s usability with the ultimate goal of delivering a complete set of tools to manage all of your services, so that you can focus on writing software and running a business.
To find out more about Istio and how to get started using it on GCP, please visit cloud.google.com/istio.
Access Google Cloud services, right from IntelliJ IDEA 31 Jul 2018 6:00 AM (6 years ago)
By Etan Shaul, Software Engineer
Great news for IntelliJ users: You can now use Google Cloud services and APIs right from JetBrains’ integrated development environment (IDE). With the Cloud Tools for IntelliJ plugin, you can now discover APIs, consume them, and test against them locally, all without leaving your IDE.
The Cloud Tools plugin for IntelliJ streamlines the development process by integrating tasks into the IDE, such as enabling Google Cloud APIs, creating service accounts for local development, and adding the corresponding Java client libraries to your build.
Example: Using the Cloud Translation API with the Cloud Tools for IntelliJ plugin
Say you are interested in using the Cloud Translation API in our Java Maven-based project. If the Cloud Tools for IntelliJ plugin isn’t already configured, then first install it as described in this quickstart.
Clone the example Cloud Translation project, which allows you to translate some input text from English to French.
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git
At this point, you might simply try to run the application by navigating to the main method and clicking the play button:
… and configuring the input arguments to translate some text from English to French by editing the newly created run configuration:
Run the program again, and this time you get the following error:
As you may have already guessed, you’re missing authentication rights to access the Cloud Translation API from your local machine. To overcome this, you’d normally have to go through the following steps:
- Enable the service on your Google Cloud Platform (GCP) project
- Create a new service account with the appropriate roles for accessing the service
- Update your local run configuration with the necessary environment variables to access the service

Select the Cloud Translation API and your GCP project, and click “Add Cloud Libraries”:
In the confirmation window that appears, you can see that Cloud Tools for IntelliJ takes care of enabling the API and creating the service account for you:
Lastly, select the run configuration that you created earlier so that the plugin can inject the necessary environment variables for accessing the Cloud Translation service from your local machine:

Run the program again and your input text is successfully translated from English to French using the Cloud Translation service:
The Cloud Tools for IntelliJ plugin also assists with the following:
- Adding Java client libraries to your Maven pom.xml if they are not already present
- Writing a Bill of Materials (BOM) to your pom.xml to help avoid dependency version conflicts
- Detecting and acting on potential misconfigurations, including a missing BOM, through pom.xml file inspections with quick-fixes
Cloud Tools for IntelliJ:
Drilling down into Stackdriver Service Monitoring 30 Jul 2018 9:00 AM (6 years ago)
By Jay Judkowitz, Sr. Product Manager
If you’re responsible for application performance and availability, you know how hard it can be to see it through the eyes of your customers and end users. We think that’s really going to change with last week’s introduction of Stackdriver Service Monitoring, a new tool for monitoring how your customers perceive your applications, and that then lets you drill down to the underlying infrastructure when there’s a problem.
Most IT operations tools take a bottoms-up understanding of IT systems: they look at compute, storage, and networking metrics to infer the customer experience. Application performance management (APM) tools like tracing systems, debuggers, and profilers consider the application from the code level—but lose sight of the underlying infrastructure. Sometimes, a logs analytics solution can provide the glue between those two layers, but often with great effort and expense.
IT operators have been missing a cost-effective, easy-to-use, general-purpose tool to monitor the customer-facing behavior of their applications. It’s hard to know how end users experience your software and it’s difficult to measure services and applications in a standardized way. Ops staff risk burning out from all the spurious alerts. The result of all this is that mean-time-to-resolution (MTTR) is longer than necessary, and customer satisfaction is lower than desired. The situation is exacerbated with microservice architectures where the app itself is broken into many small pieces, which makes it hard to understand how all the pieces fit together and where to start investigating when there is a problem.
That all changes with the release of Stackdriver Service Monitoring. Service Monitoring takes advantage of service-aware, “opinionated” infrastructure so you can monitor how end users perceive your systems, letting you drill down to the infrastructure level when necessary. Initially, we are supporting this functionality for Google App Engine and for Istio service meshes running on Google Kubernetes Engine. We will expand to more platforms over time.
With Stackdriver Service Monitoring, you get the answers to the following questions:
- What are your services? What functionality do those services expose to internal and external customers?
- What are your promises and commitments regarding the availability and performance of those services, and are your services meeting them?
- For microservices-based apps, what are the inter-service dependencies? How can you use that knowledge to double check new code rollouts and triage problems in the event of service degradation?
- Can you look at all the monitoring signals for a service holistically to reduce MTTR?
Anatomy of Stackdriver Service Monitoring
Service Monitoring has three pieces: the service graph, Service Level Objectives (SLOs), and multi-signal service dashboards. Together, these give you an inventory of your services, visually display the dependencies between them, let you set and measure availability and performance promises, help you triage application problems to quickly find the root cause, and finally, help you debug broken services more quickly than ever before. Let’s look at each piece in turn.The service graph: This is a service-specific view of your infrastructure. It starts out with a real-time top level display of all services in the Istio service mesh and the communication links between them. Selecting one service displays charts with error rates and latency metrics. Double-clicking on a service allows you to drill down into its underlying Kubernetes infrastructure, providing the long elusive connection between app behavior and infrastructure. There is also a time slider which allows you to see the graph at previous points in time. Using the service graph you can see your application architecture for reference purposes or to triage problems. You can explore metrics about service behavior, and determine whether an upstream service is causing problems to a downstream service. Finally, you can compare the service graph at different points in time to determine whether there was a significant architectural change right before a problem was reported. There is no quicker way to get started exploring and understanding complex multi-service applications.

SLOs: Internally at Google, our Site Reliability Engineering team (SRE) only alert themselves on customer-facing symptoms of problems, and not all potential causes. This better aligns them to customer interests, lowers their toil, frees them to do value-added reliability engineering, and increases job satisfaction. Stackdriver Service Monitoring lets you to set, monitor, and alert on SLOs. Because Istio and App Engine are instrumented in an opinionated way, we know exactly what the transaction counts, error counts, and latency distributions are between services. All you need to do is set your targets for availability and performance and we automatically generate the graphs for service level indicators (SLIs), compliance to your targets over time, and your remaining error budget. You can configure the maximum allowed drop rate for your error budget; if that rate is exceeded, we notify you and create an incident so that you can take action. To learn more about SLO concepts including error budget, we encourage you to read the SLO chapter of the SRE book.

Service Dashboard: At some point, you will need to dig deeper into a service’s signals. Maybe you received an SLO alert and there’s no obvious upstream cause. Maybe the service is implicated by the service graph as a possible cause for another service’s SLO alert. Maybe you have a customer complaint outside of an SLO alert that you need to investigate. Or, maybe you want to see how the rollout of a new version of code is going.
The service dashboard provides a single coherent display of all signals for a specific service, all of them scoped to the same timeframe with a single control, providing you the fastest possible way to get to the bottom of a problem with your service. Service monitoring lets you dig deep into the service’s behavior across all signals without having to bounce between different products, tools, or web pages for metrics, logs, and traces. The dashboard gives you a view of the SLOs in one tab, the service metrics (transaction rates, error rates, and latencies) in a second tab, and diagnostics (traces, error reports, and logs) in the third tab.

Once you’ve validated an error budget drop in the first tab and isolated anomalous traffic in the second tab, you can drill down further in the diagnostics tab. For performance issues, you can drill down into long tail traces, and from there easily get into Stackdriver Profiler if your app is instrumented for it. For availability issues you can drill down into logs and error reports, examine stack traces, and open the Stackdriver Debugger, if the app is instrumented for it.

Stackdriver Service Monitoring gives you a whole new way to view your application architecture, reason about its customer-facing behaviors, and get to the root of any problems that arise. It takes advantage of infrastructure software enhancements that Google has championed in the open source-world, and leverages the hard-won knowledge of our SRE teams. We think this will fundamentally transform the ops experience of cloud native and microservice development and operations teams. To learn more see the presentation and demo with Descartes Labs at GCP Next last week. We hope you will sign up to try it out and share your feedback.
Transparent SLIs: See Google Cloud the way your application experiences it 27 Jul 2018 8:00 AM (6 years ago)
By Jay Judkowitz, Sr. Product Manager
Like all good IT organizations, you religiously measure the performance and availability of your services and applications. But if those apps run in the cloud, critical components are often delivered by a third party or the cloud provider. In the case of a service disruption or degraded performance, how do you know what the problem is—your code, the network, or the provider? And, if the problem is with the service provider, how do you convince them to take action as quickly as possible?
Here at Google Cloud, we are the first cloud provider to report detailed standardized metrics on the behavior of our more than 130 Google Cloud service APIs, and how they are experienced by your applications. Today, we are happy to announce Transparent SLIs (service level indicators) - fine-grained detail about the behavior of Google Cloud Platform (GCP) services as related to your workloads. We display this data in Stackdriver Monitoring dashboards, and it's the same kind of data that Google SREs use to keep our services up and running. (Visit this post to learn more about SLIs.)
Transparent SLI metrics go far beyond simple up/down monitoring of our services. Now, you can debug subtle interactions between your application and our service from Stackdriver metrics such as how many transactions you sent, the rates of their various response codes, and their latency distribution. Then, for each service, you can slice and dice the metrics according to:
- Service name
- Method
- API version
- Credential ID
- Location
- Protocol (HTTP / gRPC)
- HTTP Response Code (e.g. 402)
- HTTP Response Code class (e.g. 4xx)
- gRPC Status Code
 |
An example dashboard for GCP services that groups metrics by service, method and response code. You can also view latency charts on a log scale to quickly find outliers.
|
Data is power
Transparent SLIs give you the ability to transform your cloud operations for the better. By helping you drill down into interactions between your software and our services, GCP service metrics can tell you whether our services are behaving abnormally for your app’s traffic to speed the problem triage process. Furthermore, when you’re communicating with Google tech support, you can direct them to these charts so that everyone is working from the same data and can agree as to what’s being experienced. By shortening triage time and back and forth with tech support, we can dramatically reduce resolution times.Here are some examples of how using GCP service metrics can improve the support experience:
- If all of your calls to a service are failing for a single credential ID, but not any other, chances are there’s something wrong with that account that you can fix yourself without opening a ticket.
- You’re troubleshooting a problem with your app, and notice a correlation between your application’s degraded performance and a sustained increase in the 50th percentile latency of a critical GCP service. Definitely call us and point us to this data so we can start working on the problem as quickly as possible.
- The latencies for a GCP service report look good and unchanged from before, but your in-app client-side metrics report that the latency on calls to the service is abnormally high. That suggests that there might be some trouble in the network. Call your network provider (in some cases, Google) to get the debugging process started.
Transparent SLIs may also help you understand that latency results for most services fall within a normal distribution: a big hump in the middle, and outliers on either side. The metrics will help you understand the normal distribution so that you can engineer your app to work well within the distribution curve. For example, the metrics can help you correlate distribution changes with times when your app is not working as intended, helping you find the root cause of an issue. We expect the 99th percentile to look very different than the median—what we don’t expect are dramatic changes in those percentiles over time. Thus, when investigating whether a GCP service is at fault for an application problem, you should examine the return codes and latency rates over time and look for sustained changes from the norm that are correlated with observed issues in your application. (We suggest that you consider the last week to be the norm.)
Setting up dashboards for Transparent SLIs
To get started collecting and exploring Transparent SLIs, go to Stackdriver Metrics Explorer and select "Consumed API" as the resource type. Stackdriver then introspects your project and creates a list of metrics that you can chart based on the products and services you are using. You can then pick the metrics that make the most sense for your environment. You can narrow down the data you display by specifying which project or service you want to monitor. It may also be helpful to specify which credentials’ traffic to view so that you only monitor traffic from production applications and not from other sources.
Stackdriver Metrics Explorer supports availability and latency metrics, which you can combine with filters and aggregations for new and insightful views into your application performance. For example, you can combine a request count metric with a filter on the HTTP Response Code class to build a dashboard that shows error rates over time. Or you can look at the 95th percentile latency of requests to the Cloud Pub/Sub API.
Since the main use case for Transparent SLIs is to help you triage issues with your application and see if GCP services may be the cause, the ideal way to use this data is to mix our metrics with yours. If you have an app that is highly dependent on Cloud SQL, for example, don’t graph the SLIs for Cloud SQL on their own—create a chart with your app’s error rate as one line and the Cloud SQL error rate as another line on the same chart. Doing this allows you to see at a glance whether Cloud SQL errors are a likely cause of unavailability in your app. It may take some trial and error to get the dependencies and sensitivities completely correct. See this video segment from GCP Next to see how Snapchat integrated Transparent SLIs into their dashboards.
Keep us honest
We here at Google Cloud are committed to transparency, and sharing metrics about our services is an important part of that ethic. By sharing them with you, you can easily check up on how we are doing, so that when we work together on a service ticket, everyone is on the same page. We think Transparent SLIs will radically improve your tech support experience and increase your confidence in Google Cloud. Try it out and let us know what you think!
Google Cloud and GitHub collaborate to make CI fast and easy 26 Jul 2018 8:28 AM (6 years ago)
By Melody Meckfessel, Vice President, Engineering, Google Cloud
Today, Google Cloud and GitHub are delivering a new integrated experience that connects GitHub with Google’s Cloud Build, our new CI/CD platform. Together, we will provide fast, frictionless, and convenient Continuous Integration (CI) for any repository on GitHub, integrated directly into the GitHub developer workflow.
Millions of developers trust GitHub today to store and collaborate around source code. Working with GitHub, we realized we had an opportunity to help make it significantly easier for any repository to add CI, integrate DevOps practices, and improve velocity and productivity. We set out to build that together, and today’s release is the first step in that collaboration.
Continuous Integration drives developer productivity
“Continuous integration is a crucial element of modern software development, but historically one that has required development teams to invest significant effort in patching together disparate software products and services to build a working, streamlined pipeline. This is an area where partners with adjacent offerings can add real value by pre-integrating the necessary pieces to deliver a seamless experience. This is what GitHub and Google have set out to do.”Software development is built on trust. We work in teams and trust our fellow developers to write the right code together. We use open-source operating systems, tools, and libraries so we can focus on the code that we need to write. We trust cloud platforms so we can develop, test, run, and manage our applications securely, at scale. Google Cloud builds on that trust by developing and using open technologies such as Kubernetes, TensorFlow, and Go.
- Rachel Stephens, Analyst, RedMonk
DevOps is also built on trust. Trust is what lets us go faster. We know that mistakes and errors happen and that we will learn from them. We create a culture of trust through transparency and data-driven decisions, through a spirit of shared-fate and blameless post-mortems for continuous improvement. We use automation everywhere, especially CI, to create a safety net. Trust in our tests and our tools lets us go faster. Cloud Build provides the DevOps tools to unleash developer productivity, and help teams go faster.
Collaborations are built on trust too. Google and GitHub have a long history of working together to make software development better for all developers. We have a shared belief in the principles and practices of open source, and a shared vision of productive developers and software teams. We have worked together on improvements to the Git client and protocol, as well as other projects. And Google uses GitHub too: Googlers contributed to nearly 30,000 repos on GitHub last year, some of which are among the most popular projects on GitHub.
Cloud Build and GitHub, better together
“GitHub is excited to partner with Google to make CI for cloud-native application development painless. The ability to use Cloud Build for CI as a part of the GitHub workflow is just the start of this partnership and we look forward to building more in the future with Google.”The integration of Cloud Build with GitHub makes it quick to adopt CI and validate changes by integrating code early and often, bringing a host of benefits to developers, directly from their GitHub workflow.
- Jason Warner, SVP of Technology at GitHub (read more in GitHub’s blog post)
Zero-config Docker builds: In one step, you can run automated container builds and tests on changes pushed to a GitHub repository as a part of every pull request. GitHub will automatically detect and recommend CI for repositories that contain a Dockerfile.
Scalability: Cloud Build meets the growing needs of your organization. You can go from a single build on your local machine to multiple builds in parallel in the cloud across numerous projects, all in a matter of minutes.
Security: The builds run on infrastructure protected by Google’s security. You get full control over who can create and view your builds, what source code can be used, and where your build artifacts are stored.
Flexibility: For advanced use cases, you can include a cloudbuild.yaml file when setting up CI using Cloud Build. This lets you define custom build steps, speed up builds by caching a Docker image, build leaner containers, and deploy directly to Google Kubernetes Engine, Google App Engine, on-prem clusters (in alpha soon), or another cloud provider.
Insights: Once the build is complete, details about build times, failures and artifacts are available within GitHub through the Checks API, so you can understand and diagnose build results from within the familiar GitHub environment. Full logs and history are available in Cloud Build’s UI in the Google Cloud Console.
Join us
Today’s integration is already available in the GitHub Marketplace. Smart CI recommendations will be rolled out to all GitHub users on a phased basis. Please try it out, and share your feedback with us.Google and GitHub have had a long relationship serving developers, and this is just the next step. We know there are many other ways we can make software development better for developers. We trust you’ll join us on this journey.
Accelerating software teams with Cloud Build 26 Jul 2018 8:28 AM (6 years ago)
By Melody Meckfessel, Vice President, Engineering, Google Cloud
Software development has come a long way from the days of “it compiles, ship it!” Today’s software teams need to deliver more business value faster than ever—in an environment where the pace of change is accelerating. And while change can mean faster hardware, better security, and more features, it can also come at a cost: new vulnerabilities are discovered every day and seemingly innocuous updates can cause applications to break.
DevOps has learned a lot from manufacturing. The best time to catch and fix a problem is as early and automatically as possible. In software, a similar culture of continuous improvement is essential, along with new tools to automate best practices, like continuous integration and continuous delivery (CI/CD).
Many organizations have embraced CI/CD, but the engineering cost and complexity of operating and maintaining secure and reliable CI/CD infrastructure is high. Incorporating best practices takes time. These are resources better spent writing software. That’s why we introduced Cloud Build, a fully-managed CI/CD platform that lets you build and test applications in the cloud–at scale.
"We found Cloud Build to be feature rich yet also easy to learn and use. We use its parallelization and caching capabilities to speed up our container builds, and leverage its container analysis API to bless our images. Its reliability has allowed us to focus our attention on other areas."In creating Cloud Build we worked with and listened to you, software developers from every walk of life, on teams of every size. We also spent time understanding what helped our own internal engineering teams be productive. Three things consistently stood out.
- Riley Shott, Production Engineer at Shopify
Scalability: No build is ever too quick. No test suite runs too fast. As a project grows over time and new developers join the team, your CI/CD system must keep up. Built on top of Google's cloud infrastructure, with a range of CPU sizes available and pay-for-what-you-use pricing, Cloud Build can grow with your organization.
Flexibility: Software development is an increasingly complex web of ever-changing frameworks, dependencies, services, languages, and tools. Your applications are deployed across multiple clouds, on-premise resources and mobile app stores. To support your development needs, Cloud Build works with major source repositories like GitHub, GitLab, Cloud Source Repositories, and BitBucket. It also features built-in support for Docker, Maven, Gradle, Bazel, Go, and npm. An ecosystem of add-ons and the ability to bring your own tasks and toolchains as containers makes integrating into your existing developer workflow easy. You can use Cloud Build for hybrid scenarios with VPC networking and custom workers (in alpha).
Security: Security isn’t just for runtimes, it’s a full lifecycle problem that extends into every tool and pipeline you use. Cloud Build uses GCP’s world-class security and policy controls so you have control and visibility of your source and build. Cloud Build runs every build on its own VM, which reduces the risk of information leaking between builds or build errors caused by inconsistent build environments. Vulnerability scanning automatically finds known vulnerabilities in your container images (in alpha for Ubuntu, Debian, and Alpine).
As Rob Pike describes it, “Software engineering is what happens to programming when you add time and other programmers.” Striking a balance between time, quality, velocity and security is hard—but not insurmountable. The key to this balance is trust. When you can trust your tools as a safety net and your culture as a compass it’s much easier to take risks and move fast. Cloud Build makes high velocity software development safer and easier, and unleashes your team’s productivity -- try it out today!
On GCP, your database your way 25 Jul 2018 8:00 AM (6 years ago)
By Brad Calder, VP of engineering, GCP
When choosing a cloud to host your applications, you want a portfolio of database options—SQL, NoSQL, relational, non-relational, scale up/down, scale in/out, you name it—so you can use the right tool for the job. Google Cloud Platform (GCP) offers a full complement of managed database services to address a variety of workload needs, and of course, you can run your own database in Google Compute Engine or Kubernetes Engine if you prefer.
Today, we’re introducing some new database features along with partnerships, beta news and other improvements that can help you get the most out of your databases for your business.
Here’s what we’re announcing today:
- Oracle workloads can now be brought to GCP
- SAP HANA workloads can run on GCP persistent-memory VMs
- Cloud Firestore launching for all users developing cloud-native apps
- Regional replication, visualization tool available for Cloud Bigtable
- Cloud Spanner updates, by popular demand
Managing OracleⓇ workloads with Google partners
Until now, it's been a challenge for customers to bring some of the most common workloads to GCP. Today, we’re excited to announce that we are partnering with managed service providers (MSPs) to provide a fully managed service for Oracle workloads for GCP customers. Partner-managed services like this unlock the ability to run Oracle workloads and take advantage of the rest of the GCP platform. You can run your Oracle workloads on dedicated hardware and you can connect the applications you’re running on GCP.By partnering with a trusted managed service provider, we can offer fully managed services for Oracle workloads with the same advantages as GCP services. You can select the offering that meets your requirements, as well as use your existing investment in Oracle software licenses.
We are excited to open the doors to customers and partners whose technical requirements do not fit neatly into the public cloud. By working with partners, you’ll have the option to move these workloads to GCP and take advantage of the benefits of not having to manage hardware and software. Learn more about managing your Oracle workloads with Google partners, available this fall.
Partnering with Intel and SAP
This week we announced our collaboration with Intel and SAP to offer Compute Engine virtual machines backed by the upcoming Intel Optane DC Persistent Memory for SAP HANA workloads. Google Compute Engine VMs with this Intel Optane DC persistent memory will offer higher overall memory capacity and lower cost compared to instances with only dynamic random-access memory (DRAM). Google Cloud instances on Intel Optane DC Persistent Memory for SAP HANA and other in-memory database workloads will soon be available through an early access program. To learn more, sign up here.We’re also continuing to scale our instance size roadmap for SAP HANA production workloads. With 4TB machine types now in general availability, we’re working on new virtual machines that support 12TB of memory by next summer, and 18TB of memory by the end of 2019.
Accelerate app development with Cloud Firestore
For app developers, Cloud Firestore brings the ability to easily store and sync app data at global scale. Today, we're announcing that we’ll soon expand the availability of the Cloud Firestore beta to more users by bringing the UI to the GCP console. Cloud Firestore is a serverless, NoSQL document database that simplifies storing, syncing and querying data for your cloud-native apps at global scale. Its client libraries provide live synchronization and offline support, while its security features and integrations with Firebase and GCP accelerate building truly serverless apps.We're also announcing that Cloud Firestore will support Datastore Mode in the coming weeks. Cloud Firestore, currently available in beta, is the next generation of Cloud Datastore, and offers compatibility with the Datastore API and existing client libraries. With the newly introduced Datastore mode on Cloud Firestore, you don’t need to make any changes to your existing Datastore apps to take advantage of the added benefits of Cloud Firestore. After general availability of Cloud Firestore, we will transparently live-migrate your apps to the Cloud Firestore backend, and you’ll see better performance right away, for the same pricing you have now, with the added benefit of always being strongly consistent. It’ll be a simple, no-downtime upgrade. Read more here about Cloud Firestore.
Simplicity, speed and replication with Cloud Bigtable
For your analytical and operational workloads, an excellent option is Google Cloud Bigtable, a high-throughput, low-latency, and massively scalable NoSQL database. Today, we are announcing that regional replication is generally available. You can easily replicate your Cloud Bigtable data set asynchronously across zones within a GCP region, for additional read throughput, higher durability and resilience in the face of zonal failures. Get more information about regional replication for Cloud Bigtable.Additionally, we are announcing the beta version of Key Visualizer, a visualization tool for Cloud Bigtable key access patterns. Key Visualizer helps debug performance issues due to unbalanced access patterns across the key space, or single rows that are too large or receiving too much read or write activity. With Key Visualizer, you get a heat map visualization of access patterns over time, along with the ability to zoom into specific key or time ranges, or select a specific row to find the full row key ID that's responsible for a hotspot. Key Visualizer is automatically enabled for Cloud Bigtable clusters with sufficient data or activity, and does not affect Cloud Bigtable cluster performance. Learn more about using Key Visualizer on our website.
 |
| Key Visualizer, now in beta, shows an access pattern heat map so you can debug performance issues in Cloud Bigtable. |
Finally, we launched client libraries for Node.js (beta) and C# (beta) this month. We will continue working to provide stronger language support for Cloud Bigtable, and look forward to launching Python (beta), C++ (beta), native Java (beta), Ruby (alpha) and PHP (alpha) client libraries in the coming months. Learn more about Cloud Bigtable client libraries.
Cloud Spanner updates, by popular request
Last year, we launched our Cloud Spanner database, and we’ve already seen customers do proof-of-concept trials and deploy business-critical apps to take advantage of Cloud Spanner’s benefits, which include simplified database administration and management, strong global consistency, and industry-leading SLAs.Today we’re announcing a number of new updates to Cloud Spanner that our customers have requested. First, we recently announced the general availability of import/export functionality. With this new feature, you can move your data using Apache Avro files, which are transferred with our recently released Apache Beam-based Cloud Dataflow connector. This feature makes Cloud Spanner easier to use for a number of important use cases such as disaster recovery, analytics ingestion, testing and more.
We are also previewing data manipulation language (DML) for Cloud Spanner to make it easier to reuse existing code and tool chains. In addition, you’ll see introspection improvements with Top-N Query Statistics support to help database admins tune performance. DML (in the API as well as in the JDBC driver), and Top-N Query Stats will be released for Cloud Spanner later this year.
Your cloud data is essential to whatever type of app you’re building with GCP. You’ve now got more options than ever when picking the database to power your business.
Announcing resource-based pricing for Google Compute Engine 25 Jul 2018 7:59 AM (6 years ago)
By Paul Nash, Group Product Manager, Google Compute Engine
The promise and benefit of the cloud has always been flexibility, low cost, and pay-per-use. With Google Compute Engine, custom machine types let you create VM instances of any size and shape, and we automatically apply committed use and sustained use discounts to reduce your costs. Today, we are taking the concept of pay-for-use in Compute Engine even further with resource-based pricing.
With resource-based pricing we are making a number of changes behind the scenes that align how we treat metering of custom and predefined machine types, as well as how we apply discounts for sustained use discounts. Simply put, we’ve made changes to automatically provide you with more savings and an easy-to-understand monthly bill. Who doesn’t love that?
Resource-based pricing considers usage at a granular level. Instead of evaluating your usage based on which machine types you use, it evaluates how many resources you consume over a given time period. What does that mean? It means that a core is a core, and a GB of RAM is a GB of RAM. It doesn’t matter what combination of pre-defined machine types you are running. Now we look at them at the resource level—in the aggregate. It gets better, too, because sustained use discounts are now calculated regionally, instead of just within zones. That means you can accrue sustained use discounts even faster, so you can save even more automatically.
To better understand these changes, and to get an idea of how you can save, let’s take a look at how sustained use discounts worked previously, and how they’ll work moving forward.
- Previously, if you used a specific machine type (e.g. n1-standard-4) with four vCPUs for 50% of the month, you got an effective discount of 10%. If you used it for 75% of the month, you got an effective discount of 20%. If you use it for 100% of the month, you got an effective discount of 30%.
- Let’s say you were running a web-based service. You started the month running an n1-standard-4 with four vCPUs. In the second week user demand for your service increased and you scaled capacity. You started running an n1-standard-8 with eight vCPU. Ever increasing demand caused you to scale up again. In week three you began running an n1-standard-16 with sixteen vCPU. Due to your success you wound up scaling again—ending the month running an n1-standard-32 with thirty-two vCPU. In this scenario you wouldn’t receive any discount, because you didn’t run any of the machine types for up to 50% of the month.

With resource-based pricing, we no longer consider your machine type and instead, we add up all the resources you use across all your machines into a single total and then apply the discount. You do not need to take any action. You save automatically. Let’s look at the scaling example again, but this time with resource-based pricing.
- You began the month running four vCPU, and subsequently scaled to eight vCPU, sixteen vCPU and finally thirty-two vCPU. You ran four vCPU all month, or 100% of the time, so you receive a 30% discount on those vCPU. You ran another four vCPU for 75% of the month, so you receive a 20% discount on those vCPU. And finally, you ran another eight vCPU for half the month, so you receive a 10% discount on those vCPU. Sixteen vCPU were run for one week, so they did not qualify for a discount. Let’s visualize how this works, to reinforce what we’ve learned.

And because resource-based pricing applies at a regional level, it’s now even easier for you to benefit from sustained use discounts, no matter which machine types you use, or the number of zones in a region in which you operate. Resource-based pricing will take effect in the coming months. Visit the Resource-based pricing page to learn more.
%20with%20four%20vCPUs%20for%2050%25%20of%20the%20month,%20you%20got%20an%20effective%20discount%20of%2010%25.%20If%20you%20used%20it%20for%2075%25%20of%20the%20month,%20you%20got%20an%20effective%20discount%20of%2020%25.%20If%20you%20use%20it%20for%20100%25%20of%20the%20month,%20you%20got%20an%20effective%20discount%20of%2030%25.%3C/li%3E%0A%3C/ul%3E%0AOkay.%20Now,%20what%20if%20you%20used%20different%20machine%20types?%20%0A%3Cbr%20/%3E%0A%3Cul%3E%0A%3Cli%3ELet%E2%80%99s%20say%20you%20were%20running%20a%20web-based%20service.%20You%20started%20the%20month%20running%20an%20n1-standard-4%20with%20four%20vCPUs.%20In%20the%20second%20week%20user%20demand%20for%20your%20service%20increased%20and%20you%20scaled%20capacity.%20You%20started%20running%20an%20n1-standard-8%20with%20eight%20vCPU.%20Ever%20increasing%20demand%20caused%20you%20to%20scale%20up%20again.%20In%20week%20three%20you%20began%20running%20an%20n1-standard-16%20with%20sixteen%20vCPU.%20Due%20to%20your%20success%20you%20wound%20up%20scaling%20again%E2%80%94ending%20the%20month%20running%20an%20n1-standard-32%20with%20thirty-two%20vCPU.%20In%20this%20scenario%20you%20wouldn%E2%80%99t%20receive%20any%20discount,%20because%20you%20didn%E2%80%99t%20run%20any%20of%20the%20machine%20types%20for%20up%20to%2050%25%20of%20the%20month.%3C/li%3E%0A%3C/ul%3E%0A%3Cdiv%3E%0A%3Cimg%20border%3D%220%22%20data-original-height%3D%221040%22%20data-original-width%3D%221200%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjMZdWgmA8aUNCBknQobrA6Ydc3m5P5Rk-vp3zoFsRJcesEgZr_0YTXDPjggKPbYr2qCmb5lNBkdpnMg1jzE_ypX2maN2PwdoFWPN_zX5KtvepDsuaKIxfftN9FIhCTDPrimroK1hvWAuI/s1600/google_compute_engine_different_machine_types.png%22%20/%3E%3C/div%3E%0A%3Cbr%20/%3E%0AWith%20resource-based%20pricing,%20we%20no%20longer%20consider%20your%20machine%20type%20and%20instead,%20we%20add%20up%20all%20the%20resources%20you%20use%20across%20all%20your%20machines%20into%20a%20single%20total%20and%20then%20apply%20the%20discount.%20You%20do%20not%20need%20to%20take%20any%20action.%20You%20save%20automatically.%20Let%E2%80%99s%20look%20at%20the%20scaling%20example%20again,%20but%20this%20time%20with%20resource-based%20pricing.%0A%3Cbr%20/%3E%0A%3Cul%3E%0A%3Cli%3EYou%20began%20the%20month%20running%20four%20vCPU,%20and%20subsequently%20scaled%20to%20eight%20vCPU,%20sixteen%20vCPU%20and%20finally%20thirty-two%20vCPU.%20You%20ran%20four%20vCPU%20all%20month,%20or%20100%25%20of%20the%20time,%20so%20you%20receive%20a%2030%25%20discount%20on%20those%20vCPU.%20You%20ran%20another%20four%20vCPU%20for%2075%25%20of%20the%20month,%20so%20you%20receive%20a%2020%25%20discount%20on%20those%20vCPU.%20And%20finally,%20you%20ran%20another%20eight%20vCPU%20for%20half%20the%20month,%20so%20you%20receive%20a%2010%25%20discount%20on%20those%20vCPU.%20Sixteen%20vCPU%20were%20run%20for%20one%20week,%20so%20they%20did%20not%20qualify%20for%20a%20discount.%20Let%E2%80%99s%20visualize%20how%20this%20works,%20to%20reinforce%20what%20we%E2%80%99ve%20learned.%3C/li%3E%0A%3C/ul%3E%0A%3Cdiv%3E%0A%3Cimg%20border%3D%220%22%20data-original-height%3D%22824%22%20data-original-width%3D%221200%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiEJ54F7kdNgq1s-m1t4tXDTP6ACmjZgIWFYxCTg8MFm-CAeI-3JAWe-jVQJO6g2P0oxsd4XzDF1sno46cRF0Bc0UmTqt5rpFpvT-1jpR7I9f7Wa7HHE-vlWSeGC2dRIaGLHKupyefZy5E/s1600/google_computre_engine_discount_amounts.png%22%20/%3E%3C/div%3E%0A%3Cbr%20/%3E%0AAnd%20because%20resource-based%20pricing%20applies%20at%20a%20regional%20level,%20it%E2%80%99s%20now%20even%20easier%20for%20you%20to%20benefit%20from%20sustained%20use%20discounts,%20no%20matter%20which%20machine%20types%20you%20use,%20or%20the%20number%20of%20zones%20in%20a%20region%20in%20which%20you%20operate.%20Resource-based%20pricing%20will%20take%20effect%20in%20the%20coming%20months.%20Visit%20the%20%3Ca%20href%3D%22https://cloud.google.com/compute/resource-based-pricing%22%20target%3D%22_blank%22%3EResource-based%20pricing%3C/a%3E%20page%20to%20learn%20more.%3Cdiv%3E%3Cimg%20src%3D%22https://www.google-analytics.com/collect?v%253D1%2526tid%253DUA-34322147-16%2526t%253Dpageview%2526cs%253Dgooglecloudplatform.blogspot.com%2526cm%253Dfeed%22%20/%3E%3C/div%3E)
Cloud Services Platform: bringing the best of the cloud to you 24 Jul 2018 8:00 AM (6 years ago)
By Urs Hölzle, Senior Vice President, Technical Infrastructure
In the decade since cloud computing became mainstream, it’s captured the hearts and minds of developers and enterprises everywhere. But for most IT organizations, cloud is still but a glimmer of what it could be—or what it should be. Today, we’re excited to share our vision for Cloud Services Platform, an integrated family of cloud services that lets you increase speed and reliability, improve security and governance and build once to run anywhere, across GCP and on-premise environments. With Cloud Services Platform, we bring the benefits of the cloud to you, no matter where you deploy your IT infrastructure today—or tomorrow.
Cloud Services Platform puts all your IT resources into a consistent development, management and control framework, automating away low-value and insecure tasks across your on-premise and Google Cloud infrastructure. Specifically, we’re announcing:
- Service mesh: Availability of Istio 1.0 in open source, Managed Istio, and Apigee API Management for Istio
- Hybrid computing: GKE On-Prem with multi-cluster management
- Policy enforcement: GKE Policy Management, to take control of Kubernetes workloads
- Ops tooling: Stackdriver Service Monitoring
- Serverless computing: GKE Serverless add-on and Knative, an open source serverless framework
- Developer tools: Cloud Build, a fully managed CI/CD platform
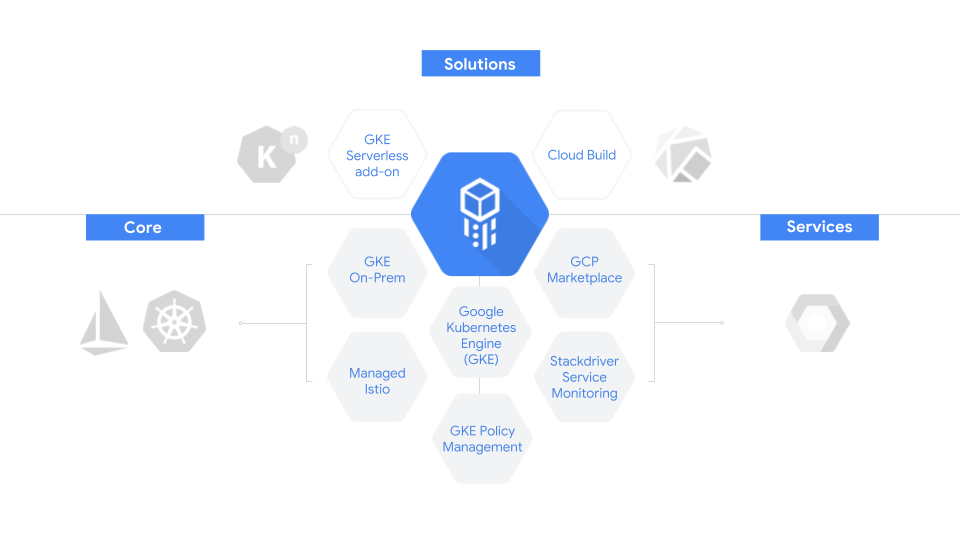 |
| The Cloud Services Platform family |
“We needed a consistent platform to deploy and manage containers on-premise and in the cloud. As Kubernetes has become the industry standard, it was natural for us to adopt Kubernetes Engine on GCP to reduce the risk and cost of our deployments.”Cloud Services Platform is technologically and architecturally aligned with the joint hybrid cloud products we've been developing and bringing to market with our partner, Cisco, with whom we have been collaborating closely. Our joint solution, Cisco Hybrid Cloud Platform for Google Cloud, will be generally available next month and is now certified to be consistent with Kubernetes Engine, enabling GCP out of the box.
- Dinesh KESWANI, Global Chief Technology Officer at HSBC
Today, let’s take a look at aspects of the Cloud Services Platform, and how it lays a foundation for a fully realized cloud infrastructure.
Modernizing application architecture with Istio
Last year, we took a step toward helping organizations move from reactive IT management to proactive service operations—the idea of managing at a higher layer of the stack, enabling greater application awareness and control. In collaboration with several industry partners, we announced Istio, an open-source service mesh that gives operators the controls they need to manage microservices at scale. We are excited to say that open-source Istio will move to version 1.0 shortly, making it ready for production deployments.Building on that open-source foundation, we are announcing a managed Istio service that you can use to manage services within a Kubernetes Engine cluster. Managed Istio, in alpha, is an Istio-powered service mesh available in Kubernetes Engine, complete with enterprise support. Managed Istio accelerates your journey to service operations with three high-level capabilities:
- Service discovery and intelligent traffic management—Managed Istio surfaces all the services running in your cluster and manages network traffic between them. Using application-level load balancing and sophisticated traffic routing for container and VM workloads, it also provides health checks, plus canary and blue/green deployments, enabling fault tolerant applications with circuit breaking and timeouts.
- Secure, authenticated communications—Managed Istio offers segmentation and granular policy for endpoints, compliance and detecting anomalous behavior, and traffic encryption by default using mTLS.
- Monitoring and management—Understand and troubleshoot the system of services running across Managed Istio, including integration with Stackdriver, our suite of monitoring and management tools.
Enterprise-grade Kubernetes, wherever you go
A great path to well-managed applications is undoubtedly containers and microservices, and having a common Kubernetes management layer can help get you there that much faster. Four years ago, we released Kubernetes, and the resulting Kubernetes Engine managed service is battle-tested and growing by leaps and bounds: In 2017 Kubernetes Engine core-hours grew 9X year over year.Today, we are excited to bring that same managed Kubernetes Engine experience to your on-premise infrastructure. GKE On-Prem, soon to be in alpha, is Google-configured Kubernetes that you can deploy in the environment of your choice. GKE On-Prem makes it easy to install and upgrade Kubernetes and provides access to the following capabilities across GCP and on-premise:
- Unified multi-cluster registration and upgrade management
- Centralized monitoring and logging with Stackdriver integration
- Hybrid Identity and Access Management
- GCP Marketplace for Kubernetes applications
- Unified cluster management for GCP and on-premise
- Professional services and enterprise-grade support
Automatically take control of your Kubernetes workloads
When it comes to managing clusters at scale, it’s imperative to have the right security controls in place and ensure your policies can be easily managed and enforced. Today, we’re pleased to announce GKE Policy Management which delivers centralized capabilities that make it far easier for administrators to configure Kubernetes (wherever it may be running).With GKE Policy Management, Kubernetes administrators create a single source of truth for their policies that automatically syncs with any enrolled cluster. GKE Policy Management supports policies stored as definitions in a repository, and can also use your existing Google Cloud IAM policies to make it simple to secure your clusters. GKE Policy Management is coming soon to alpha; sign up here to express interest.
A service-centric view of your environment
More than simply making it easier to migrate workloads to the cloud, the technologies found in Cloud Services Platform lay the groundwork for improving service operations, by providing administrators with a service-centric view of their infrastructure, rather than infrastructure views of services. Today, we are announcing Stackdriver Service Monitoring, which provides the following new views:- Service graph: A real-time bird’s-eye visualization of the entire environment—see all your microservices, how they communicate, and their dependencies.
- Service level objective (SLO) monitoring: Monitor and alert in the same customer-centric, low-toil manner as Google Site Reliability Engineers (SRE) do for our own services.
- Service dashboard: All your signals for a given service are in a single place so that you can debug faster and easier than ever before and lower your mean-time-to-resolution (MTTR).
When microservices become APIs
Microservices provide a simple, compelling way for organizations to accelerate moving workloads to the cloud, serving as a path towards a larger cloud strategy. Istio enables service discovery, connection and management for microservices. But as soon as those services are needed for internal groups, partners or developers outside of the enterprise, they quickly cross the line and become APIs.Just as organizations need services management for microservices, they need API management for their APIs. Apigee API Management complements Istio with the robust features of Google Cloud's Apigee API management platform, Apigee Edge, by extending API management natively into the microservices stack. Apigee Edge features include API usage, access, productization, catalog and discovery, plus a developer portal to create a smooth experience for developers and increase API consumption.
Making cloud all it could be
Here at Google, we could never have done what we do today without containers and Kubernetes, but taking a service-oriented view of our operations has been equally critical. In addition to the core capabilities mentioned above, Cloud Services Platform provides access to other new areas of functionality:- GKE serverless add-on lets you run serverless workloads on Kubernetes Engine with a one-step deploy. You can go from source to containers amazingly fast, auto-scale your stateless container-based workloads, and even scale down to zero. Sign up for an early preview for the GKE serverless add-on here.
- Knative (pronounced kay-nay-tiv), open-source serverless components from the same technology that enables the GKE serverless add-on. Knative lets you create modern, container-based and cloud-native applications by providing building blocks you need to build and deploy container-based serverless applications anywhere on Kubernetes.
- Cloud Build is a fully-managed Continuous Integration/Continuous Delivery (CI/CD) platform that lets you build, test, and deploy software quickly, at scale.
Bringing the best of serverless to you 24 Jul 2018 7:59 AM (6 years ago)
By Eyal Manor, Vice President, Engineering
Every business wants to innovate—and deliver—great software, faster. In recent years, serverless computing has changed application development, bringing the focus on the application logic instead of infrastructure. With zero server management, auto-scaling to meet any traffic demands, and managed integrated security, developers can move faster, stay agile and focus on what matters most—building great applications.
Google helped pioneer the notion of serverless more than 10 years ago with the introduction of App Engine. Making developers more productive is just as important today as it was then. Over the past few years, we have been working hard to bring the benefits of serverless that we learned from App Engine to our compute, storage, database, messaging services, data analytics, and machine learning offerings.
Today, in tandem with the launch of our Cloud Services Platform, we are sharing several important developments to our serverless compute stack:
- New App Engine runtimes
- Cloud Functions general availability, support for additional languages, plus performance, networking and security features
- Serverless containers on Cloud Functions
- GKE serverless add-on
- Knative, Kubernetes-based building blocks for serverless workloads
- Integration of Cloud Firestore with GCP services
Expanding serverless compute
Today we are announcing support for new second-generation App Engine standard runtimes such as Python 3.7 and PHP 7.2 in addition to recent support for Node.js 8. Second generation runtimes provide developers idiomatic, open-source language runtimes capable of running any framework, library, or binary. Based on gVisor technology, these new runtimes enable faster deployments and increased application performance.Also, Cloud Functions, our event-driven compute service, is generally available starting today, complete with predictable service guaranteed by an SLA, and a global footprint with new regions in Europe and Asia. In addition, we are bolstering Cloud Functions with a range of new and heavily requested features including support for Python 3.7 and Node.js 8, networking and security controls, and performance improvements across the board. Cloud Functions also lets you seamlessly connect and extend more than 20 GCP services such as BigQuery, Cloud Pub/Sub, machine learning APIs, G Suite, Google Assistant and many more.
Serverless and containers: the best of both worlds
Whether you’re using App Engine or Cloud Functions, Google’s serverless platform offers a complete mix of tools and services. However, many customers tell us they have custom requirements like specific runtimes, custom binaries, or workload portability. More often than not, they turn to containers for an answer. At Google Cloud, we want to bring the best of both serverless and containers together.Today, we’re also introducing serverless containers, which allow you to run container-based workloads in a fully managed environment and still only pay for what you use. Sign up for an early preview of serverless containers on Cloud Functions to run your own containerized functions on GCP with all the benefits of serverless.
And what if you are already using Kubernetes Engine? A new GKE serverless add-on lets you run serverless workloads on Kubernetes Engine with a one-step deploy. You can go from source to containers instantaneously, auto-scale your stateless container-based workloads, and even scale down to zero. Here’s what T-mobile had to say about running their serverless workloads on Kubernetes Engine:
"The technology behind the GKE serverless add-on enabled us to focus on just the business logic, as opposed to worrying about overhead tasks such as build/deploy, autoscaling, monitoring and observability"
-Ram Gopinathan, Principal Technology Architect, T- Mobile
With Knative, run your serverless workloads anywhere
While we believe Google Cloud is a great place to run all types of workloads, some customers need to run on-premises or across multiple clouds. Based on this feedback, we’re excited to announce Knative (pronounced kay-nay-tiv), which is an open-source set of components from the same technology that enables the GKE serverless add-on.Developed in close partnership with Pivotal, IBM, Red Hat, and SAP, Knative pushes Kubernetes-based computing forward by providing the building blocks you need to build and deploy modern, container-based serverless applications.
Knative focuses on the common but challenging parts of running apps, such as orchestrating source-to-container builds, routing and managing traffic during deployment, auto-scaling workloads, and binding services to event ecosystems. Knative provides you with familiar, idiomatic language support and standardized patterns you need to deploy any workload, whether it’s a traditional application, function, or container.
Knative provides reusable implementations of common patterns and codified best practices, shared by successful, real-world Kubernetes-based frameworks and applications. For instance, Knative comes with a build component that provides powerful abstraction and flexible workflow for building, testing, or deploying container images or non-container artifacts on a Kubernetes cluster. By integrating Knative into your own platform, you don’t have to choose between the portability and familiarity of containers and the automation and efficiency of serverless computing. And you can enjoy the benefits of Google Cloud’s extensive experience delivering serverless computing whether you run on GCP, on-premises or in any other cloud. Get started today with Knative or join the conversation.
A comprehensive serverless ecosystem
Of course, serverless computing is a non-starter if you can’t easily build and deploy the code, store your data, and manage your applications in production as part of your overall IT environment. At Google Cloud, we’re committed to enabling the comprehensive ecosystem of serverless offerings.Cloud Build, for instance, lets you create a continuous integration and delivery (CI/CD) pipeline for your serverless applications. You can define custom workflows for building, testing, and deploying across multiple serverless environment such Cloud Functions, App Engine and even Knative.
Cloud Firestore, one of the most recent additions to our serverless stack, lets you store and sync your app data at global scale. Soon, app developers will be able to easily access Cloud Firestore within the GCP Console, and it will also be compatible with Cloud Datastore.
Finally, our Stackdriver suite has four core capabilities—monitoring, logging, application performance management (APM) and the newly released Service Monitoring—and lets you operate and rapidly diagnose your serverless applications in production.
Toward ubiquitous serverless computing
We’re firm believers in finding ways to simplify operations and bring solutions to market faster. Last week’s launch of commercial Kubernetes applications in GCP Marketplace demonstrates how third-party solutions providers are adopting new technologies rapidly to support enterprise demand for extensible solutions. Now, with these new offerings, we’ll help more developers adopt serverless computing in the languages and platforms of their choice.Click here to learn about the full breadth of Google Cloud serverless technologies.
Partnering with Intel and SAP on Intel Optane DC Persistent Memory for SAP HANA 23 Jul 2018 7:00 AM (6 years ago)
By Nan Boden, Senior Director, Global Technology Partnerships, Google Cloud, and Parthasarathy Ranganathan, Distinguished Engineer
Our customers do extraordinary things with their data. But as their data grows, they face challenges like the cost of resources needed to handle and store it, and the general sizing limitations with low latency in-memory computing workloads.
Our customers' use of in-memory workloads with SAP HANA for innovative data management use cases is driving the demand for even larger memory capacity. We’re constantly pushing the boundaries on GCP’s instance sizes and exploring increasingly cost-effective ways to run SAP workloads on GCP.
Today, we’re announcing a partnership with Intel and SAP to offer GCP virtual machines supporting the upcoming Intel® Optane™ DC Persistent Memory for SAP HANA workloads. These GCP VMs will be powered by the future Intel® Xeon® Scalable processors (code-named Cascade Lake) thereby expanding VM resource sizing and providing cost benefits for customers.
Compute Engine VMs with Intel Optane DC persistent memory will offer higher overall memory capacity with lower cost compared to instances with only dynamic random-access memory (DRAM). This will help enable you to scale up your instances while keeping your costs under control. Compute Engine has consistently been focused on decreasing your operational overhead through capabilities such as Live Migration. And coupled with the native persistence benefits of Intel Optane DC Persistent Memory, you’ll get faster restart times for your most critical business applications.
Google Cloud instances on Intel Optane DC Persistent Memory for SAP HANA and other workloads will be available in alpha later this year for customer testing. To learn more, please fill out this form to register your interest.
To learn more about this partnership, visit our Intel and SAP partnership pages.
5 must-see network sessions at Google Cloud NEXT 2018 20 Jul 2018 1:39 PM (6 years ago)
By Neal Mueller, Product Lead
Whether you’re moving data to or from Google Cloud, or are knee-deep plumbing your cloud network architecture, there’s a lot to learn at Google Cloud Next 2018 next week in San Francisco). Here’s our shortlist of the five must-see networking breakout sessions at the show, in chronological order from Wednesday to Thursday.
 |
| Operations engineer, Rebekah Roediger, delivering cloud network capacity one link at a time, in our Netherlands cloud region (europe-west4). |
GCP Network and Security Telemetry
Speakers: Ines Envid, Senior Product Manager, Yuri Solodkin, Staff Software Engineer and Vineet Bhan, Head of Security Partnerships
Network and security telemetry is fundamental to operate your deployments in public clouds with confidence, providing the required visibility on the behavior of your network and access control firewalls.
When: July 24th, 2018 12:35pm
A Year in GCP Networking
Speakers: Srinath Padmanabhan, Networking Product Marketing Manager, Google Cloud and Nick Jacques, Lead Cloud Engineer, Target
In this session, we will talk about the valuable advancements that have been made in GCP Networking over the last year. We will introduce you to the GCP Network team and will tell you about what you can do to extract the most value from your GCP Deployment.
When: July 24th, 2018 1:55pm
Cloud Load Balancing Deep Dive and Best Practices
Speakers: Prajakta Joshi, Sr. Product Manager and Mike Columbus, Networking Specialist Team Manager
Google Cloud Load Balancing lets enterprises and cloud-native companies deliver highly available, scalable, low-latency cloud services with a global footprint. You will see demos and learn how enterprise customers deploy Cloud Load Balancing and the best practices they use to deliver smart, secure, modern services across the globe.
When: July 25th, 2018 12:35pm
Hybrid Connectivity - Reliably Extending Your Enterprise Network to GCP
Speaker: John Veizades, Product Manager, Google Cloud
In this session, you will learn how to connect to GCP with highly reliable and secure networking to support extending your data center networks into the cloud. We will cover details of resilient routing techniques, access to Google API from on premise networks, connection locations, and partners that support connectivity to GCP -- all designed to support mission-critical network connectivity to GCP.
When: July 26th, 2018 11:40am
VPC Deep Dive and Best Practices
Speakers: Emanuele Mazza, Networking Product Specialist, Google, Neha Pattan, Software Engineer, Google and Kamal Congevaram Muralidharan, Senior Member Technical Staff, Paypal
This session will walk you through the unique operational advantages of GCP VPC for your enterprise cloud deployments. We’ll go through detailed use cases, how to seal and audit your VPC, how to extend your VPC to on-prem in hybrid scenarios, and how to deploy highly available services.
When: July 26th, 2018 9:00am
Be sure to reserve your spot in these sessions today—space is filling up!
.%20Here%E2%80%99s%20our%20shortlist%20of%20the%20five%20must-see%20networking%20breakout%20sessions%20at%20the%20show,%20in%20chronological%20order%20from%20Wednesday%20to%20Thursday.%3Cbr%20/%3E%0A%3Ctable%20cellpadding%3D%220%22%20cellspacing%3D%220%22%3E%3Ctbody%3E%0A%3Ctr%3E%3Ctd%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi1cgt4efx_VwcHSCTC9TbAFdcoTN1mfzAtxC_9aBT20_39enuejyZoQrwpIUTaPfdL4acMOR_-alemqK6nFvkWCJZd-x6xrxg6Yexuu5YeEMqOitkGMr_NVqoWiv4xn6LEXHto7JACX8w/s1600/gcp_netherlands_cloud_region.jpg%22%20imageanchor%3D%221%22%3E%3Cimg%20border%3D%220%22%20data-original-height%3D%221068%22%20data-original-width%3D%221600%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi1cgt4efx_VwcHSCTC9TbAFdcoTN1mfzAtxC_9aBT20_39enuejyZoQrwpIUTaPfdL4acMOR_-alemqK6nFvkWCJZd-x6xrxg6Yexuu5YeEMqOitkGMr_NVqoWiv4xn6LEXHto7JACX8w/s1600/gcp_netherlands_cloud_region.jpg%22%20/%3E%3C/a%3E%3C/td%3E%3C/tr%3E%0A%3Ctr%3E%3Ctd%3EOperations%20engineer,%20Rebekah%20Roediger,%20delivering%20cloud%20network%20capacity%20one%20link%20at%20a%20time,%20in%20our%20Netherlands%20cloud%20region%20(europe-west4).%3C/td%3E%3C/tr%3E%0A%3C/tbody%3E%3C/table%3E%0A%3Cbr%20/%3E%0A%3Ca%20href%3D%22https://cloud.withgoogle.com/next18/sf/sessions/session/156618%22%20target%3D%22_blank%22%3EGCP%20Network%20and%20Security%20Telemetry%3C/a%3E%3Cbr%20/%3E%0A%3Cb%3E%3Ci%3ESpeakers:%20Ines%20Envid,%20Senior%20Product%20Manager,%20Yuri%20Solodkin,%20Staff%20Software%20Engineer%20and%20Vineet%20Bhan,%20Head%20of%20Security%20Partnerships%3C/i%3E%3C/b%3E%3Cbr%20/%3E%0ANetwork%20and%20security%20telemetry%20is%20fundamental%20to%20operate%20your%20deployments%20in%20public%20clouds%20with%20confidence,%20providing%20the%20required%20visibility%20on%20the%20behavior%20of%20your%20network%20and%20access%20control%20firewalls.%3Cbr%20/%3E%0A%3Cb%3EWhen:%20July%2024th,%202018%2012:35pm%3C/b%3E%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Ca%20href%3D%22https://cloud.withgoogle.com/next18/sf/sessions/session/156815%22%20target%3D%22_blank%22%3EA%20Year%20in%20GCP%20Networking%3C/a%3E%3Cbr%20/%3E%0A%3Cb%3E%3Ci%3ESpeakers:%20Srinath%20Padmanabhan,%20Networking%20Product%20Marketing%20Manager,%20Google%20Cloud%20and%20Nick%20Jacques,%20Lead%20Cloud%20Engineer,%20Target%3C/i%3E%3C/b%3E%3Cbr%20/%3E%0AIn%20this%20session,%20we%20will%20talk%20about%20the%20valuable%20advancements%20that%20have%20been%20made%20in%20GCP%20Networking%20over%20the%20last%20year.%20We%20will%20introduce%20you%20to%20the%20GCP%20Network%20team%20and%20will%20tell%20you%20about%20what%20you%20can%20do%20to%20extract%20the%20most%20value%20from%20your%20GCP%20Deployment.%3Cbr%20/%3E%0A%3Cb%3EWhen:%20July%2024th,%202018%201:55pm%3C/b%3E%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Ca%20href%3D%22https://cloud.withgoogle.com/next18/sf/sessions/session/156751%22%20target%3D%22_blank%22%3ECloud%20Load%20Balancing%20Deep%20Dive%20and%20Best%20Practices%3C/a%3E%3Cbr%20/%3E%0A%3Cb%3E%3Ci%3ESpeakers:%20Prajakta%20Joshi,%20Sr.%20Product%20Manager%20and%20Mike%20Columbus,%20Networking%20Specialist%20Team%20Manager%3C/i%3E%3C/b%3E%3Cbr%20/%3E%0AGoogle%20Cloud%20Load%20Balancing%20lets%20enterprises%20and%20cloud-native%20companies%20deliver%20highly%20available,%20scalable,%20low-latency%20cloud%20services%20with%20a%20global%20footprint.%20You%20will%20see%20demos%20and%20learn%20how%20enterprise%20customers%20deploy%20Cloud%20Load%20Balancing%20and%20the%20best%20practices%20they%20use%20to%20deliver%20smart,%20secure,%20modern%20services%20across%20the%20globe.%3Cbr%20/%3E%0A%3Cb%3EWhen:%20July%2025th,%202018%2012:35pm%3C/b%3E%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Ca%20href%3D%22https://cloud.withgoogle.com/next18/sf/sessions/session/156862%22%20target%3D%22_blank%22%3EHybrid%20Connectivity%20-%20Reliably%20Extending%20Your%20Enterprise%20Network%20to%20GCP%3C/a%3E%3Cbr%20/%3E%0A%3Cb%3E%3Ci%3ESpeaker:%20John%20Veizades,%20Product%20Manager,%20Google%20Cloud%3C/i%3E%3C/b%3E%3Cbr%20/%3E%0AIn%20this%20session,%20you%20will%20learn%20how%20to%20connect%20to%20GCP%20with%20highly%20reliable%20and%20secure%20networking%20to%20support%20extending%20your%20data%20center%20networks%20into%20the%20cloud.%20We%20will%20cover%20details%20of%20resilient%20routing%20techniques,%20access%20to%20Google%20API%20from%20on%20premise%20networks,%20connection%20locations,%20and%20partners%20that%20support%20connectivity%20to%20GCP%20--%20all%20designed%20to%20support%20mission-critical%20network%20connectivity%20to%20GCP.%3Cbr%20/%3E%0A%3Cb%3EWhen:%20July%2026th,%202018%2011:40am%3C/b%3E%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Ca%20href%3D%22https://cloud.withgoogle.com/next18/sf/sessions/session/156620%22%20target%3D%22_blank%22%3EVPC%20Deep%20Dive%20and%20Best%20Practices%3C/a%3E%3Cbr%20/%3E%0A%3Cb%3E%3Ci%3ESpeakers:%20Emanuele%20Mazza,%20Networking%20Product%20Specialist,%20Google,%20Neha%20Pattan,%20Software%20Engineer,%20Google%20and%20Kamal%20Congevaram%20Muralidharan,%20Senior%20Member%20Technical%20Staff,%20Paypal%3C/i%3E%3C/b%3E%3Cbr%20/%3E%0AThis%20session%20will%20walk%20you%20through%20the%20unique%20operational%20advantages%20of%20GCP%20VPC%20for%20your%20enterprise%20cloud%20deployments.%20We%E2%80%99ll%20go%20through%20detailed%20use%20cases,%20how%20to%20seal%20and%20audit%20your%20VPC,%20how%20to%20extend%20your%20VPC%20to%20on-prem%20in%20hybrid%20scenarios,%20and%20how%20to%20deploy%20highly%20available%20services.%3Cbr%20/%3E%0A%3Cb%3EWhen:%20July%2026th,%202018%209:00am%3C/b%3E%3Cbr%20/%3E%0A%3Cbr%20/%3E%0A%3Cbr%20/%3E%0ABe%20sure%20to%20reserve%20your%20spot%20in%20these%20sessions%20today%E2%80%94space%20is%20filling%20up!%0A%3Cdiv%3E%3Cimg%20src%3D%22https://www.google-analytics.com/collect?v%253D1%2526tid%253DUA-34322147-16%2526t%253Dpageview%2526cs%253Dgooglecloudplatform.blogspot.com%2526cm%253Dfeed%22%20/%3E%3C/div%3E)
Kubernetes wins OSCON Most Impact Award 19 Jul 2018 9:15 AM (6 years ago)
By Paris Pittman, Kubernetes Community Manager, Google
Today at the Open Source Awards at OSCON 2018, Kubernetes won the inaugural Most Impact Award, which recognizes a project that has had a ‘significant impact on how software is being written and applications are built’ in the past year. Thank you O’Reilly OSCON for the recognition, and more importantly, thank you to the vast Kubernetes community that has driven the project to where it is today.
When we released Kubernetes just four years ago, we never quite imagined how successful the project would be. We designed Kubernetes from a decade of experience running production workloads at Google, but we didn’t know whether the outside world would adopt it. However we believed that if we remained open to new ideas and new voices, the community would provide feedback and contributions to move the project forward to meet the needs of users everywhere.
This openness led to Kubernetes’ rapid adoption—and it’s also one of the core pillars of Google Cloud: our belief in an open cloud, so that you can pick-up and move your app wherever you want. Whether it’s Tensorflow, an open source library for machine learning, Asylo, a framework for confidential computing, or Istio, an open platform to connect microservices, openness remains a core value here at Google Cloud.
To everyone who has helped make Kubernetes the success it is today, many thanks again.
If you haven’t tried Kubernetes, it’s easy to get started with using Google Kubernetes Engine. If you’re interested to learn more about Kubernetes and the ecosystem it spawned, then subscribe to the Kubernetes Podcast from Google to hear weekly insights from leaders in the community.
VMware and Google Cloud: building the hybrid cloud together with vRealize Orchestrator 19 Jul 2018 8:00 AM (6 years ago)
By Shan Kulandaivel, Product Manager, Google Compute Engine
Many of our customers with hybrid cloud environments rely on VMware software on-premises. They want to simplify provisioning and enable end-user self service. At the same time, they also want to make sure they’re complying with IT policies and following IT best practices. As a result, many use VMware vRealize Automation, a platform for automated self-service provisioning and lifecycle management of IT infrastructure, and are looking for ways to leverage it in the cloud.
Today, we’re announcing the preview of our plug-in for VMware vRealize Orchestrator and support for Google Cloud Platform (GCP) resources in vRealize Automation. With these resources, you can now deploy and manage GCP resources from within your vRealize Automation environment.
The GCP plug-in for VMware vRealize Orchestrator provides a consistent management and governance experience across on-premises and GCP-based IT environments. For example, you can use Google-provided blueprints or build your own blueprints for Google Compute Engine resources and publish to the vRealize service catalog. This means you can select and launch resources in a predictable manner that is similar to how you launch VMs in your on-premises VMware environment, using a tool you’re already familiar with.
This preview release allows you to:
- Create vRealize Automation “blueprints” for Compute Engine VM Instances
- Request and self-provision resources in GCP using vRA’s catalog feature
- Gain visibility and reclaim resources in GCP to reduce operational costs
- Enforce access and resource quota policies for resources in GCP
- Initiate Day 2 operations (start, stop, delete, etc.) on Compute Engine VM Instances, Instance Groups and Disks
- Reach new regions to address global business needs. (Hello Finland, Mumbai and Singapore.)
- Define large-scale applications using vRA and deploy to Compute Engine to leverage GCP’s worldwide load balancing and automatic scaling.
- Save money by deploying VMs as Compute Engine Preemptible VM Instances and using Custom Machine Types to tailor the VM configuration to application needs.
- Accelerate the time it takes to train a machine learning model by using Compute Engine with NVIDIA® Tesla® P100 GPUs.
- Replicate your on premises-based applications to the cloud and scale up or down as your business dictates.
In the meantime, to join the preview program, please submit a request using the preview intake form.
SRE fundamentals: SLIs, SLAs and SLOs 19 Jul 2018 7:59 AM (6 years ago)
By Jay Judkowitz, Senior Product Manager and Mark Carter, Group Product Manager
Next week at Google Cloud Next ‘18, you’ll be hearing about new ways to think about and ensure the availability of your applications. A big part of that is establishing and monitoring service-level metrics—something that our Site Reliability Engineering (SRE) team does day in and day out here at Google. Our SRE principles have as their end goal to improve services and in turn the user experience, and next week we’ll be discussing some new ways you can incorporate SRE principles into your operations.
In fact, a recent Forrester report on infrastructure transformation offers details on how you can apply these SRE principles at your company—more easily than you might think. They found that enterprises can apply most SRE principles either directly or with minor modification.
To learn more about applying SRE in your business, we invite you to join Ben Treynor, head of Google SRE, who will be sharing some exciting announcements and walking through real-life SRE scenarios at his Next ‘18 Spotlight session. Register now as seats are limited.
The concept of SRE starts with the idea that metrics should be closely tied to business objectives. We use several essential tools—SLO, SLA and SLI—in SRE planning and practice.
Defining the terms of site reliability engineering
These tools aren’t just useful abstractions. Without them, you cannot know if your system is reliable, available or even useful. If they don’t tie explicitly back to your business objectives, then you don’t have data on whether the choices you make are helping or hurting your business.As a refresher, here’s a look at SLOs, SLAs, and SLIS, as discussed by AJ Ross, Adrian Hilton and Dave Rensin of our Customer Reliability Engineering team, in the January 2017 blog post, SLOs, SLIs, SLAs, oh my - CRE life lessons.
1. Service-Level Objective (SLO)
SRE begins with the idea that a prerequisite to success is availability. A system that is unavailable cannot perform its function and will fail by default. Availability, in SRE terms, defines whether a system is able to fulfill its intended function at a point in time. In addition to being used as a reporting tool, the historical availability measurement can also describe the probability that your system will perform as expected in the future.
When we set out to define the terms of SRE, we wanted to set a precise numerical target for system availability. We term this target the availability Service-Level Objective (SLO) of our system. Any discussion we have in the future about whether the system is running sufficiently reliably and what design or architectural changes we should make to it must be framed in terms of our system continuing to meet this SLO.
Keep in mind that the more reliable the service, the more it costs to operate. Define the lowest level of reliability that you can get away with for each service, and state that as your SLO. Every service should have an availability SLO—without it, your team and your stakeholders cannot make principled judgments about whether your service needs to be made more reliable (increasing cost and slowing development) or less reliable (allowing greater velocity of development). Excessive availability can become a problem because now it’s the expectation. Don’t make your system overly reliable if you don’t intend to commit to it to being that reliable.
Within Google, we implement periodic downtime in some services to prevent a service from being overly available. You might also try experimenting with planned-downtime exercises with front-end servers occasionally, as we did with one of our internal systems. We found that these exercises can uncover services that are using those servers inappropriately. With that information, you can then move workloads to somewhere more suitable and keep servers at the right availability level.
2. Service-Level Agreement (SLA)
At Google, we distinguish between an SLO and a Service-Level Agreement (SLA). An SLA normally involves a promise to someone using your service that its availability SLO should meet a certain level over a certain period, and if it fails to do so then some kind of penalty will be paid. This might be a partial refund of the service subscription fee paid by customers for that period, or additional subscription time added for free. The concept is that going out of SLO is going to hurt the service team, so they will push hard to stay within SLO. If you’re charging your customers money, you will probably need an SLA.
Because of this, and because of the principle that availability shouldn’t be much better than the SLO, the availability SLO in the SLA is normally a looser objective than the internal availability SLO. This might be expressed in availability numbers: for instance, an availability SLO of 99.9% over one month, with an internal availability SLO of 99.95%. Alternatively, the SLA might only specify a subset of the metrics that make up the internal SLO.
If you have an SLO in your SLA that is different from your internal SLO, as it almost always is, it’s important for your monitoring to measure SLO compliance explicitly. You want to be able to view your system’s availability over the SLA calendar period, and easily see if it appears to be in danger of going out of SLO. You will also need a precise measurement of compliance, usually from logs analysis. Since we have an extra set of obligations (described in the SLA) to paying customers, we need to measure queries received from them separately from other queries. That’s another benefit of establishing an SLA—it’s an unambiguous way to prioritize traffic.
When you define your SLA’s availability SLO, you need to be extra-careful about which queries you count as legitimate. For example, if a customer goes over quota because they released a buggy version of their mobile client, you may consider excluding all “out of quota” response codes from your SLA accounting.
3. Service-Level Indicator (SLI)
We also have a direct measurement of a service’s behavior: the frequency of successful probes of our system. This is a Service-Level Indicator (SLI). When we evaluate whether our system has been running within SLO for the past week, we look at the SLI to get the service availability percentage. If it goes below the specified SLO, we have a problem and may need to make the system more available in some way, such as running a second instance of the service in a different city and load-balancing between the two.
If you want to know how reliable your service is, you must be able to measure the rates of successful and unsuccessful queries as your SLIs.
Since the original post was published, we’ve made some updates to Stackdriver that let you incorporate SLIs even more easily into your Google Cloud Platform (GCP) workflows. You can now combine your in-house SLIs with the SLIs of the GCP services that you use, all in the same Stackdriver monitoring dashboard. At Next ‘18, the Spotlight session with Ben Treynor and Snapchat will illustrate how Snap uses its dashboard to get insight into what matters to its customers and map it directly to what information it gets from GCP, for an in-depth view of customer experience.
 |
| Automatic dashboards in Stackdriver for GCP services enable you to group several ways: per service, per method and per response code any of the 50th, 95th and 99th percentile charts. You can also see latency charts on log scale to quickly find outliers. |
If you’re building a system from scratch, make sure that SLIs and SLOs are part of your system requirements. If you already have a production system but don’t have them clearly defined, then that’s your highest priority work. If you’re coming to Next ‘18, we look forward to seeing you there.
See related content:
- We wrote the book on SRE—check it out
- Learn how SRE differs from DevOps
- Read about SLOs for services with dependencies
Bringing GPU-accelerated analytics to GCP Marketplace with MapD 19 Jul 2018 6:15 AM (6 years ago)
By Venkat Krishnamurthy, Vice President, Product, MapD

Editor’s note: Today, we hear from our partner MapD, whose data analytics platform uses GPUs to accelerate queries and visualizations. Read on to learn how MapD and Google Cloud are working together.
MapD and public cloud are a great fit. Combining cloud-based GPU infrastructure with MapD’s performance, interactivity and operational ease of use is a big win for our customers, allowing data scientists and analysts to visually explore billion-row datasets with fluidity and minimal hassle.
Our Community and Enterprise Edition images are available on AWS, MapD docker containers are available on NVIDIA GPU Cloud (NGC), as well as our own MapD Cloud. Today, we’re thrilled to announce the availability of MapD on Google Cloud Platform (GCP) Marketplace, helping us bring interactivity at scale to the widest possible audience. With services like Cloud DataFlow, Cloud BigTable and Cloud AI, GCP has emerged as a great platform for data-intensive workloads. Combining MapD and these services let us define scalable, high-performance visual analytics workflows for a variety of use cases.
On GCP, you’ll find both our Community and Enterprise editions for K80, Pascal and Volta GPU instances in the GCP Marketplace. Google’s flexible approach to attaching GPU dies to standard CPU-based instance types means you can dial up or down the necessary GPU capacity for your instances depending on the size of your datasets and your compute needs.
We’re confident that MapD’s availability on GCP marketplace will further accelerate the adoption of GPUs as a key part of enterprise analytics workloads, in addition to their obvious applicability to AI, graphics and general purpose computing. Click here to try out MapD on GCP.
,%20as%20well%20as%20our%20own%20MapD%20Cloud.%20Today,%20we%E2%80%99re%20thrilled%20to%20announce%20the%20availability%20of%20MapD%20on%20%3Ca%20href%3D%22https://console.cloud.google.com/marketplace/details/mapd-launcher-public/mapd-platform-enterprise-edition-p100%22%20target%3D%22_blank%22%3EGoogle%20Cloud%20Platform%20(GCP)%20Marketplace%3C/a%3E,%20helping%20us%20bring%20interactivity%20at%20scale%20to%20the%20widest%20possible%20audience.%20With%20services%20like%20Cloud%20DataFlow,%20Cloud%20BigTable%20and%20Cloud%20AI,%20GCP%20has%20emerged%20as%20a%20great%20platform%20for%20data-intensive%20workloads.%20Combining%20MapD%20and%20these%20services%20let%20us%20define%20scalable,%20high-performance%20visual%20analytics%20workflows%20for%20a%20variety%20of%20use%20cases.%20%3Cbr%20/%3E%0A%3Cbr%20/%3E%0AOn%20GCP,%20you%E2%80%99ll%20find%20both%20our%20Community%20and%20Enterprise%20editions%20for%20K80,%20Pascal%20and%20Volta%20GPU%20instances%20in%20the%20GCP%20Marketplace.%20Google%E2%80%99s%20flexible%20approach%20to%20attaching%20GPU%20dies%20to%20standard%20CPU-based%20instance%20types%20means%20you%20can%20dial%20up%20or%20down%20the%20necessary%20GPU%20capacity%20for%20your%20instances%20depending%20on%20the%20size%20of%20your%20datasets%20and%20your%20compute%20needs.%20%3Cbr%20/%3E%0A%3Cbr%20/%3E%0AWe%E2%80%99re%20confident%20that%20MapD%E2%80%99s%20availability%20on%20GCP%20marketplace%20will%20further%20accelerate%20the%20adoption%20of%20GPUs%20as%20a%20key%20part%20of%20enterprise%20analytics%20workloads,%20in%20addition%20to%20their%20obvious%20applicability%20to%20AI,%20graphics%20and%20general%20purpose%20computing.%20%3Ca%20href%3D%22https://console.cloud.google.com/marketplace/details/mapd-launcher-public/mapd-platform-enterprise-edition-p100%22%20target%3D%22_blank%22%3EClick%20here%3C/a%3E%20to%20try%20out%20MapD%20on%20GCP.%20%3Cdiv%3E%3Cimg%20src%3D%22https://www.google-analytics.com/collect?v%253D1%2526tid%253DUA-34322147-16%2526t%253Dpageview%2526cs%253Dgooglecloudplatform.blogspot.com%2526cm%253Dfeed%22%20/%3E%3C/div%3E)
Now shipping: ultramem machine types with up to 4TB of RAM 18 Jul 2018 8:00 AM (6 years ago)
By Hanan Youssef, Product Manager
Today we are announcing the general availability of Google Compute Engine “ultramem” memory-optimized machine types. You can provision ultramem VMs with up to 160 vCPUs and nearly 4TB of memory--the most vCPUs you can provision on-demand in any public cloud. These ultramem machine types are great for running memory-intensive production workloads such as SAP HANA, while leveraging the performance and flexibility of Google Cloud Platform (GCP).
The ultramem machine types offer the most resources per VM of any Compute Engine machine type, while supporting Compute Engine’s innovative differentiators, including:
- Live migration
- The ability to create preemptible instances for batch workloads
- Flexible, per-second billing
- Support for sustained use and committed use discounts
SAP-certified for OLAP and OLTP workloads
Since we announced our partnership with SAP in early 2017, we’ve rapidly expanded our support for SAP HANA with new memory-intensive Compute Engine machine types. We’ve also worked closely with SAP to test and certify these machine types to bring you validated solutions for your mission-critical workloads. Our supported VM sizes for SAP HANA now meet the broad range of Google Cloud Platform’s customers’ demands. Over the last year, the size of our certified instances grew by more than 10X for both scale-up and scale-out deployments. With up to 4TB of memory and 160 vCPUs, ultramem machine types are the largest SAP-certified instances on GCP for your OLAP and OLTP workloads. |
| Maximum memory per node and per cluster for SAP HANA on GCP, over time |
We also offer other capabilities to manage your HANA environment on GCP including automated deployments, and Stackdriver monitoring. Click here for a closer look at the SAP HANA ecosystem on GCP.
Up to 70% discount for committed use
We are also excited to share that GCP now offers deeper committed use discounts of up to 70% for memory-optimized machine types, helping you improve your total cost of ownership (TCO) for sustained, predictable usage. This allows you to control costs through a variety of usage models: on-demand usage to start testing machine types, committed use discounts when you are ready for production deployments, and sustained use discounts for mature, predictable usage. For more details on committed use discounts for these machine types check our docs, or use the pricing calculator to assess your savings on GCP.GCP customers have been doing exciting things with ultramem VMs
GCP customers have been using ultramem VMs for a variety of memory-intensive workloads including in-memory databases, HPC applications, and analytical workloads.Colgate has been collaborating with SAP and Google Cloud as an early user of ultramem VMs for S/4 HANA.
"As part of our partnership with SAP and Google Cloud, we have been an early tester of Google Cloud's 4TB instances for SAP solution workloads. The machines have performed well, and the results have been positive. We are excited to continue our collaboration with SAP and Google Cloud to jointly create market changing innovations based upon SAP Cloud Platform running on GCP.”
- Javier Llinas, Vice President, GIT, Colgate
Getting started
These ultramem machine types are available in us-central1, us-east1, and europe-west1, with more global regions planned soon. Stay up-to-date on additional regions by visiting our available regions and zones page.It’s easy to configure and provision n1-ultramem machine types programmatically, as well as via the console. To learn more about running your SAP HANA in-memory database on GCP with ultramem machine types, visit our SAP page, and go to the GCP Console to get started.
Improving our account management policies to better support customers 18 Jul 2018 8:00 AM (6 years ago)
By Ben Treynor Sloss, VP 24x7
Recently, a Google Cloud Platform (GCP) customer blogged about an incident in June, in which a project they were running on Google Cloud Platform was suspended. We really appreciated the candid feedback, in which our customer noted several aspects of our account management process which needed to be improved. We also appreciated our customer’s followup and recognition of the Google Cloud support team, “who have reached out and assured us these incidents will not repeat.”
Here’s what we are doing to be as good as our word, and provide a more careful, accurate, thoughtful and empathetic account management experience for our GCP customers. These changes are intended to provide peace of mind and a predictable, positive experience for our GCP customers, while continuing to permit appropriate suspension and removal actions for the inevitable bad actors and fraud which are a part of operating a public cloud service.
No Automatic Fraud-Based Account Suspensions for Established Customers with Offline Payment. Established GCP customers complying with our Acceptable Use Policy (AUP, TOS and local laws), with an offline billing contract, invoice billing, or an active relationship with our sales team, are not subject to fraud-based automatic account suspension.
Delayed Suspension for Established Online Customers. Online customers with established payment history, operating in compliance with our TOS, AUP and local laws, will receive advance notification and a 5 day cure period in the event that fraud or account compromise activity is detected in their projects.
Other Customers. For all other customers, we will institute a second human review for flagged fraud accounts prior to suspending an account. We’re also modifying who has authority to suspend an account, as well as refreshing our training for the teams that review flagged accounts and determine response actions; re-evaluating the signals, sources, and the tools we use to assess potential fraudulent activity; and increasing the number of options we can use to help new customers quickly and safely grow their usage while building an account history with Google.
In addition to the above, for all customers we are making the following improvements:
24X7 Chat Support. We are rolling out 24X7 chat support for customers that receive account notices, so that customers can always reach us easily. We expect this to be fully rolled out for all customers by September.
Correcting Notices About our 30 Day Policy. Our customer noted, with appropriate concern, that their suspension email stated “we will delete your account in 3 days.” This language was simply incorrect -- our fraud suspension policy provides 30 days before removal. We have corrected the communication language, and we are conducting a full review of our communication verbiage and systems and ensuring that our messages are accurate and clear.
Updating Our Project Suspension Guidelines. We will review and update our project suspension guidelines to clarify our practices and describe what you should expect from Google.
Improving Customer Contact Points. We will encourage customers to provide us with a verifiable phone number, email, and other contact channels, both at sign-up and at later points in time, so that we can quickly contact you if we detect suspicious activity on your account.
Creating Customer Pre-Verification. We will provide ways for customers to pre-verify their accounts with us if they desire, either at sign-up or at a later point in time.
These suspensions are our responsibility.There are also steps that customers can take to help us protect their accounts including:
- Make sure to monitor emails sent to your payments and billing contacts so you don’t miss important alerts.
- Provide a valid phone number where we can reach you in the event of suspicious activity on your account.
- Provide one or more billing admins to your account.
- Provide a secondary payment method in case there are problems charging your primary method.
- Contact our sales team to see if you qualify for invoice billing instead of relying on credit cards.
We sincerely apologize to all our customers who’ve been concerned or had to go through a service reinstatement. Please keep the feedback coming, we’ll work to continue to earn your trust every day.
Top storage and database sessions to check out at Next 2018 18 Jul 2018 5:00 AM (6 years ago)
Whatever your particular area of cloud interest, there will be a lot to learn at Google Cloud Next ‘18 (July 24-26 in San Francisco). When it comes to cloud storage and databases, you’ll find useful sessions that can help you better understand your options as you’re building the cloud infrastructure that will work best for your organization.
Here, we’ve chosen five not-to-miss sessions, where you’ll learn tips on migrating data to the cloud, understand types of cloud storage workloads and get a closer look at which database is best for storing and analyzing your company’s data. Wherever you are in your cloud journey, there’s likely a session you can use.
Top cloud storage sessions
First up, our top picks for those of you delving into cloud storage.
From Blobs to Tables, Where to Store Your Data
Speakers: Dave Nettleton, Robert Saxby
What’s the best way to store all the data you’re creating and moving to the cloud? The answer depends on the industry, apps and users you’re supporting. Google Cloud Platform (GCP) offers many options for storing your data. The choices range from Cloud Storage (multi-regional, regional, nearline, coldline) through Persistent Disk to various database services (Cloud Datastore, Cloud SQL, Cloud Bigtable, Cloud Spanner) and data warehousing (BigQuery). In this session, you’ll learn about the products along with common application patterns that use data storage.
Why attend: With much to consider and many options available, this session is a great opportunity to examine which storage option fits your workloads.
Caching Made Easy, with Cloud Memorystore and Redis
Speaker: Gopal Ashok
In-memory database Redis has plenty of developer fans: It’s high-performance and highly available, making it an excellent choice for caching operations. Cloud Memorystore now includes a managed Redis service. In this session, you’ll hear about its new features. You’ll also learn how you can easily migrate applications using Redis to Cloud Memorystore with minimal changes.
Why attend: Are you building an application that needs sub-millisecond response? GCP provides fully managed service for the popular Redis in-memory datastore.
Google Cloud Storage - Best Practices for Storage Classes, Reliability, Performance and Scalability
Speakers: Geoff Noer, Michael Yu
Learn about common Google Cloud Storage workloads, such as content storage and serving, analytics/ML and data protection. Understand how to choose the best storage class, depending on what kind of data you have and what kind of workload you're supporting. You’ll also learn more about Multi-Regional, Regional, Nearline and Coldline storage.
Why attend: You’ll learn about ways to optimize Cloud Storage to the unique requirements of different storage use cases.
Top database sessions
Here are our top picks for database sessions to explore at Next ‘18.
Optimizing Applications, Schemas, and Query Design on Cloud Spanner
Speaker: Robert Kubis
Cloud Spanner was designed specifically for cloud infrastructure and scales easily to allow for efficient cloud growth. In this session, you’ll learn Cloud Spanner best practices, strategies for optimizing applications and workloads, and ways to improve performance and scalability. Through live demos, you’ll see real-time speed-ups of transactions, queries and overall performance. Additionally, this talk explores techniques for monitoring Cloud Spanner to identify performance bottlenecks. Come learn how to cut costs and maximize performance with Cloud Spanner.
Why attend: Cloud Spanner is a powerful product, but many users do not maximize its benefits. You’ll get an inside look at this session at getting the best performance and efficiency results out of this type of cloud database.
Optimizing performance on Cloud SQL for MySQL
Speakers: Stanley Feng, Theodore Tso, Brett Hesterberg
Database performance tuning can be challenging and time-consuming. In this session, you’ll get a look at the performance tuning our team has conducted in the last year to considerably improve Cloud SQL for MySQL. We’ll also highlight useful changes to the Linux kernel, EXT4 filesystem and Google's Persistent Disk storage layer to improve write performance. You'll come away knowing more about MySQL performance tuning, an underused EXT4 feature called “bigalloc” and how to let Cloud SQL handle mundane, yet necessary, tasks so you can focus on developing your next great app.
Why attend: When GCP provides fully managed services for databases, we put lots of innovations under the hood, so that your database runs in the most optimal way. Come and learn about Google’s secret sauce that lets you optimize Cloud SQL performance.
Check out the full list of Next sessions, and join your peers at the show by registering here.
Introducing commercial Kubernetes applications in GCP Marketplace 18 Jul 2018 5:00 AM (6 years ago)
By Anil Dhawan, Product Manager, Google Cloud Platform
Building, deploying and managing applications with Kubernetes comes with its own set of unique challenges. Today, we are excited to be the first major cloud provider to offer production-ready commercial Kubernetes apps right from our marketplace, bringing you simplified deployment, billing, and third-party licensing.
Now you can find the solution you need in Google Cloud Platform Marketplace (formerly Cloud Launcher) and deploy quickly on Kubernetes clusters running on Google Cloud Platform (GCP), Kubernetes Engine, on-prem, or even other public clouds.
Enterprise-ready containerized applications - We are on a mission to make containers accessible to everyone, especially the enterprise. When we released Kubernetes as open source, one of the first challenges that the industry tackled was management. Our hosted Kubernetes Engine takes care of cluster orchestration and management, but getting apps running on a Kubernetes cluster can still be a manual, time-consuming process. With GCP Marketplace, you can now easily find prepackaged apps and deploy them onto the cluster of your choice.
Simplified deployments - Kubernetes apps are configured to get up and running fast. Enjoy click-to-deploy to Kubernetes Engine, or deploy them to other Kubernetes clusters off-GCP. Now, deploying from Kubernetes Engine is even easier, with a Marketplace window directly in the Kubernetes Engine console.
Production-ready security and reliability - All Kubernetes apps listed on GCP Marketplace are tested and vetted by Google, including vulnerability scanning and partner agreements for maintenance and support. Additionally, we work with open-source Special Interest Groups (SIGs) to create standards for Kubernetes apps, bringing the knowledge of the open-source community to your enterprise.
Supporting hybrid environments - One of the great things about containers is their portability across environments. While Kubernetes Engine makes it easy to click-to-deploy these apps, you can also deploy them in your other Kubernetes clusters—even if they’re on-premises. This lets you use the cloud for development and then move your workloads to your production environment, wherever it may be.
Commercial Kubernetes applications available now
Our commercial Kubernetes apps, developed by third-party partners, support usage-based billing on many parameters (API calls, number of hosts, storage per month), simplifying license usage and giving you more consumption options. Further, the usage charges for your apps are consolidated and billed through GCP, no matter where they are deployed (not including any non-GCP resources they need to run on).
“Cloud deployment and manageability are core to Aerospike's strategy. GCP Marketplace makes it simpler for our customers to buy, deploy and manage Aerospike through Kubernetes Engine with one-click deployment. This provides a seamless experience for customers by allowing them to procure both Aerospike solutions and Kubernetes Engine on a single, unified Google bill and providing them with the flexibility to pay as they go.”
- Bharath Yadla, VP-Product Strategy, EcoSystems, Aerospike
"As an organization focused on supporting enterprises with security for their container-based applications, we are delighted that we can now offer our solutions as commercial Kubernetes application more simply to customers through the GCP Marketplace commercial Kubernetes application option. GCP Marketplace helps us reach GCP customers, and the one-click deployment of our applications to Google Kubernetes Engine makes it easier for enterprises to use our solution. We are also excited about GCP’s commitment to enterprise agility by allowing our solution to be deployed on-premises, letting us reach enterprises where they are today."
- Upesh Patel, VP Business Development, Aqua Security
“Couchbase is excited to see GCP Marketplace continue the legacy of GCP by bringing new technologies to market. We've seen GCP Marketplace as a key part of our strategy in reaching customers, and the new commercial Kubernetes application option differentiates us as innovators for both prospects and customers."
-Matt McDonough, VP of Business Development, Couchbase
"With the support for commercial Kubernetes applications, GCP Marketplace allows us to reach a wider range of customers looking to deploy our graph database both to Google Kubernetes Engine and hybrid environments. We're excited to announce our new offering on GCP Marketplace as a testament to both Neo4j and Google's innovation in integrations to Kubernetes."
- David Allen, Partner Solution Architect, Neo4j
Popular open-source Kubernetes apps available now
In addition to our new commercial offerings, GCP Marketplace already features popular open-source projects that are ready to deploy into Kubernetes. These apps are packaged and maintained by Google Cloud and implement best practices for running on Kubernetes Engine and GCP. Each app includes clustered images and documented upgrade steps, so it’s ready to run in production.
One-stop shopping on GCP Marketplace
As you may have noticed, Google Cloud Launcher has been renamed to GCP Marketplace, a more intuitive name for the place to discover the latest partner and open source solutions. Like Kubernetes apps, we test and vet all solutions available through the GCP Marketplace, which include virtual machines, managed services, data sets, APIs, SaaS, and more. In most instances, we also recommend Marketplace solutions for your projects.With GCP Marketplace, you can verify that a solution will work for your environment with free trials from select partners. You can also combine those free trials with our $300 sign-up credit. Once you’re up and running, GCP Marketplace supports existing relationships between you and your partners with private pricing. Private pricing is currently available for managed services, and support for more solution types will be rolling out in the coming months.
Get started today
We’re excited to bring support for Kubernetes apps to you and our partners, featuring the extensibility of Kubernetes, commercial solutions, usage-based pricing, and discoverability on the newly revamped GCP Marketplace.- Visit the GCP Marketplace and check out the new Kubernetes apps—there’s no signup required to view the full list of available solutions!
- If you are attending Next ‘18 in San Francisco next week, come to our session to learn how customers are developing faster using GCP Marketplace.
Cloud Spanner adds import/export functionality to ease data movement 17 Jul 2018 8:00 AM (6 years ago)
By Deepti Srivastava, Product Manager, Cloud Spanner
We launched Cloud Spanner to general availability last year, and many of you shared in our excitement: You explored it, started proof-of-concept trials, and deployed apps. Perhaps most importantly, you gave us feedback along the way. We heard you, and we got to work. Today, we’re happy to announce we’ve launched one of your most commonly requested features: importing and exporting data.
Import/export using Avro
You asked for easier ways to move data. You’ve got it. You can now import and export data easily in the Cloud Spanner Console:- Export any Cloud Spanner database into a Google Cloud Storage (GCS) bucket.
- Import files from a GCS bucket into a new Cloud Spanner database.
Adding imports and exports opens up even more possibilities for your Cloud Spanner data, including:
- Disaster recovery: Export your database at any time and store it in a GCS location of your choice as a backup, which can be imported into a new Cloud Spanner database to restore data.
- Testing: Export a database and then import it into Cloud Spanner as a dev/test database to use for integration tests or other experiments.
- Moving databases: Export a database and import it back into Cloud Spanner in a new/different instance with the console’s simple, push-button functionality.
- Ingest for analytics: Use database exports to ingest your operational data to other services such as BigQuery, for analytics. BigQuery can automatically ingest data in Avro format from a GCS bucket, which means it will become easier for you to run analytics on your operational data.
We're excited to see the ways that Cloud Spanner—making application development more efficient, simplifying database administration and management, and providing the benefits of both relational and scale-out, non-relational databases—will continue to help you ship better apps, faster.
Our Los Angeles cloud region is open for business 16 Jul 2018 8:00 AM (6 years ago)
By Kirill Tropin, Product Manager
Hey, LA — the day has arrived! The Los Angeles Google Cloud Platform region is officially open for business. You can now store data and build highly available, performant applications in Southern California.
Los Angeles Mayor Eric Garcetti said it best: “Los Angeles is a global hub for fashion, music, entertainment, aerospace, and more—and technology is essential to strengthening our status as a center of invention and creativity. We are excited that Google Cloud has chosen Los Angeles to provide infrastructure and technology solutions to our businesses and entrepreneurs.”

The LA cloud region, us-west2, is our seventeenth overall and our fifth in the United States.
Hosting applications in the new region can significantly improve latency for end users in Southern California, and by up to 80% across Northern California and the Southwest, compared to hosting them in the previously closest region, Oregon. You can visit www.gcping.com to see how fast the LA region is for you.
Services
The LA region has everything you need to build the next great application:

Of note, the LA region debuted with one of our newest products: Cloud FilestoreBETA, our managed file storage service for applications that require a filesystem interface and a shared filesystem for data.
The region also has three zones, allowing you to distribute apps and storage across multiple zones to protect against service disruptions. You can also access our multi-regional services (such as BigQuery) in the United States and all the other GCP services via our Google Network, and combine any of the services you deploy in LA with other GCP services around the world. Please visit our Service Specific Terms for detailed information on our data storage capabilities.
Google Cloud Network
Google Cloud’s global networking infrastructure is the largest cloud network as measured by number of points of presence. This private network provides a high-bandwidth, highly reliable, low-latency link to each region across the world. With it, you can reach the LA region as easily as any region. In addition, the global Google Cloud Load Balancing makes it easy to deploy truly global applications.Also, if you’d like to connect to the Los Angeles region privately, we offer Dedicated Interconnect at two locations: Equinix LA1 and CoreSite LA1.
LA region celebration
We celebrated the launch of the LA cloud region the best way we know how: with our customers. At the celebration, we announced new services to help content creators take advantage of the cloud: Filestore, Transfer Appliance and of course, the new region itself, in the heart of media and entertainment country. The region’s proximity to content creators is critical for cloud-based visual effects and animation workloads. With proximity comes low latency, which lets you treat the cloud as if it were part of your on-premises infrastructure—or even migrate your entire studio to the cloud. |
| Paul-Henri Ferrand, President of Global Customer Operations, officially announces the opening of our Los Angeles cloud region. |
What customers are saying

“Google Cloud Platform already works seamlessly with our on-premise infrastructure, allowing us to meet increased compute demands. Now, with the LA cloud region, it’s like having a render farm at our doorstep.”
- Steve Kowalski, Vice President of Systems Engineering, Sony Pictures Imageworks
“Using Google Cloud for visual effects rendering gives us the scalability and flexibility we need to turn around jobs in a fraction of the time that it used to. We look forward to using the LA cloud region for even faster speed. Our artists can work efficiently and effectively to truly innovate and evolve the story, art, and technology of the moving image.”
- Saker Klippsten, Chief Technology Officer, Zoic Studios
“Google Cloud makes the City of Los Angeles run more smoothly and efficiently to better serve Angelenos city-wide. We are very excited to have a cloud region of our own that enables businesses, big or small, to leverage the latest cloud technology and foster innovation.”
- Ted Ross, General Manager and Chief Information Officer for City of LA Information Technology Agency, City of LA


“Using Google Cloud for visual effects rendering enables our team to be fast, flexible and to work on multiple large projects simultaneously without fear of resource starvation. Cloud is at the heart of our IT strategy and Google provides us with the rendering power to create Oscar-winning graphics in post-production work.”
- Steve MacPherson, Chief Technology Officer, Framestore

“A lot of our short form projects pop up unexpectedly, so having extra capacity in region can help us quickly capitalize on these opportunities. The extra speed the LA region gives us will help us free up our artists to do more creative work. We’re also expanding internationally, and hiring more artists abroad, and we’ve found that Google Cloud has the best combination of global reach, high performance and cost to help us achieve our ambitions.”
- Tom Taylor, Head of Engineering, The Mill
What SoCal partners are saying
Our partners are available to help design and support your deployment, migration and maintenance needs.

“Cloud and data are the new equalizers, transforming the way organizations are built, work and create value. Our premier partnership with Google Cloud Platform enables us to help our clients digitally transform through efforts like app modernization, data analytics, ML and AI. Google’s new LA cloud region will enhance the deliverability of these solutions and help us better service the LA and Orange County markets - a destination where Neudesic has chosen to place its corporate home.”
- Tim Marshall, CTO and Co-Founder, Neudesic

“Enterprises everywhere are on a journey to harness the power of cloud to accelerate business objectives, implement disruptive features, and drive down costs. The Taos and Google Cloud partnership helps companies innovate and scale, and we are excited for the new Google Cloud LA region. The data center will bring a whole new level of uptime and service to our Southern California team and clients.”
- Hamilton Yu, President and COO, Taos

“As a launch partner for Google Cloud and multi-year recipient of Google’s Partner of the Year award, we are thrilled to have Google’s new cloud region in Los Angeles, our home base and where we have a strong customer footprint. SADA Systems has a track record of delivering industry expertise and innovative technical services to customers nationwide. We are excited to leverage the scale and power of Google Cloud along with SADA’s expertise for our clients in the Los Angeles area to continue their cloud transformation journey.”
- Tony Safoian, CEO & President, SADA Systems
Getting started
For additional details on the LA region, please visit our LA region page where you’ll get access to free resources, whitepapers, the "Cloud On-Air" on-demand video series and more. Our locations page provides updates on the availability of additional services and regions. Contact us to request early access to new regions and help us prioritize where we build next.