Recover the Database in SQL SERVER 10 Jan 2011 1:01 AM (15 years ago)
1.create the Database with same Name,MDF Name,LDF Name.
2.Stop the Sql Server and then Replace the only new MDF file by old database (Corrupted database) MDF file and delete the LDF File of newly created database.
3.Now Start the Sql Server again.
4.you can notice that database status became 'Suspect' as expected.
5.Then run the given script to know the current status of your newly created datatbase.
(Better you note it down the current status)
SELECT *
FROM sysdatabases
WHERE name = 'yourDB'
6.Normally sql server would not allow you update anything in the system database.SO run the given script to enable the update to system database.
sp_CONFIGURE 'allow updates', 1
RECONFIGURE WITH OVERRIDE
7.After run the above script, update the status of your newly database as shown below. once you updated the status, database status become 'Emergency/Suspect'.
UPDATE sysdatabases
SET status = 32768
WHERE name = 'yourDB'
8.Restart SQL Server (This is must, if it is not done SQL Server will through an error)
9.Execute this DBCC command to create the LDF file.make sure the Name of LDF file which you are giveing is same as deleted LDF file of Newly Created database.
DBCC TRACEON (3604)
DBCC REBUILD_LOG(bmpos,'D:\yourDB_Log.ldf')
DBCC accepts two parameters,
1. parameter is database name and
2. parameter is physical path (where the MDF file is located) of the log file. (*Make sure the path is physical, if you specify the logical file name it will throw an error.)
10.Run the given stored procedure to reset the status of your database.
sp_RESETSTATUS yourDB
11.Do not forget to disable theallow update to system datatbase.
sp_CONFIGURE 'allow updates',0
RECONFIGURE WITH OVERRIDE
12.At last, update the status which you have noted in the 5th step.
UPDATE sysdatabases
SET status = 1073741840
WHERE name = 'yourDB'
Note : During steps 8, 9 , 10 you may encounter any errors if database is in use.
in this case you Set the database to single user.
sp_DBOPTION 'yourDB', 'single user','true'
Once the steps 8,9,10 are completed and database is already single user mode, then run this script.
sp_DBOPTION 'yourDB', 'single user','false'









Reflect in the view after Edited or Newly Added column of a Table 9 Jan 2011 10:14 PM (15 years ago)
 After changed the name or add new column in the table, that changes would not reflect in the view if that field used in that view.
After changed the name or add new column in the table, that changes would not reflect in the view if that field used in that view.
For that you just run this system stored procedure with view name as parameter rather open the view and update it.
Sp_refreshview yourviewname
For an Example:
I am using Table_A, Table_B and View_C


In the View C I have used Table A and Table B.

After created the View C I added one more column call Status in the Table A and run the View C, you would not see that newly added column as view have not been refreshed yet as shown below.

For this you can simply update the view just using the above stored procedure as shown below,
Sp_refreshview View_C
After run the script you can able to see that added column in the view as shown below,


How get the column names from a particular Table in Oracle 23 Jun 2010 11:20 PM (15 years ago)
In Oracle you can retreive the field names as shown below,
DESC Table_Name
How to get the position of a character from a word in SQL server. 19 Jun 2010 9:05 AM (15 years ago)
For this there is a function call CHARINDEX(). This is very similar to InStr function of VB.NET and IndexOf in Java. This function returns the position of the first occurrence of the first argument in the record.
SELECT CHARINDEX('r','server')
This would return 3 as it is start from 1.
Working with Cursors in SQL Server. 19 Jun 2010 9:01 AM (15 years ago)
Cursors are useful thing in SQL as it is enable you to work with a subset of data on a row-by-row basis. All cursor functions are non-deterministic because the results might not always be consistent. A user might delete a row while you are working with your cursor. Here after a few functions that work with cursors.
When you work with Cursor , you will Have to follow these steps .
1. Declare Cursor
2. Open Cursor
3. Run through the cursor
4. Close Cursor
5. Deallocate the Cursor
1. Declare cursor
Declare Emp_Cur Cursor For
Select Emp_Code From Employee_Details
Declare the cursor with select query for a Table/View as shown above.
2. Open Cursor
Open Emp_Cur
Fetch Next From Emp_Cur
Into @mCardNo
Open the Declared cursor and Fetch them into declared local variables for row-by-row basis.
In given example, open cursor Emp_Cur and Fetch the Emp_Code records and assigned into a local Variable called @mCardNo.
3. Run through the Cursor
For this there is a Cursor function called @@FETCH_STATUs which is a scalar function that works with cursors.
If @@FETCH_STATUS=0 means cursor doesn’t have more records to read otherwise it would be nonzero. Normally we would use this with while loop (While @@FETCH_STATUS=0).
While @@Fetch_Status=0
Begin
----
--You can write you statements here for update/Insert
----
Fetch Next From Emp_Cur
Into @mCardNo
End
Another cursor function is @@CURSOR_ROWS which would returns the number rows in the most recently opened cursor.
4. Close the Cursor.
Once you completed the cursor run through you must close the cursor otherwise when open it again SQL would throw an error.
Close Emp_Cur
5. Deallocate the Cursor
This this for erase the declared cursor from memory as it would consume considerable memory space.
Deallocate Emp_Cur
The full script for Cursor, ( for run this script you must have a table call Employee_Details)
Declare @mCardNo as Varchar(10)
Declare Emp_Cur Cursor For
Select Emp_Code From Employee_Details
Open Emp_Cur
Fetch Next From Emp_Cur
Into @mCardNo
While @@Fetch_Status=0
Begin
----
--You can write you statements here for update/Insert
----
Fetch Next From Emp_Cur
Into @mCardNo
End
Close Emp_Cur
Deallocate Emp_Cur
Working with Stored Procedures 19 Jun 2010 8:50 AM (15 years ago)
Stored procedures are stored in SQL Server databases. The simplest implication of stored procedures is to save complicated queries to the database and call them by name, so that users won’t have to enter
the SQL statements more once. As you see, stored procedures have many more applications, and you can even use them to build business rules into the database.
How to create a Stored Procedure,
As shown given below, created a Stored Procedure for Inserting records into Table call Holiday_Details, which has Code and Description fields.
In this Stored Procedure, passing two parametrs as INPUT Parameters and one OUTPUT parameter.
Normally in Stored Procedure we can pass parameters as Input / Output Stored parameters. When you define output parameters, we have to implicitly specify the OUTPUT Keyword.
Here I have shown the simple stored procedure.
CREATE PROCEDURE [dbo].[SP_Holiday]
@Code char(3),
@Desc varchar(100),
@flag bit,
@Err Varchar(MAX)=Null OUTPUT
AS
Begin Transaction
if @flag=0
begin
INSERT INTO Holiday_Details Values(@code,@Desc)
end
if @flag=1
begin
UPDATE Holiday_Details SET Description=@Desc WHERE Code=@code
end
If @@ERROR <>0
Begin
Set @Err=cast(@@Error as varchar(max))
Rollback Transaction
print @Err
return
End
Else if @@ERROR<>0
Begin
Set @Err='Successfully done!!'
print @Err
End
Commit Transaction
Here we are trying Insert/Update the records into Holiday_Details. For diferentiate the Insert and Update, we are using @flag input parameter. So when we execute this parameter we should specify the @flag whether it is Insert/Update.
@Err parametr is Output parameter for get the status of execution whether it is successfully Inserted/Updated or thrown any error.
So, if you execute this procedure, you would get the output of status.
Execute of a Stored Procedure
When you execute a Stored Procedure, you have to use either Execute/EXEC
(Exec is special case, I will explain about in another article) keyword for execute the Stored Procedure.
EXEC SP_Holiday 'bb1','ffff',0
EXECUTE SP_Holiday '332','ffff',0
Here we have not pased value for OUTPUT parameter since we have assined Null as intial value which means in case if you forget topass the paraneter, Variable would take the Intialized value.
So, once you run this stored Procedure, this would return the value of @Err parameter.
Main purposes of Using Stored Procedures
When as SQL statement, especially a complicated one, is stored in the database as stored procedure, its execution plan is designed once, cached, and is ready to be used again.
Moreover, stored procedures can be designed once, tested, and used by many usres and applications. If the same stored procedure is used by more than user, the DBMS keeps only one copy of the procedure in memory, and all users share the same instance of the procedure. This means more efficient memory utilization.
Finally, you can limit user access to database’s tables and force users to access the database throgh stored procedures. This is simple method of enforcing business rules.
Use of Begin, Commit, Rollback Transactions in SQL Server 30 May 2010 8:03 AM (15 years ago)
 The SQL Server provides very useful feature which is Begin, Commit, Rollback Transaction.
The SQL Server provides very useful feature which is Begin, Commit, Rollback Transaction.
When we use Begin Transaction before we use DML Queries, we can Commit or Rollback that Transaction after the confirmation. This is very useful if you update anything wrongly then you can rollback that transaction.
For example,As shown below, I am trying to update the NodeID column data to 5 from 1.
begin transaction
update DownLoad_Data set NodeID=5
But after I updated, You can check whether you have been updated properly. But here, I realised I did not mention the Where clause.
select * from DownLoad_Data

So I have to rollback this transaction. For that I can use Rollback Transaction since I used Begin Transaction.
Rollback transaction
So again I changed the Query and run it.
Begin transaction
update DownLoad_Data set NodeID=5 where RecNo=1
Still you can check whether have been updated properly. If it is updated correctly then, Run the Commit Transaction to make all updates permanently.

Commit Transaction
I hope this would have been very useful for you all.
SQL SERVER – TRIM() Function – UDF TRIM() 29 May 2010 6:37 PM (15 years ago)
SQL Server does not have Trim() function. So we can create a own UDF (User Defined Function) function for this since SQL Sever does LTRIM(),RTRIM() functions and we can use this any time.
Here I have created a simple Function for this.
Create Function Trim(@mText varchar(MAX))
Returns varchar(MAX)
AS
Begin
return LTRIM(RTRIM(@mText))
End
You can run this function as shown below here,
Select dbo.Trim(' Test ')
So this function would return ‘Test’ only as LTRIM() function would cut off the Left side spaces and RTRIM() functiom would cut off the Right side spaces.
SQL Script for take backup of Database in sql server 7 May 2010 8:36 AM (15 years ago)

In sql server there are 2 built-in stored procedures for drop the already existing backup device and create the new device in the user defined path.
Before create the backup device, must drop the device. Because when you create a backup device, if backup device had already been created, sql server throw a error. So very first time have to create a backup device manually.
Afterwards you can use this script.
This is very use ful as user can take backup where user wants it since this procedure takes the path as parameter.
Create Backup device manually in Sql Server 2008
Go to Server Object where right click on Backup Device, Then choose New Backup Device. if you choose that, sql server let you to create the New Backup Device.
(Please refer the figures as shown below)
 Figure 2
Figure 2 Figure 3
Figure 3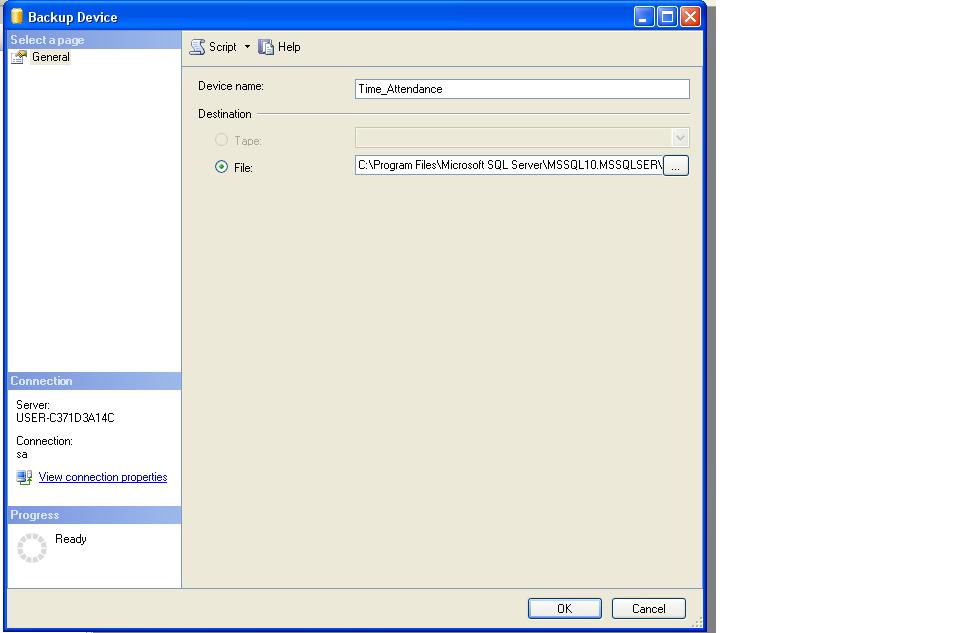
Figure 4
 Figure 5
Figure 5
Script for Drop the Backup Device
EXEC sp_dropdevice 'Time_Attendance'
Script for Create the Backup Device
EXEC sp_addumpdevice 'disk', 'Time_Attendance', @Path
Script for initializes the backup with user specified name
BACKUP DATABASE Time_Attendance
TO Time_Attendance with name= @Name, INIT
%3Cbr%20/%3E%3Cbr%20/%3E%3Cdiv%3E%3Cb%3EFigure%201%3C/b%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhfvqRN59b21qfH1VYJBsu42ufijAhJwK2mEvXwe7ZFXT4bybSey8oFrpf1SSNX_DI6SjUy85bvDkAo1P6UyW-O4C-CsNEIhnck6-EbBJyRa68mu_Z4FF7OYFurBfWicpZguThaTBDpg5WS/s1600/BackupDevice2.JPG%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%20249px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhfvqRN59b21qfH1VYJBsu42ufijAhJwK2mEvXwe7ZFXT4bybSey8oFrpf1SSNX_DI6SjUy85bvDkAo1P6UyW-O4C-CsNEIhnck6-EbBJyRa68mu_Z4FF7OYFurBfWicpZguThaTBDpg5WS/s400/BackupDevice2.JPG%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5468573398362317282%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cb%3EFigure%202%3C/b%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi6ciJY41BeKch7ksKaKaj0Ma0u3Hlwyc-oCw3hIedcAIVdq_UNfl0QfqTMbdLYvmf1YjwqqZvK_LqrnUZxFmU_VSK1MxbIVWqdZdZOxsMbMQxfpEj7kOd383-gD7BUDdu6nCKj1PhcyNIy/s1600/BackupDevice1.JPG%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%20250px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi6ciJY41BeKch7ksKaKaj0Ma0u3Hlwyc-oCw3hIedcAIVdq_UNfl0QfqTMbdLYvmf1YjwqqZvK_LqrnUZxFmU_VSK1MxbIVWqdZdZOxsMbMQxfpEj7kOd383-gD7BUDdu6nCKj1PhcyNIy/s400/BackupDevice1.JPG%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5468573064344793890%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cb%3EFigure%203%3C/b%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhnNVAtAY8nyQ0E-2grSzPXDd6EBHIaBFaXw3CvfT9bmyKreffHyJXRKllhsRA8Y6XfdsQisAQ0ToO-k5ZvZtaySbjCtGNDZLEVyW2V78KXicPoo5CTpWGILlBxTk2hbHS56L8lbqN5SRoY/s1600/BackupDevice3.JPG%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%20260px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhnNVAtAY8nyQ0E-2grSzPXDd6EBHIaBFaXw3CvfT9bmyKreffHyJXRKllhsRA8Y6XfdsQisAQ0ToO-k5ZvZtaySbjCtGNDZLEVyW2V78KXicPoo5CTpWGILlBxTk2hbHS56L8lbqN5SRoY/s400/BackupDevice3.JPG%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5468573573605185090%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cb%3EFigure%204%3C/b%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFCm63tCNMm6-zse1PJprSldpr6jveqQXYa3frETyKfFPolkPtaPRJrWg3tw677wD9a2faizztruqPmYG1bhxYvSGs4O1TNPZNR6EP1E8xZl13-DGS68N39JD-S1cZSl_MEqSLkOZfgqkX/s1600/BackupDevice4.JPG%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20286px;%20height:%20400px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFCm63tCNMm6-zse1PJprSldpr6jveqQXYa3frETyKfFPolkPtaPRJrWg3tw677wD9a2faizztruqPmYG1bhxYvSGs4O1TNPZNR6EP1E8xZl13-DGS68N39JD-S1cZSl_MEqSLkOZfgqkX/s400/BackupDevice4.JPG%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5468573721862502370%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cb%3EFigure%205%3C/b%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiMuUq9s2naatZIl7RTOrvfieH_syTXzc_zMaJuR_j_3PmT-pStkLw-5z2FQcw71RV_-1iHCNyQWiVljzVOlen6hA_h10xIJBD1S0011QFJRnVv2733_ujFnC_m4cl0If8Jt1wEDKZUDOoI/s1600/BackupDevice5.JPG%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20268px;%20height:%20305px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiMuUq9s2naatZIl7RTOrvfieH_syTXzc_zMaJuR_j_3PmT-pStkLw-5z2FQcw71RV_-1iHCNyQWiVljzVOlen6hA_h10xIJBD1S0011QFJRnVv2733_ujFnC_m4cl0If8Jt1wEDKZUDOoI/s400/BackupDevice5.JPG%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5468573855119164066%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cbr%20/%3EScript%20for%20Drop%20the%20Backup%20Device%3Cbr%20/%3E%3Cpre%3E%3Cbr%20/%3EEXEC%20sp_dropdevice%20'Time_Attendance'%3Cbr%20/%3E%3C/pre%3E%3Cbr%20/%3EScript%20for%20Create%20the%20Backup%20Device%3Cbr%20/%3E%3Cpre%3E%3Cbr%20/%3EEXEC%20sp_addumpdevice%20'disk',%20'Time_Attendance',%20@Path%3Cbr%20/%3E%3C/pre%3E%3Cbr%20/%3E%3Cbr%20/%3EScript%20for%20initializes%20the%20backup%20with%20user%20specified%20name%3Cbr%20/%3E%3Cpre%3E%3Cbr%20/%3EBACKUP%20DATABASE%20Time_Attendance%3Cbr%20/%3ETO%20Time_Attendance%20with%20name%3D%20@Name,%20INIT%3Cbr%20/%3E%3C/pre%3E%3Cbr%20/%3E%3C/div%3E)
Get the Running Total in Oracle 29 Apr 2010 10:32 PM (15 years ago)

This very frequent needful thing for developers as they need to create so many reports based on this concept.
For this you will have to use one of the window functions in oracle which is ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
This would add each and every vale with previous value and give like Running Total.
Query for this,
SELECT PRODUCT_NO,PL_NO, UNRESTRICTED_QTY,
SUM(UNRESTRICTED_QTY) OVER (ORDER BY PRODUCT_NO ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) RUNNING_TOTAL
FROM PRODUCT_LOCATION
WHERE CLIENT_C=UPPER(‘MSWG’) AND UNRESTRICTED_QTY>0 AND LOCATION_NO=’RECEIPT_BAY‘

row in the result set and adding up the values with currently reading value which is specified by CURRENT ROW up to last record of the record set.
And ordering results by PRODUCT_NO
The result of the above query shown below.

%20OVER%20(ORDER%20BY%20PRODUCT_NO%20ROWS%20BETWEEN%20UNBOUNDED%20PRECEDING%20AND%20CURRENT%20ROW)%20RUNNING_TOTAL%3Cbr%20/%3E%3Cbr%20/%3EFROM%20PRODUCT_LOCATION%3Cbr%20/%3E%3Cbr%20/%3EWHERE%20CLIENT_C%3DUPPER(%E2%80%98MSWG%E2%80%99)%20AND%20UNRESTRICTED_QTY%3E0%20AND%20LOCATION_NO%3D%E2%80%99RECEIPT_BAY%E2%80%98%3Cbr%20/%3E%3C/pre%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj3MpKgIXeNccDf0Q8SEMxRqBbtQLJ6ed3_pIIFraLXG4MiI2vi-SPAD5_Z_GWKt2spmuk_Jj6Nex30yR9Gc38dG-aryRXjyDpS5lBLIQzoB0gs1NUHz4JfXPz3iV_RmAYeO4Zo9NybJ5u5/s1600/windowfn.jpg%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%2049px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj3MpKgIXeNccDf0Q8SEMxRqBbtQLJ6ed3_pIIFraLXG4MiI2vi-SPAD5_Z_GWKt2spmuk_Jj6Nex30yR9Gc38dG-aryRXjyDpS5lBLIQzoB0gs1NUHz4JfXPz3iV_RmAYeO4Zo9NybJ5u5/s400/windowfn.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5465814876177763970%22%20border%3D%220%22%20/%3E%3Cstrong%3E%3C/strong%3E%3C/a%3E%3Cp%3Erow%20in%20the%20result%20set%20and%20adding%20up%20the%20values%20with%20currently%20reading%20%20value%20which%20is%20specified%20by%20%3Cstrong%3ECURRENT%3C/strong%3E%3Cstrong%3E%20%3C/strong%3E%3Cstrong%3EROW%3C/strong%3E%20%20up%20to%20last%20record%20of%20the%20record%20set.%3C/p%3E%20%3Cp%3EAnd%20ordering%20results%20by%20PRODUCT_NO%3C/p%3E%20%3Cp%3EThe%20result%20of%20the%20above%20query%20shown%20below.%3C/p%3E%3Cp%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj3MpKgIXeNccDf0Q8SEMxRqBbtQLJ6ed3_pIIFraLXG4MiI2vi-SPAD5_Z_GWKt2spmuk_Jj6Nex30yR9Gc38dG-aryRXjyDpS5lBLIQzoB0gs1NUHz4JfXPz3iV_RmAYeO4Zo9NybJ5u5/s1600/windowfn.jpg%22%3E%3Cstrong%3E%3C/strong%3E%3C/a%3E%3Cstrong%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhfbBxSdsYG3EGCzcNBoY1ruWP3D-kXAVxWXK-ldRigvfRf9AwWhX5pCo4d03D7D0giJs-6DuN2bhL53CsdmmdUAOIZgFs_TeZPz7_19aexXBx65Pife0C1wmlmbb2-L291wLisVaog0cGv/s1600/window_res.jpg%22%3E%3Cimg%20style%3D%22display:%20block;%20margin:%200px%20auto%2010px;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%20347px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhfbBxSdsYG3EGCzcNBoY1ruWP3D-kXAVxWXK-ldRigvfRf9AwWhX5pCo4d03D7D0giJs-6DuN2bhL53CsdmmdUAOIZgFs_TeZPz7_19aexXBx65Pife0C1wmlmbb2-L291wLisVaog0cGv/s400/window_res.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5465815089640799426%22%20border%3D%220%22%20/%3E%3C/a%3E%3C/strong%3E%3C/p%3E%3Cp%3E%3Cbr%20/%3E%3Cstrong%3E%3C/strong%3E%3C/p%3E%3Cp%3E%3Cbr%20/%3E%3C/p%3E%3Cp%3E%3Cbr%20/%3E%3C/p%3E%3Cp%3E%3Cbr%20/%3E%3C/p%3E)
Get table structure using SQL query in SQL Server 15 Apr 2010 1:41 AM (15 years ago)
Here it s the query for retrieve the table structure in sql server,
SELECT Ordinal_Position,Column_Name,Data_Type,Is_Nullable,Character_Maximum_Length
INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME='table Name'
Delete duplicate records from a Table in SQL Server 30 Mar 2010 1:08 AM (16 years ago)
drop table ##temp
create table ##temp (id char(3) ,marks int )
create table ##temp2 (id char(3) ,marks int )
insert into ##temp(id,marks) ----Here we are inserting duplicate
select '001',50 ----records for each ID
union all
select '001',60
union all
select '002',66
union all
select '002',88
union all
select '003',92
union all
select '003',64
union all
select '004',44
union all
select '005',67
----Here we are getting the distinct records and insert then into another Tempory table
insert into ##temp2 select distinct id,max(marks) from ##temp where id in(
select a.id from
(select id,count(id) cnt from ##temp group by id having count(id)>1) a)
group by id
---And delete those duplicate records from original Table
delete from ##temp where id in(
select a.id from
(select id,count(id) cnt from ##temp group by id having count(id)>1) a)
---And again inser the inserted reocrds from temporary Table
insert into ##temp select * from ##temp2
----Drop the Temporary Table.
drop table ##temp2
---Retrieve the Table which will have only distincts Records
select * from ##temp order by id
Blogger Buzz: Blogger integrates with Amazon Associates 26 Mar 2010 10:43 PM (16 years ago)
Blogger Buzz: Blogger integrates with Amazon Associates
Compute By clause in SQL Server 23 Mar 2010 1:39 AM (16 years ago)
We can use this clause to sum/count/avg/max/min so on. This clause will give you the output as detail and summary which is based on the fields you want to summarize.
select *
from #temp
order by student
compute sum(marks) by student
in above compute by clause, you must specify the field you want to sum in Compute clause and specify the field in By clause based on which field you need to compute.
Very important thing is you must specify the Order By clause in which specify the fileds whatever you specify in By clause in Compute clause.
The output of above query is,

When we try with max,min,avg, the query and output would be as shown below,
Using Max()
select * from #temp
order by student
compute max(marks) by student

Using Min ()
select * from #temp
order by student
compute min(marks) by student

Using Avg()
select * from #temp
order by student
compute avg(marks) by student

Use of Rowcount in SQL Server 15 Mar 2010 11:34 PM (16 years ago)
 We can use rowcount sql property to set the number of rows to be shown in the output.
We can use rowcount sql property to set the number of rows to be shown in the output.
for an example,
lets say there are 10 records in a table, if we set the rowcount to 5 then when retrieve records from that table, only 5 records will be shown.
if you rowcount to 0 then all records will be retrieved and shown in output.
SET ROWCOUNT 5SELECT ref_num FROM tbl_po_master

in above example only 5 rows have been retrieved and shown in output as we set the rowcount to 5.

Get the Table fileds in SQL Server/Oracle 15 Mar 2010 11:12 PM (16 years ago)
In SQL Server you can retreive the field names as shown below,
SELECT name
FROM syscolumnsWHERE id = (SELECT id FROM sysobjects WHERE name='Table_Name')

Get the parameter list of a Storedprocedure in SQL Server 15 Mar 2010 10:47 PM (16 years ago)
 There is way find what are the parameter list for a storedprocedure in sql server rather find them by open individually.
There is way find what are the parameter list for a storedprocedure in sql server rather find them by open individually.
SELECT PARAMETER_NAME,DATA_TYPE,PARAMETER_MODEFROM INFORMATION_SCHEMA.PARAMETERSWHERE SPECIFIC_NAME='AddDefaultPropertyDefinitions'

Hope this would be very useful for developers who are working with database.

Procedure for Split the words in SQL Sever 15 Mar 2010 10:19 PM (16 years ago)
 Here it is the procedure to Split the words using comma seperator. still you can use different character for split instead of comma(','). Here i m using 'E,l,e,p,h,a,n,t' as word with comma characters.
Here it is the procedure to Split the words using comma seperator. still you can use different character for split instead of comma(','). Here i m using 'E,l,e,p,h,a,n,t' as word with comma characters.
so the output should be 'E','l','e','p','h','a','n','t'.
Declare @name as varchar(20)Declare @i as intDeclare @char as charDeclare @word as varchar(20)select @name='E,l,e,p,h,a,n,t'set @word=''set @i=1while @i<=len(@name) begin set @char=substring(@name,@i,1) if @char<> ','beginset @word=@word+@charendelse if (@char=',' and @i<>len(@name))beginprint @wordset @word=''end---Print the last wordif @i=len(@name)beginprint @wordendset @i=@i+1end

Output of this query would be,

.%20Here%20i%20m%20using%20'E,l,e,p,h,a,n,t'%20as%20word%20with%20comma%20characters.%3Cbr%20/%3Eso%20the%20output%20should%20be%20%20'E','l','e','p','h','a','n','t'.%3Cbr%20/%3E%3C/span%3E%3Cspan%3E%3Ccode%3E%3C/code%3E%3C/span%3E%3Col%3E%3Cli%3E%3Cspan%3E%3Ccode%3EDeclare%20@name%20as%20varchar(20)%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3EDeclare%20@i%20as%20int%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3EDeclare%20@char%20as%20char%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3EDeclare%20@word%20as%20varchar(20)%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3Eselect%20@name%3D'E,l,e,p,h,a,n,t'%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3Eset%20@word%3D''%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3Eset%20@i%3D1%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3Ewhile%20@i%3C%3Dlen(@name)%20%20%20%20%20begin%20%20%20%20%20%20%20%20%20set%20@char%3Dsubstring(@name,@i,1)%20%20%20%20%20%20%20%20%20%20%20%20%20if%20@char%3C%3E%20','%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20begin%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20set%20@word%3D@word+@char%20%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20end%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20else%20if%20(@char%3D','%20and%20@i%3C%3Elen(@name))%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20begin%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20print%20@word%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20set%20@word%3D''%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20end%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20---Print%20the%20last%20word%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20if%20@i%3Dlen(@name)%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20begin%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20print%20@word%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20end%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20set%20@i%3D@i+1%3C/code%3E%3C/span%3E%3C/li%3E%3Cli%3E%3Cspan%3E%3Ccode%3E%20%20%20%20end%3C/code%3E%3C/span%3E%3C/li%3E%3C/ol%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgOZBePhabmxVdlh8ijLd7mdFgouJtsQ5T8xQrDUccfOqLNMWanV-tj16QLJl7daNjELPRNYcdqw_jbx21sYPolOk0SA-BPc9pBb-xn8lpi8FTbsZY_OmtuBCaMHa7FkEhIEl-_01r9vqxz/s1600-h/Split_Query.jpg%22%3E%3Cimg%20style%3D%22margin:%200pt%200pt%2010px%2010px;%20float:%20right;%20cursor:%20pointer;%20width:%20400px;%20height:%20318px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgOZBePhabmxVdlh8ijLd7mdFgouJtsQ5T8xQrDUccfOqLNMWanV-tj16QLJl7daNjELPRNYcdqw_jbx21sYPolOk0SA-BPc9pBb-xn8lpi8FTbsZY_OmtuBCaMHa7FkEhIEl-_01r9vqxz/s400/Split_Query.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5449115179251295266%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3EOutput%20of%20this%20query%20would%20be,%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEidFFlvFZ0yTfTtopcgdJ7SJDCJ12tZuXVDt5GvW-M1aHUVVBn0gJGb2I8iI8M5a0m3cZCpdY3jlM_ZuTa6YKj9KGRgUo4Eu1dmWhk7boy13U74lnK_kzOuCYcSPE7-3U8yARa__c_aSkMt/s1600-h/Split_Result.bmp%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%2061px;%20height:%20176px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEidFFlvFZ0yTfTtopcgdJ7SJDCJ12tZuXVDt5GvW-M1aHUVVBn0gJGb2I8iI8M5a0m3cZCpdY3jlM_ZuTa6YKj9KGRgUo4Eu1dmWhk7boy13U74lnK_kzOuCYcSPE7-3U8yARa__c_aSkMt/s400/Split_Result.bmp%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5449115501508225682%22%20border%3D%220%22%20/%3E%3C/a%3E)
Get the number of the current day of the week in SQL Server 8 Mar 2010 11:04 PM (16 years ago)
 In SQL Server there is a built-in function called Datepart() which is takes 2 paramaters which are return date option and date value.
In SQL Server there is a built-in function called Datepart() which is takes 2 paramaters which are return date option and date value.
for the 1st paramater pass the date option as 'dw' and for second parameter pass the date value as shown below,
SET dateformat dmy Select DATENAME(dw,'09/03/2010') Day_Name,datepart(dw,'09/03/2010') which_day_ofWeek
if you execute this query, output will be,
in SQL Server, by default the week start with 'Monday' which is 1. so in this example, the week is Tuesday. So the number of the Tuesday is 2.
You can check, what is default start week number by using @@DATEFIRST. Select @@DATEFIRST Since SQL Server default start week number is 1(Monday), it is giving 1 in output.
Since SQL Server default start week number is 1(Monday), it is giving 1 in output.
Default Value for Week in SQL Server,
Monday - 1
Tuesday - 2
Wednesday - 3
Thursday - 4
Friday - 5
Saturday - 6
Sunday - 7
But You can change the default start week number as shown below, SET datefirst 7
So here we make the start week number to 7 which is sunday.
After set the Datefirst to 7(sunday) and execute the first query you will get as shown below,
SET datefirst 7
SET dateformat dmy Select DATENAME(dw,'09/03/2010') Day_Name,datepart(dw,'09/03/2010') which_day_ofWeek  Now if you see the output, it shows 3. because now week start from Sunday instead of Monday. That is the reason why now week number became 3.
Now if you see the output, it shows 3. because now week start from Sunday instead of Monday. That is the reason why now week number became 3.
%20which%20is%20takes%202%20paramaters%20which%20are%20return%20date%20option%20and%20date%20value.%3C/span%3E%3Cbr%20/%3E%3Cspan%3Efor%20the%201st%20paramater%20pass%20the%20date%20option%20as%20'dw'%20and%20for%20second%20parameter%20pass%20the%20date%20value%20as%20shown%20below,%3C/span%3E%3Cbr%20/%3E%3Ccode%3E%3Cbr%20/%3E%3Cspan%3E%20SET%20dateformat%20dmy%3C/span%3E%3C/code%3E%20%3Ccode%3E%20Select%20DATENAME(dw,'09/03/2010')%20Day_Name,datepart(dw,'09/03/2010')%20which_day_ofWeek%3Cbr%20/%3E%3C/code%3E%3Cbr%20/%3E%3Cspan%3Eif%20you%20execute%20this%20query,%20output%20will%20be,%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiBC1VD15Dt4GIcc4X73koiCquIG_dbj7TCG7z40hVXJ18TuoDcZ1fOcDBd3k60bcK0H78WQc8Yqm2Tlz-kfDI6baT1LZLdu0uIcNupvyWVU-GnGp3aENScgryx8EIV3OPIVQWOub3kj0bK/s1600-h/Get_Weekday_Number.bmp%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%2091px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiBC1VD15Dt4GIcc4X73koiCquIG_dbj7TCG7z40hVXJ18TuoDcZ1fOcDBd3k60bcK0H78WQc8Yqm2Tlz-kfDI6baT1LZLdu0uIcNupvyWVU-GnGp3aENScgryx8EIV3OPIVQWOub3kj0bK/s400/Get_Weekday_Number.bmp%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5446551439477512274%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cspan%3Ein%20SQL%20Server,%20by%20default%20the%20week%20start%20with%20'Monday'%20which%20is%201.%20so%20in%20this%20example,%20the%20week%20is%20Tuesday.%20So%20the%20number%20of%20the%20Tuesday%20is%202.%3C/span%3E%3Cbr%20/%3E%3Cspan%3EYou%20can%20check,%20what%20is%20default%20start%20week%20number%20by%20using%20%3C/span%3E%3Cspan%3E@@DATEFIRST.%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%3Cspan%3ESelect%20@@DATEFIRST%3C/span%3E%3C/code%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh7YGZE5k9jphrCotkr_K6kdkkee0Hsi7CJK5JY28F1gWdqkubCjBtG2iLDS9lRkQ3xd4SoPnJl2AF_hOgCi2LwAOzqyxlWNDfqcyVy6uM0B4LQ0xzpBr7pnzjDR4qsgysatvXjuJKijW2m/s1600-h/DATEFIRST.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20310px;%20height:%20176px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh7YGZE5k9jphrCotkr_K6kdkkee0Hsi7CJK5JY28F1gWdqkubCjBtG2iLDS9lRkQ3xd4SoPnJl2AF_hOgCi2LwAOzqyxlWNDfqcyVy6uM0B4LQ0xzpBr7pnzjDR4qsgysatvXjuJKijW2m/s400/DATEFIRST.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5446552961251322114%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cspan%3ESince%20SQL%20Server%20default%20start%20week%20number%20is%201(Monday),%20it%20is%20giving%201%20in%20output.%3C/span%3E%3Cbr%20/%3E%3Cspan%3EDefault%20Value%20for%20Week%20in%20SQL%20Server,%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cspan%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Monday%20%20%20%20%20%20%20-%201%3Cbr%20/%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Tuesday%20%20%20%20%20%20-%202%3Cbr%20/%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Wednesday%20-%203%3Cbr%20/%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Thursday%20%20%20%20-%204%3Cbr%20/%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Friday%20%20%20%20%20%20%20%20%20%20-%205%3C/span%3E%3Cbr%20/%3E%3Cspan%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Saturday%20%20%20%20%20-%206%3C/span%3E%3Cbr%20/%3E%3Cspan%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Sunday%20%20%20%20%20%20%20%20-%207%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cspan%3EBut%20You%20can%20change%20the%20default%20start%20week%20number%20as%20shown%20below,%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cspan%3E%3Ccode%3E%20%20%20%20%20%20%20%20%20%20%20%20%20%20SET%20datefirst%20%3Cspan%3E7%3C/span%3E%3C/code%3E%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cspan%3ESo%20here%20we%20make%20the%20start%20week%20number%20to%207%20which%20is%20sunday.%3C/span%3E%3Cbr%20/%3E%3Cspan%3EAfter%20set%20the%20Datefirst%20to%207(sunday)%20and%20execute%20the%20first%20query%20you%20will%20get%20as%20%3C/span%3E%3Cspan%3Eshown%20below,%3C/span%3E%3Cbr%20/%3E%3Ccode%3E%3Cbr%20/%3E%3Cspan%3ESET%20datefirst%207%3C/span%3E%3Cbr%20/%3E%3Cspan%3ESET%20dateformat%20dmy%3C/span%3E%20%3Cspan%3ESelect%20DATENAME(dw,'09/03/2010')%20%20%20%20Day_Name,datepart(dw,'09/03/2010')%20which_day_ofWeek%3C/span%3E%20%3C/code%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiwfQTrjqqtvushtVQlqQKGdi7cJrMHpdODFpt4Gp9Us8CZputtcKrZx6sLoQavWvESwr2WijOibVTMVLoXQo99pLfSLdWsfLvr8VNDjuJkNbRI0MTH9z0dM1NnDRwuJzJlKoDw0hZ4F8tN/s1600-h/DATEFIRST_Query.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20400px;%20height:%2097px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiwfQTrjqqtvushtVQlqQKGdi7cJrMHpdODFpt4Gp9Us8CZputtcKrZx6sLoQavWvESwr2WijOibVTMVLoXQo99pLfSLdWsfLvr8VNDjuJkNbRI0MTH9z0dM1NnDRwuJzJlKoDw0hZ4F8tN/s400/DATEFIRST_Query.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5446556972947173778%22%20border%3D%220%22%20/%3E%3C/a%3ENow%20if%20you%20see%20the%20output,%20it%20shows%203.%20because%20now%20week%20start%20from%20Sunday%20instead%20of%20Monday.%20That%20is%20the%20reason%20why%20now%20week%20number%20became%203.)
Get the Weekday Name in SQL Server 8 Mar 2010 9:56 PM (16 years ago)
 There is a built-in function call DateName() in SQL Server to get the Weekday Name.
There is a built-in function call DateName() in SQL Server to get the Weekday Name.
This function takes 2 parameters in which first is return date option whereas second one date value from which you want to get the weekday name.
To get the weekday name you have to specify the date option as 'dw'.
for example,
set dateformat dmy
SELECT DATENAME(dw,'09/03/2010') Weekday
in output, it is give you week day name.
%3C/span%3E%20in%20SQL%20Server%20to%20get%20the%20Weekday%20Name.%3Cbr%20/%3EThis%20function%20takes%202%20parameters%20in%20which%20first%20is%20return%20date%20option%20whereas%20second%20one%20date%20value%20from%20which%20you%20want%20to%20get%20the%20weekday%20name.%3Cbr%20/%3ETo%20get%20the%20weekday%20name%20you%20have%20to%20specify%20the%20date%20option%20as%20%3Cspan%3E'dw'%3C/span%3E.%3Cbr%20/%3E%3Cbr%20/%3Efor%20example,%3Cbr%20/%3E%3Ccode%3E%3Cbr%20/%3Eset%20dateformat%20dmy%3Cbr%20/%3ESELECT%20DATENAME(dw,'09/03/2010')%20Weekday%3Cbr%20/%3E%3Cbr%20/%3E%3C/code%3Ein%20this%20example%20'09'%20is%20day%20of%20march.%20so%20if%20you%20use%20this%20sql%20function%20as%20i%20given%20above,%20it%20will%20return%20the%20exact%20name%20of%20the%20weekday.%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiLg_v6M9b3tpdvT5LSpntQVTQZQoQbxyxuOrVcLok3040fWrn7sFF9yNYDBwqiv4Mj_BLNgzavMwwn68JYjIMXXsQrtxSh5TJ4SJhwPoNWoIZLd6fEoNnDGQo6EQpGYUHWPi5C_YRUs1yg/s1600-h/Get_WeekName.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20320px;%20height:%20142px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiLg_v6M9b3tpdvT5LSpntQVTQZQoQbxyxuOrVcLok3040fWrn7sFF9yNYDBwqiv4Mj_BLNgzavMwwn68JYjIMXXsQrtxSh5TJ4SJhwPoNWoIZLd6fEoNnDGQo6EQpGYUHWPi5C_YRUs1yg/s320/Get_WeekName.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5446529852017016242%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3Ein%20output,%20it%20is%20give%20you%20week%20day%20name.)
How to get the month name in SQL Server 7 Mar 2010 11:34 PM (16 years ago)
 There is a built-in function called datename() for find the month name from given date.
There is a built-in function called datename() for find the month name from given date.
for example:
%3C/span%3E%20for%20find%20the%20month%20name%20from%20given%20date.%3C/span%3E%3Cbr%20/%3E%3Cspan%3Efor%20example:%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhtNvDjGSYfT_3ceSt6rzTPZTJFLdYo5EGNQCua6C824GaQHsdLdtmeOYoYLKfY_fBVHLLY8YQGzH2xAf1uZzwbWOziZsQU429PU8-ntn5jr3-MZyP2euQgBWP9yjMcTB6cgsFYgFxA1FPB/s1600-h/GetName.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20320px;%20height:%20155px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhtNvDjGSYfT_3ceSt6rzTPZTJFLdYo5EGNQCua6C824GaQHsdLdtmeOYoYLKfY_fBVHLLY8YQGzH2xAf1uZzwbWOziZsQU429PU8-ntn5jr3-MZyP2euQgBWP9yjMcTB6cgsFYgFxA1FPB/s320/GetName.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5446180384608240898%22%20border%3D%220%22%20/%3E%3C/a%3E)
Get the Column data in a single row with comma separator in SQL 4 Mar 2010 11:08 PM (16 years ago)
 In this post i thought to expalin how to get one column data in a single row with comma separator. as i shown shown below a table have one column call Choice which have 4 rows.
In this post i thought to expalin how to get one column data in a single row with comma separator. as i shown shown below a table have one column call Choice which have 4 rows.
So our task is how to bring up all these 4 rows into one single row with comma separator.
We can do this in 2 methods,
- Using COALESCE() function
- Using ISNULL() Function
Actually both are playing same role.
1. Using COALESCE() function
As shown below in the SQL Query below, COALESCE() function takes 2 parameters.
It is check whether passed field value is Null or not if it is null then place with blank whereas if the field value is not null then concatenate value with comma.

2. Using ISNULL() Function
This query also working similar to COALESCE() function.

here value 'A' repeating twice. so how to get distinct value from this?
here it is the SQL query for that,
 We just write subquery to filter only distinct values and using that as a Table for Outer query.
We just write subquery to filter only distinct values and using that as a Table for Outer query.So here only gives A,B,C.
%20function%3C/li%3E%3Cli%3EUsing%20ISNULL()%20Function%3C/li%3E%3C/ol%3E%3Cbr%20/%3EActually%20both%20are%20playing%20same%20role.%3Cbr%20/%3E%3Cbr%20/%3E%3Cspan%3E1.%20Using%20COALESCE()%20function%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3EAs%20shown%20below%20in%20the%20SQL%20Query%20below,%20COALESCE()%20function%20takes%202%20parameters.%3Cbr%20/%3EIt%20is%20check%20whether%20passed%20field%20value%20is%20Null%20or%20not%20if%20it%20is%20null%20then%20place%20with%20blank%20whereas%20if%20the%20field%20value%20is%20not%20null%20then%20concatenate%20value%20with%20comma.%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgG03r_p7QE_q_G7GTS89Uq0cO6xM_tC0SSm_jXb0TcZn5ENeMJImYN_h9-w2XkRSDz_Au0EPwu9QJVvyKPRxAkoU9o-wVFGa68_KzuuWX9b5BqKnPpLlkZYnohbS8lx3wEhSy0pooVrCnZ/s1600-h/COALESCE_Function1.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20380px;%20height:%20340px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgG03r_p7QE_q_G7GTS89Uq0cO6xM_tC0SSm_jXb0TcZn5ENeMJImYN_h9-w2XkRSDz_Au0EPwu9QJVvyKPRxAkoU9o-wVFGa68_KzuuWX9b5BqKnPpLlkZYnohbS8lx3wEhSy0pooVrCnZ/s320/COALESCE_Function1.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5445070520492785954%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cspan%3E2.%20Using%20ISNULL()%20Function%3C/span%3E%3Cbr%20/%3E%3Cbr%20/%3EThis%20query%20also%20working%20similar%20to%20COALESCE()%20function.%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgskSoA7i7DLHwFnosWy4vIqkEfHHOdSe57yQRX24TY6IEgc0qPkJD4ILf8ZPvjisB_ddA6y1tW5771Vx6HCXVO6jx1UnE0THojaA2N67oZ97AdZ-9CgOvPb5Fi8WlQzn08k6QzFmjvjDZM/s1600-h/ISNULL_Function1.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20429px;%20height:%20371px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgskSoA7i7DLHwFnosWy4vIqkEfHHOdSe57yQRX24TY6IEgc0qPkJD4ILf8ZPvjisB_ddA6y1tW5771Vx6HCXVO6jx1UnE0THojaA2N67oZ97AdZ-9CgOvPb5Fi8WlQzn08k6QzFmjvjDZM/s320/ISNULL_Function1.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5445070932781685170%22%20border%3D%220%22%20/%3E%3C/a%3E%3Cbr%20/%3Ehere%20%20value%20'A'%20repeating%20twice.%20so%20how%20to%20get%20distinct%20value%20from%20this?%3Cbr%20/%3Ehere%20it%20is%20the%20SQL%20query%20for%20that,%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiP9s5r2U5hwW3V1WxfnEt3kkcbivAJtd4_dGYJq63Zivy-WySBMGMGvX9Z80l8P4Plnh3MhDuiMlyr9U3DAKbc5jqEsHqv7kqxEgdopG7dLvh4eLFYivpEa9EYnVNOnH2Ctyk60KbB8rEp/s1600-h/COALESCE_Function1_Distinct.jpg%22%3E%3Cimg%20style%3D%22margin:%200px%20auto%2010px;%20display:%20block;%20text-align:%20center;%20cursor:%20pointer;%20width:%20320px;%20height:%20293px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiP9s5r2U5hwW3V1WxfnEt3kkcbivAJtd4_dGYJq63Zivy-WySBMGMGvX9Z80l8P4Plnh3MhDuiMlyr9U3DAKbc5jqEsHqv7kqxEgdopG7dLvh4eLFYivpEa9EYnVNOnH2Ctyk60KbB8rEp/s320/COALESCE_Function1_Distinct.jpg%22%20alt%3D%22%22%20id%3D%22BLOGGER_PHOTO_ID_5445071832468692610%22%20border%3D%220%22%20/%3E%3C/a%3EWe%20just%20write%20subquery%20to%20filter%20only%20distinct%20values%20and%20using%20that%20as%20a%20Table%20for%20Outer%20query.%3Cbr%20/%3ESo%20here%20only%20gives%20A,B,C.)
Get the Server Name in SQL Server 25 Feb 2010 11:55 PM (16 years ago)
We can get the Connected Sql Server Name using the Built-in function SQL Server as shown below,



Extract only the Date from DateTime in SQL Server 25 Feb 2010 8:36 PM (16 years ago)
Normaly extarcting date only from DATETIME is commaon and serious problem in SQL SERVER.
Here i have given some common methods to extract on the date from datetime
Method 1
------------
SELECT
CAST
(
FLOOR(CAST(GETDATE() AS FLOAT))
AS DATETIME
)
Method 2--but it is not correct
------------------------------------
This is similar to first method but we have used INT instead of FLOAT . But it will seldom correct. It will not give you the exact date of what you expecting.
So better not to use INT.
SELECT
CAST
(
FLOOR(CAST(GETDATE() AS INT))
AS DATETIME
)
Method 3
----------
i would recommend this method to extract inly date though there are many methods. because this method is very simple and easy.
SELECT
CAST
(
STR(DAY(GETDATE()))+ '/' +
STR(MONTH(GETDATE())) +'/'+
STR(YEAR(GETDATE()))
AS DATETIME
)
Method 4
----------
In this we have used CONVERT function with 113 date type.
SELECT CONVERT(DATETIME, CONVERT(VARCHAR(12), GETDATE(), 113))
Method 5
----------
Here we have used DATEDIFF and DATEADD functions together to extract.get the different between specified date and 0 then again add o with output value of DATEDIFF
SELECT DATEADD(dd, DATEDIFF(dd,0,GETDATE()), 0)
Method 6
----------
This is also similar to previous method. But here we have not used DATEADD instead we have used CAST.
SELECTCAST(DATEDIFF(dd,0,GETDATE() as datetime)
PIVOT() Function MSSQL Server 10 Feb 2010 9:47 PM (16 years ago)
 Introduction
Introduction
The PIVOT() function in MS SQL Server is very useful function. This is works like Cross-Tab table in Crystal Report.
Explanation
For an instance, as shown below table, we have customer,Yr,Mothname, and TTL columns. The Year column consisting distinct records 2009,2010 year. If you want to show the Year data as each column header name, then you will have to use the PIVOT() function to show the distinct records as column header.
SELECT user_id Customer,datepart(“yyyy”,order_date) Yr,datename(month,order_date) [Month] ,
isnull(sum(total_value),0) TTL
FROM tbl_po_master group by user_id,datepart(“yyyy”,order_date),datename(month,order_date)
Using PIVOT() function
In PIVOT() function, you must specify the column values as shown below,
select * from
(SELECT user_id Customer,datepart(“yyyy”,order_date) Yr,datename(month,order_date) [Month] ,
isnull(sum(total_value),0) TTL
FROM tbl_po_master group by user_id,datepart(“yyyy”,order_date),datename(month,order_date) ) s
PIVOT
(
sum(TTL)
FOR yr IN ([2009],[2010])
) p
order by Customer
With our previous query we need to use PIVOT() function and in PIVOT() function have to give the aggregating filed and give the filed/Column name which should show as each column header.
sum(TTL) à This is the Aggregate field
FOR yr IN ([2009],[2010])
Here, give the column name which should show each column header. And give the distinct values of that field as parameter for IN().
After executed the above query you would get this result in which you could notice that 2009,2010 column values became as each column header
In this above query you can give the Month column name instead of Yr column. If try with that you would get the out put as shown below,
Query:
select * from
(SELECT user_id Customer,datepart(“yyyy”,order_date) Yr,datename(month,order_date) [Month] ,
isnull(sum(total_value),0) TTL
FROM tbl_po_master group by user_id,datepart(“yyyy”,order_date),datename(month,order_date) ) s
PIVOT
(
sum(TTL)
FOR Month IN ([December],[January])
) p
order by Customer
Output:
Now in the output, Month field distinct values (December and January) are showing as column header mean while Yr column values (2009,2010) are showing as row
%20Function%20MSSQL%20Server%26bodytext%3DIntroduction%3Cbr%20/%3E%3Cbr%20/%3EThe%20PIVOT()%20function%20in%20MS%20SQL%20Server%20is%20very%20useful%20function.%20This%20is%20works%20like%20Cross-Tab%20table%20in%20Crystal%20Report.%3Cbr%20/%3E%3Cbr%20/%3EExplanation%3Cbr%20/%3E%3Cbr%20/%3EFor%20an%20instance,%20as%20shown%20below%20table,%20we%20have%20customer,Yr,Mothname,%20and%20TTL%20columns.%20The%20Year%20column%20consisting%20distinct%20records%202009,2010%20year.%20If%20you%20want%20to%20show%20the%20Year%20data%20as%20each%20column%20header%20name,%20then%20you%20will%20have%20to%20use%20the%20PIVOT()%20function%20to%20show%20the%20distinct%20records%20as%20column%20header.%3Cbr%20/%3E%3Cbr%20/%3E%3Cstrong%3E%20SELECT%20user_id%20Customer,datepart(%E2%80%9Cyyyy%E2%80%9D,order_date)%20Yr,datename(month,order_date)%20%5BMonth%5D%20,%3Cbr%20/%3E%3Cbr%20/%3Eisnull(sum(total_value),0)%20TTL%3Cbr%20/%3E%3Cbr%20/%3EFROM%20tbl_po_master%20group%20by%20user_id,datepart(%E2%80%9Cyyyy%E2%80%9D,order_date),datename(month,order_date)%3Cbr%20/%3E%3C/strong%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFPW1LeSyxx9utR5-p1FCf6Ot1f-VJpv9R4tWlp5eJUf593vLN7vzcQBn3-pgO3rG3XT6FCAHI3h4OK06hSYPaWpr4gx1Eom4AoXKGNf7t2XGeMCpa_WW4pUNQOlw9xb37IW6AYlZNGcpb/s1600-h/Group+Query+Result.jpg%22%3E%3Cimg%20style%3D%22display:block;%20margin:0px%20auto%2010px;%20text-align:center;cursor:pointer;%20cursor:hand;width:%20320px;%20height:%20158px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFPW1LeSyxx9utR5-p1FCf6Ot1f-VJpv9R4tWlp5eJUf593vLN7vzcQBn3-pgO3rG3XT6FCAHI3h4OK06hSYPaWpr4gx1Eom4AoXKGNf7t2XGeMCpa_WW4pUNQOlw9xb37IW6AYlZNGcpb/s320/Group+Query+Result.jpg%22%20border%3D%220%22%20alt%3D%22%22id%3D%22BLOGGER_PHOTO_ID_5436875637675392082%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3EUsing%20PIVOT()%20function%3Cbr%20/%3E%3Cbr%20/%3EIn%20PIVOT()%20function,%20you%20must%20specify%20the%20column%20values%20as%20shown%20below,%3Cbr%20/%3E%3Cbr%20/%3E%3Cstrong%3E%3Cbr%20/%3Eselect%20*%20from%3Cbr%20/%3E%3Cbr%20/%3E(SELECT%20user_id%20Customer,datepart(%E2%80%9Cyyyy%E2%80%9D,order_date)%20Yr,datename(month,order_date)%20%5BMonth%5D%20,%3Cbr%20/%3E%3Cbr%20/%3Eisnull(sum(total_value),0)%20TTL%3Cbr%20/%3E%3Cbr%20/%3EFROM%20tbl_po_master%20group%20by%20user_id,datepart(%E2%80%9Cyyyy%E2%80%9D,order_date),datename(month,order_date)%20%20)%20s%3Cbr%20/%3E%3Cbr%20/%3EPIVOT%3Cbr%20/%3E%3Cbr%20/%3E(%3Cbr%20/%3E%3Cbr%20/%3Esum(TTL)%3Cbr%20/%3E%3Cbr%20/%3EFOR%20yr%20IN%20(%5B2009%5D,%5B2010%5D)%3Cbr%20/%3E%3Cbr%20/%3E)%20p%3Cbr%20/%3E%3Cbr%20/%3Eorder%20by%20Customer%3Cbr%20/%3E%3C/strong%3E%3Cbr%20/%3E%3Cbr%20/%3EWith%20our%20previous%20query%20we%20need%20to%20use%20PIVOT()%20function%20and%20in%20PIVOT()%20function%20have%20to%20give%20the%20aggregating%20filed%20and%20give%20the%20filed/Column%20name%20which%20should%20show%20as%20each%20column%20header.%3Cbr%20/%3E%3Cbr%20/%3Esum(TTL)%20%C3%A0%20This%20is%20the%20Aggregate%20field%3Cbr%20/%3E%3Cbr%20/%3EFOR%20yr%20IN%20(%5B2009%5D,%5B2010%5D)%3Cbr%20/%3E%3Cbr%20/%3EHere,%20give%20the%20column%20name%20which%20should%20show%20each%20column%20header.%20And%20give%20the%20distinct%20values%20of%20that%20field%20as%20parameter%20for%20IN().%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEixv99BaZ4PmtU_o2MU0BTGjiPDMWTj_9ITUJ3vaKVUW5GfSo4VaoLTkGr-Y3qVCqhgbpPIA7pDn3cbPjnYMke2n43Fp6L3IqJ87zOQIYNlZcwOLhAwHR9NIQ43fZEgzvkE-MBwx7H6l4rd/s1600-h/QUERY_RESULTS.jpg%22%3E%3Cimg%20style%3D%22display:block;%20margin:0px%20auto%2010px;%20text-align:center;cursor:pointer;%20cursor:hand;width:%20320px;%20height:%20192px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEixv99BaZ4PmtU_o2MU0BTGjiPDMWTj_9ITUJ3vaKVUW5GfSo4VaoLTkGr-Y3qVCqhgbpPIA7pDn3cbPjnYMke2n43Fp6L3IqJ87zOQIYNlZcwOLhAwHR9NIQ43fZEgzvkE-MBwx7H6l4rd/s320/QUERY_RESULTS.jpg%22%20border%3D%220%22%20alt%3D%22%22id%3D%22BLOGGER_PHOTO_ID_5436876378151915890%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3EAfter%20executed%20the%20above%20query%20you%20would%20get%20this%20result%20in%20which%20you%20could%20notice%20that%202009,2010%20column%20values%20became%20as%20each%20column%20header%3Cbr%20/%3E%3Cbr%20/%3EIn%20this%20above%20query%20you%20can%20give%20the%20Month%20column%20name%20instead%20of%20Yr%20column.%20If%20try%20with%20that%20you%20would%20get%20the%20out%20put%20as%20shown%20below,%3Cbr%20/%3E%3Cbr%20/%3EQuery:%3Cbr%20/%3E%3Cbr%20/%3E%3Cstrong%3E%3Cbr%20/%3Eselect%20*%20from%3Cbr%20/%3E%3Cbr%20/%3E(SELECT%20user_id%20Customer,datepart(%E2%80%9Cyyyy%E2%80%9D,order_date)%20Yr,datename(month,order_date)%20%5BMonth%5D%20,%3Cbr%20/%3E%3Cbr%20/%3Eisnull(sum(total_value),0)%20TTL%3Cbr%20/%3E%3Cbr%20/%3EFROM%20tbl_po_master%20group%20by%20user_id,datepart(%E2%80%9Cyyyy%E2%80%9D,order_date),datename(month,order_date)%20%20)%20s%3Cbr%20/%3E%3Cbr%20/%3EPIVOT%3Cbr%20/%3E%3Cbr%20/%3E(%3Cbr%20/%3E%3Cbr%20/%3Esum(TTL)%3Cbr%20/%3E%3Cbr%20/%3EFOR%20Month%20IN%20(%5BDecember%5D,%5BJanuary%5D)%3Cbr%20/%3E%3Cbr%20/%3E)%20p%3Cbr%20/%3E%3Cbr%20/%3Eorder%20by%20Customer%3Cbr%20/%3E%3C/strong%3E%3Cbr%20/%3E%3Cbr%20/%3EOutput:%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Ca%20href%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEih8oXR7U6Vr23Ch0l4hqR7YquHFrrqnTAXVPCYwXMoe_HyxNRIWdKC7uNXtcn5fWtYFEuTcXbnTYjZkJgEIx8_SUjr5hlHCcSZB7AAwknrbWTi7P7vX2JmmibqV4r0k_IIEwUdDD-3zayO/s1600-h/QUERY_RESULTS2.jpg%22%3E%3Cimg%20style%3D%22display:block;%20margin:0px%20auto%2010px;%20text-align:center;cursor:pointer;%20cursor:hand;width:%20320px;%20height:%20112px;%22%20src%3D%22https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEih8oXR7U6Vr23Ch0l4hqR7YquHFrrqnTAXVPCYwXMoe_HyxNRIWdKC7uNXtcn5fWtYFEuTcXbnTYjZkJgEIx8_SUjr5hlHCcSZB7AAwknrbWTi7P7vX2JmmibqV4r0k_IIEwUdDD-3zayO/s320/QUERY_RESULTS2.jpg%22%20border%3D%220%22%20alt%3D%22%22id%3D%22BLOGGER_PHOTO_ID_5436876569299744354%22%20/%3E%3C/a%3E%3Cbr%20/%3E%3Cbr%20/%3E%3Cbr%20/%3ENow%20in%20the%20output,%20Month%20field%20distinct%20values%20(December%20and%20January)%20are%20showing%20as%20column%20header%20mean%20while%20Yr%20column%20values%20(2009,2010)%20are%20showing%20as%20row)