12 Days in Iceland, the Land of Ice, Water, and Fire 29 Jul 2016 1:07 PM (8 years ago)
First thing first, 12 days is not nearly enough to visit this beautiful country. We probably visited less than half of the places we wanted to visit. If you truly want to enjoy Iceland and get the maximum out of a single trip, plan for a at least a full two weeks. And then plan to go back for another two weeks at some other point to see the rest.
B Notes: If you have only a week, stick to an area rather than spending time driving on the entire Ring Road. If I had one week, I would spend it in the Westfjords.
After spending 12 days and driving 3338 kilometers (2074 miles) in Iceland, we (L or me, B or wife, A1 Jianson - ~10, A2 Jiandóttir - ~8) all agreed that it’s definitely worth the trip.
Tips and Stuff
Planning for the Trip
Truth be told, we were procrastinators when it came to preparing for the trip. Aside from booking our tickets on WOW Air 2+ months before the trip, we waited until the weekend before the trip to actually plan for it. We basically planned our itinerary in a single day, after reading a bunch of blogs and articles online. A1 and A2 also helped by watching a bunch of Youtube videos (and learning a few words along the way).
B Notes: And don’t be shy to ask once you are there where you should go/buy/eat/see…the locals/fellow travellers can provide valuable tips that will help your journey.
I found guidetoiceland.is to be the most helpful. In fact, we found most of the places we want to visit by reading their suggestions. Check out their articles on:
- Best Attractions by the Ring Road of Iceland
- The 5 Best Hot Springs in Iceland
- Though we recommend skipping the Blue Lagoon (yes, contrary to popular belief) as the locals told us that the Blue Lagoon is man made and it supposedly doesn’t drain!! With thousands of people visiting each day, imagine the state of the water at the end of each day. And imagine people actually putting that white stuff on their face!!
- We didn’t fact check this so take this with a grain of salt.
- The Ultimate Guide to Driving in Iceland
- 14 Day Self Drive Tour | Circle of Iceland & The Westfjords
- 12 Day Self Drive Tour | Circle Of Iceland | National Parks
Other articles include:
We also found the Trip Advisor Iceland Forum to be a tremendous resource when it came to ratings of various attractions. Highly recommended.
Guide to Iceland offered self-guided tours where they will book everything for you, including cars and hotels. However, we found the pricing to be fairly expensive. We ended up building our own itinerary based on the suggestions from these self-guided tours. The downside is we had to book all the lodging ourselves.
The worst thing about being procrastinators and doing late planning is the extra headache and cost on lodging. I think between lack of lodging options, higher cost for lodging and farther out lodging options, it cost us USD$200-300 more than we would have liked.
Mobile Coverage and Navigation
Moile data is an important factor as I wanted to use Google Maps to navigate around Iceland, and didn’t want to rent a GPS unit. We also wanted to use Google Hangouts for phone calls and didn’t want to get a local SIM.
We did some preliminary research on SIM cards in Iceland but ended up using Google Fi instead. It turned out to be one of the better decisions we made for this trip.
Iceland in general has pretty good coverage. If you stay on the ring road, you should be able to get at least 3G coverage 70-80% of the time. In many cases, especially when you are near major cities/towns such as Reykjavik or Akureyri, you will get LTE coverage as well. Google Fi just announced their service upgrade to support the best service (e.g., LTE) right before our trip, so we were definitely happy about that.
However, if you go to areas such as Westfjords, or if you are in the mountains on the ring road, then coverage becomes very spotty. In some cases you can get 2G service, but in many cases in these remote areas the only thing you get is voice service. In Westfjords, we had “No Service” on our phone majority of the time.
We had Google FI data-only SIM cards for both of our iPhones. My iPhone 6 got pretty good signals most of the time when there’s coverage. For some reason, maybe it has a better antenna, B’s iphone 6S+ was able to get even better signals and sometimes LTE service when my iPhone 6 was only able to get 3G.
Between the wifi that’s available at most of the places we stayed and the Google Fi service, we had all the coverage we needed. Google Hangouts worked out beautifully over the wifi and data networks. I was able to keep my US Google phone number, and call any US number for free. To call Iceland, Google Hangouts charged $0.02/min for landlines and $0.15/min for mobile lines. Overall I spent $2.65 for 0.265GB of internaltion data usage on Google Fi for the 12 days we were there. For Google Hangouts, I spent $2.75 for the trip calling a few Iceland places. So altogether it’s about $5.40.
Google Maps worked out beautifully as well. In most cases, I set the navigation routes using the lodging wifi before heading out, and Google Maps stores an offline copy of the route so even when I lose mobile service, my navigation is not affected. The only thing I wish Google would make easier is managing multiple destinations on the iOS app, which I just saw the news that they are rolling out this specific change gradually.
So thanks to Google for these wonderful services.
Pass Time for the Long Drives
We were in the car quite a bit as we drove 3338 kilometers. With two young kids (10 and 8), we have learned from experience that the best way to keep them from fighting with each other, or asking “are we there yet?” every 5 minutes is to let them listen to lots of audio books. We loaded a 3rd iPhone (no SIM, so basically iPod) with a bunch of audio books like Harry Potter, Judy Blume and others, and the whole time we were driving they were listening to these. Certainly helped keep us sane.
B Notes: All and all, I am grateful for that our fellow travellers in the back seats were cooperatives and came with us on this incredible adventure. Never underestimate the value of books on tape, crackers and chocolates! :-)
Amazon Prime Music also proved to be very useful as well. I downloaded a bunch of prime music onto my phone before the trip, and listened to them during part of our trip. Though in most cases we were enjoying the view on the road and forgot to turn on the music.
Assuming data coverage is available, TurnIn radio also proved to be useful for catching up on US news. We didn’t mind using up a bit of data to keep up with the news.
Other Electronic/App Stuff
Here are some other electronic stuff you might want to consider bringing.
- BESTEK Grounded Universal Travel Plug Adapter for France, Germany or similar
- This is a 3 pack, but if you don’t have a lot of electronics, one is sufficient. For us, we didn’t bring any computers.
- USB Charger RAVPower 50W 10A 6-Port USB Charger or similar
- Well worth bringing this. We had 3 iPhones (1 technically is an iPod), an action camera battery charger, and a couple other electronic items that all needed charging.
- This charger can do all of them at the same time and we didn’t have to go hunt for a bunch of outlets and use a bunch of plug adapters.
- Apps
- As desribed above – Google Maps, Google Hangouts, Amazon Prime Music, TuneIn
- Google Translate is a great app for translating labels on food packaging. We used it quite a bit since A1 is allergic to nuts.
- Reykjavik Map and Walks is a great little app that gives you most of the attractions you should visit in Reykjavik. I used the free version with a combination of Google Maps to walk around the city.
- TripAdvisor Hotels Flights Restaurants for reading reviews and recommendations.
- Commander Compass Lite to get GPS location and many other interesting location tidbits. Technically you can use the Apple Compass app to get GPS location but this one provides more info.
For the first time in my life I didn’t bring a computer with me for a trip. It’s by far the longest period of time that I don’t have a computer since laptops become portable enough to carry. It was fine at the end. I just had to make sure that we mass delete a bunch of photos from both of our iPhones before the trip to ensure there’s enough space for videos and photos.
Clothes, Shoes
Dress in layers is the best advice we have read, and it’s absolutely true. Even in July, the weather can be somewhat unpredictable. We started with a few days with really nice weather, then as we moved to the northwest (Westfjords) and the north, the weather became cooler, windier and overcast.
Our typical layers include a short sleeve, a long sleeve, and a warm jacket. Since we were going to visit the glaciers and waterfalls, we also brought rain jackets (or waterproof outer jacket) and gloves. The rain jackets proved to be extremely useful!
We have read that waterproof pants would be needed, but that didn’t turn out to be the case. In most cases quick dry pants (like these) are more than sufficient.
We also brought good waterproof hiking shoes (like these, or these for kids), which turned out to be a MUST for this trip. With the rugged terrain for many of the places we visited, shoes with good traction will make it much easier. We saw some tourists with fairly flat footwear, or sometimes even with heels. Honestly I have no idea how they survived some of the more rugged areas.
The waterproof shoes also proved to be extremely useful when going INTO the glacier. Given it’s July, the top layer of snow is melting and the water goes through the ice and drips into the glacier tunnel we visited, so sometimes there’s a layer of water 1⁄4 - 1⁄2 inch deep that we need to walk through.
Other stuff to bring include sunglasses (must, especially for glacier hiking in the summer), sunscreen, and maybe a hat for each person.
B Notes: We also each brought a pair of sandals/flip flops. Most Airbnb/Guest House have a mud room which you will need to take of your shoes. It also help with all the swimming pools we visited. Lastly, if you accidentally fell in the river, you would have have something to wear while you try to dry your hiking boots and socks on the dashboard. :-)
Car Rental
To start, we looked into the option of renting a 4-person campervan. It seemed like a great (and probably more economical) option to travel in Iceland as you can set your own schedule. Unfortunately we didn’t realize this was an option until too late (note we procrastinated until the very last minute to plan). Also, most campervans seem to be manual and neither myself or B know how to drive that. So that option is out regardless. If we go back, I would definitely look at this option again.
Given it’s July (no snow!) and we weren’t planning on going on any F roads (and off-roading is illegal), we decided to rent a small 2WD. We rented a cool little blue Honda Jazz via Guide to Iceland. Guide to Iceland is actually a broker, and the final car rental company is IceRentalCars.
After reading through multiple forum posts on Trip Advisor, we learned that most car rentals include basic insurance service called Collision Damage Waiver (CDW). This is automatically included and cannot be taken off (in most cases). Because of this inclusion, you cannot use your credit card rental insurance to cover the car as most credit card companies require that you waive ALL insurance provided by the rental company.
We have read enough of not-so-great stories about car rental companies that we decided to accept the basic CDW and additionally purchase the Super CDW (SCDW), which in effect lowers our liability even more. In addition, given that we are traveling to Westfjords and having read that most roads there are gravel roads, we purchased Gravel Protection (GP) as well. While it’s a bit more expensive, we wanted the peace of mind of not having to deal with international insurance issues when something bad happens. Note that no insurance cover water damage or damage to the frame of the car.
Overall we had a pretty good experience with both Guide to Iceland and IceRentalCars. When we arrived at the airport, we were picked up by a driver that drove us to the car lot (extra cost). We did some quick paper work and were handed the keys. We did see another couple who had to go through the insurance struggle while there (trying to not get insurance and use the credit card insurance coverage) and glad we did the research before hand.
Learning from the forum posts, we also took A LOT of detailed pictures of the car to make sure all the scratches and dents are identified. We had the rental person mark every little scratch we found. There weren’t many since the car looked fairly new. We did miss one scratch but luckily the picture we took had it.
At the end though I don’t think it would have mattered, since the person who received the car only did a cursory look to ensure there’s no water or frame damage. Maybe he did that because we bought both GP and SCDW insurance.
Driving in Iceland
Driving in Iceland is fairly straightforward if you are an experienced driver from the US. The driver is on the left side and you drive on the right side of the road, just like home! However, it is still best to familiarize yourself with the road signs. This is something I did after I started driving there and wondered what some of the signs meant. Worth spending a few minutes before hand. This is also a good article on driving in Iceland.
Typical driving speed is 90 kmh on the paved ring road, 80 on the well-maintained gravel roads (part of the ring road on the east is gravel), 60-70 on some of the turns, 50 inside cities and 30 in the residential areas. On some really bad gravel roads like in the Westfjords or the Öxi pass, you may need to slow down even further.
In general we found there were 4 types of roads in Iceland:
- Paved roads
- Most of the ring road is paved and well maintained. Drivers should have no problem.
- Many drivers drive about ~10-15 kmh over the speed limit of 90. I would recommend staying under 10 kmh over.
- Passing slower drivers, RVs and trucks are fairly common on paved roads.
- Good gravel roads
- More like packed dirt road with no rocks or potholes. Fairly well maintained and drivers should have no problems.
- A good part of the road going into Westfjords and some of the roads IN Westfjords are like this.
- OK Gravel roads
- Definitely gravel and rocks but still manageable.
- Some parts of the road going into Westfjords, and a good part of the roads IN Westfjords are like this.
- The Öxi pass is in this category, though some people may put this in the BAD category. I found it to be ok, and I drove through heavy fog.
- BAD gravel roads
- The road going to Látrabjarg (bird cliff, west-most point of Europe) is BAD. Good size rocks and deep potholes everywhere.
- The worst gravel road I drove is the 4-5 kilometers I drove to the edge of the glacier. It was 100% gravel and rocks and I think I drove ~20 kmh the whole time on our little Honda Jazz.
- We didn’t rent a 4WD but driving these roads made me wish we did.
Almost none of the roads, regardless of the types above, have shoulders where you can stop. Most of the roads are fairly narrow. Sometimes there’s a bit of gravel space you can do a quick stop and take a few pictures but the car is still have on the road. And believe me, there are many places you want to stop and take pictures. So just be very careful and don’t stop at a location where other cars can’t see you (like at a turn).
There’s also very few guard rails on any of the roads, so sometimes you might be driving next to a steep cliff. There are some, just not many. For remote moutainous areas, I recommend using the middle of the road (yes, cross the line if there’s one) as that’s a bit safer and give you more space to maneuver. I’ve seen quite a few locals do that. Just make sure you watch out for curves or section of the roads where you have no clear visibility.
Most of the bridges in Iceland are single lane bridges. This means one side has to wait for the other side to cross first. Most of the time you should have no problem spotting cars on the other side. Between Vik and Reykjavik, however, most of the bridges seem to be two lanes. We did drive through one long-ish one-lane bridge that had expanded areas in some sections in the middle for cars to stop. I think it was between Höfn and Vik.
Keep your headlight on ALL THE TIME. This allows cars passing others to spot you from farther away. Also sometimes you will drive through pretty heavy fog, especially in the moutainous areas. We drove through a section on the East with heavy fog that lasted probably 30 minutes, and it was very difficult to see the car in front and behind us without their lights.
On passing, typically the slower car will turn on the right turn signal to let the car behind know that it’s ok to pass since the slower car typically has better visibility of what’s coming. Not sure if this is an official rule but it’s defintely practiced on the road by the locals.
Some of the forum posts suggested that gas stations are fairly far apart and cars should never have less than 1⁄4 tank of gas. While both statements are true, I never found that I would use 1⁄4 tank of gas before seeing a gas station. Maybe some of the bigger SUVs will see that, but not the Honda Jazz at 32 avg MPG.
Gas is EXPENSIVE. It was about $6.4/gallon when we were there. At 32 avg MPG, driving 2074 miles cost us over $400 in gas. I am sure we weren’t getting 32 MPG either since we went up and down a lot of mountains. So probably around $450 in gas.
Most of the gas stations you will see on the road are N1 gas stations. If you don’t have a credit card with PIN, I would recommend getting prepaid N1 cards that you can use at N1 gas stations. You can get these cards at any manned N1 gas station. There’s also OB and Olis gas stations but they are typically closer to towns. Our car rental company gave us a card that we can use to get 10% discount at any OB and Olis gas stations, so we used them as often as we can find them.
Last but not least, watch out for those tourists! They like to stop, sometimes in the middle of the road, to take pictures!
B Notes: By proxy, each stretch of our drives couldn’t be longer than two hours because of the A1’s and A2’s liquid intake. Like one of the Iceland blog I read, you may find yourself in need of the loo but it may be 150 km away. Most of the time, you won’t find a good spot to be unseen for your business. That said, all the gas stations we stopped had clean restrooms. You can also refill your water bottles, buy a hot dogs or two and pay more for less junk food. Another thing you need to pay close attention to are cylists who are sharing the narrow road with you. My jaw dropped a few times when I saw a cylist trying to ride through an area which are FAR from the next town. What took us 20 minutes from one town to another could be HOURS. Another impressive sight was when we saw a couple pulling a small trailer with an infant on our way to Dynjandi. We were at high altitude!!!. Other than the trailer, I also noticed the bright green Ikea children porter potty strapped to the very back of the pack on the bike.
Lodging and Accomodations
As we mentioned before, procrastinating probably cost us a good USD$200-300 more. So lessons learned here is to book lodging early. Also, you will have a lot more options.
Of the 11 nights we were there, 6 were through Airbnb and 5 were in guest houses we emailed directly. For guest houses, you should be able to book them directly from bookings.com if you do it early. However, with us doing last minute booking, we had to email every guest house we can find on the websites. Took us a while but we were finally able to find lodging for the entire trip.
So if you start your planning early, use Airbnb and Bookings.com. If you are procrastinators like us, I would recommend starting at visiticeland.com. From there, click through each of the regions you are visiting such as East, West, Westfjords, South, North, etc, and from there, you will click through to the regional sites such as south.is, east.is, northiceland.is. And from there, you will find the link for “where to stay” that will list all the guest houses or hotels in the areas. Almost of them will have emails or phone numbers you can use to contact them directly.
Altogether, we spent 2 nights in Reykjavik (Airbnb), 3 nights in Bjarkarholt (Westfjords, direct email) and 3 nights in Ólafsfjörður (North, Airbnb), 1 night in Höfn (Southeast, direct email, the locals apparently doesn’t want to be categorized as South or East), 1 night in Vik (South via direct email) and 1 night in Reykjanesbær (Airbnb).
Two of the areas we stayed, Bjarkarholt in Westfjords and Ólafsfjörður in the North, we would have preferred to stay closer to the attractions, but beggers can’t be choosers so we settled.
For the sharp-eyed readers, you will also notice that we skipped the West Iceland areas such as Snæfellsnes. We originally booked a night in Grundarfjörður via Airbnb, but due to some schedule change (adding the Into the Glacier tour), we had to skip the area. It is one of the regrets we have for this entire trip. If we had a couple more days (full 2 weeks), we would have spent the time there.
Oh one thing to note is that not all guest houses or Airbnb places provide shampoo or soap. So I would recommend you have a small bottle just in case.
B Notes: In one of the guest houses we stayed, the owner told us that we could have the European contiential breakfast because “everyone who stays can come eat here”. When we checked out, he charged each of us 10 Euro for breakfast. I wish he would have been more upfront about the cost and I wish I asked before we ate my 5 Euro two pieces of jelly toasts! We could use the 80 Euro towards our food budget.
Cash and Credit Cards
Every place, except one, that we went to, no matter how small or large, took credit cards. Even the paid WCs (toilets) took credit cards. So for the first time ever visiting a foreign country, I didn’t carry any local currency. The one place that didn’t take credit card is a guesthouse. But they do take USD for payment so I paid in USD cash.
I highly recommend getting a credit card with no foreign transaction fees. Otherwise you end up paying 3% (pretty typical) on top of every charge. NerdWallet’s Best No Foreign Transaction Fee Credit Cards of 2016 article is one of the best I’ve read. After going through it in details, I got a BankAmerica Travel Rewards card which had no annual fee.
If you plan to get a new card, I highly recommend getting one at least 3 months before your trip, so you can build up the credit and get the bank to increase the credit limit. Otherwise you are stuck at a couple of thousands of dollars in spending credit.
I also highly recommend getting a PIN for your card. While most manned loations will have paper copies that you can sign, some of the unmanned gas stations will only accept credit card with PINs.
B Notes: If you don’t plan to use plastic like we do for your trip, some coins will come in handy for restrooms and some hot pools (some hot springs require payment).
Food and Shopping for Food
This section is written by B since her mastery of food and budget cooking really helped us keep within budget.
Most supermarkets in Iceland don’t open until 11 and usually closes by 6 or 8 pm (1800 or 2000). We mainly shopped at Bónus but have done some food purchasing at gas stations, neighborhood supermarket and specialty shops. In a pinch, you can get snacks and food at gas stations when they are opened. Obviously, the price will not be as good as a limited operating hours of Bónus or other supermarkets.
Iceland supermarkets have walk in icebox where they keep all of perishable items. There, you can buy fruits (very limited as they are all imported), meat, and dairy products. Because of budget, I stayed close to pasta, potatoes and some meat (lamb loin was delicious). Since we didn’t have a cooler, I bought frozen vegetables as ice pack to keep our perishable items cold while we travelled from one destination to another.
Given all the coastlines in Iceland, I was surprised that there aren’t great selections of fresh seafood at the stores. I never had enough time to find out why. You can find loads of frozen seafood. I found a bag of seafood mix from Norway (?!). Lox and fresh salmon are available though. During our first trip to the grocery store, I simply asked the clerk which lox she liked and what should go with it. The lox and dill spread she recommended were delicious!
Perhaps we are spoiled from the fresh fruits in our area, I was disappointed at the fruit selections in the supermarket. During our trip, I only bought one orange (tasted good) and two golden delicious apples (:-< ). Like I mentioned above, I bought big bags of frozen cauliflowers and mixed vegetables to keep a balance diet for the family. Below is a sample shopping list. I try to stick to these items to create flexible menus for the family depends on the cooking appliances we have available for us at each location.
- Pastas (1lb bag could feed four of us with a little left over for a hearty breakfast)
- Eggs (hard boiled eggs are king. They provided good source of protein during long drives)
- potatoes
- Fresh leeks (great favorite to add to pasta or potato stew)
- Butter (sometimes they don’t have oil in place we stay; anything tastes better w/butter)
- Bread loafs (sliced bread may be better; a good butter/jelly sandwiches also help keep the kids quiet during long drives) J
- Canned diced tomatoes (didn’t work out in one of the places because there was no can opener)
- Rtiz cracker (not something I would buy in the US but easy snacks for young children)
- Yogurt/Yogurt drinks (you will find skyr; a taste Icelandic yogurt; some brands tastes better than others for us)
- Icelandic chocolate
- Maltsers
- Bacon
- Lamb loins (expensive but worth the money; I made a lamb, potato and leek stew that turned out well)
- Bacon
- Ham
- Hotdogs at gas stations (Sidenote of the hotdogs: each region put their sauce differently. Some put ketchup, mustard and mayo on the bun first before the hot dog. Also, their ketchup is a dark brown sauce rather than the bright red one in the US. You can add fresh onions or deep fried ones. The deep fried ones added a special crunch and flavor to the hotdog! Yumm!)
L Notes: If time works out, I would recommend stocking up at the Bónus Discount Store after getting your rental car.
Swimming Pools
This section is written by A1 and A2 since this is their favorite activity for the whole trip.
Nearly every town in Iceland has a swimming pool. Most of them have water slides. The swimming pool on the westman islands was a awesome experience, you first need to shower without a swimsuit and then enter the pool. When I first glimpsed the inside of the pool they had a basketball hoop in the water. When I hurryed outside I saw a 2 waterslides 1 with what seemed to be a trampoline after the tube, the other was just a regular waterslide with 3 connected together. There were 4 hot tubs 3 round and 1 big rectangular one. The other swimming pool is connected to a baby pool, another attraction is the rock climbing wall it has 2 faces 1 face is quite easier the other is has very small rocks/stones to climb on. The inside pool can get much deeper you should not take a child who can’t swim into the deep end. There is also a very shallow end that has the basketball hoop me and my father had great time playing with that.
Ólafsfjörður swimming pool me my mom and my sister and me went to this swimming pool again you had to shower without your swimming suit, the waterslide is superb it is mostly dark but here and there, there are strips of colored lights. There is a swimming pool with a shallow and deep end. A baby pool and 3 hot tubs. It is recommended if your kids like waterslides to get there early because if you arrive late it will be very crowded.
Itinerary
With 2 kids at 10 and 8 and needing a lot of sleep (10-12 hours or we will suffer the consequences later), our schedule is not at all rigorous. I am probably the more aggressive one in the family in having more activities, and probably would have preferred to see a couple more attractions, but at the end it all worked out.
Also, most people driving the ring road will do so counterclock-wise, we did it clock-wise. Looking back, I don’t think it would have made much difference. Either direction will work if you plan your itinerary right.
Day 1 - Arrival, Reykjavik, Swimming Pool
Our plane landed at ~4AM in the morning. We didn’t sleep much on the plane so we were all pretty tired. IceRentalCars had someone pick us up at the arrival hall and took us directly to the car rental office. After some quick paper work, we were handed the keys to a nice little blue Honda Jazz (aka Honda Fit in the US) and were on our way to Reykjavik.

We drove ~45 minutes to Reykjavik and found our Airbnb apartment, which wasn’t ready yet since it was early in the morning. However, A1 and A2 were extremely happy that they found a couple playgrounds. One of the playgrounds (64.141723, -21.922235) had an awesome zipline where A1 and A2 spent quite a bit of time.

We then visited the magnificent Hallgrimskirkja church, which is considered the most beautiful church in Reykjavik. Going to the top (about 400 or 500 ISK per person) gives you a awesome view of Reykjavik in all directions.
B Notes: In my humble opinion, the view on top was not impressive. I didn’t think it was worth the cost or hike. Inside the church, however, was wonderfully calm. When were there, an organist was playing the organ. I could spend more time there listening and taking in the impressive interior.

While we were there, we also stopped by Reykjavik Roasters for a quick cup of java and some pastry. In general we found the food to be pretty expensive there.
B Notes: The pastries at Reykjavik Roasters were delicious. We had crossiants and scone. The jam and butter were wonderfully fresh.

From Hallgrimskirkja, we walked to the Kolaportið flea market. Unfortunately it was not the best use of our time. Unless you are really into old stuff from flea markets, I would recommend avoiding this.
B Notes: Kolaportið flea market would have been a Goodwill not a flea market. I was hoping to see Icelandic antiques but what I saw were old crocs and new cheap plastic things from China. :-/
However, during our walk to the flea market we were able to see the city a bit and reminds me of Copenhagen. One thing we did notice is that there’s a lot of graffitis around.
B Notes: The graffitis added more colour and textures to the city. I wish I wasn’t as jet legged in order to enjoy them more.

After checking into the apartment and taking a nap, the kids wanted to go to a swimming pool. They have been wanting to go ever since they learned that every town has a public swimming pool. The Sundhöll swimming pool which is only a block from our apartment is the oldest swimming pool in the center of Reykjavik. Apparently lots of locals like to come to the pool early in the morning before starting their day. Unfortunately the two closest to us (including Sundhöll) are both closed for rennovation. So we ended up in Vesturbæjarlaug which is about 10 minutes drive away.
B Notes: Swimming pool and tramperlines seem to big part of Icelandic culture. After you paid at the pool, you can take off your shoes and socks. Icelanders seem to have a protocol of when to take of shoes and put them on in the pool. I can’t say I haven’t grasped the routine yet. Like A1 and A2 said, you are required to bath without swim suits on. There are diagram in the ladies locker room to show you which area of your body that you need to soap up. I have seen tourist being sent back to the shower if they come out of the locker dry at Myvatn Nature Baths. Of all the pools we have been, each has high chairs for mums to place their little wiggle bugs in while getting clean/dress. They also have little bath tubs which you could fill with water for your little nes to entertain themselves while getting clean/dress. What a thought!! Soaps are provide at all swimming pool. But if you want your fancy bath products, bring your own. Obiviously bring your own towels. One last thing, you are not allowed to bring cameras/mobile phones into the swimming area. So you can check them at the front desk or put them in the locker. Lifeguards are on the pool premise. But they don’t patrol the pool like the US. There seems to be a good understanding that parents will keep an eye on their children (as they should) while soaking in the shallow warm pools. I see parents who either take turn in playing with their infants in the shallow pools or sometimes slips a couple of floaties on their toddlers’ arms as soon as they get to the pool. Arm floaties are free and abundant at all the pools we have been. Sidenote: Iceland is an incredibly safe coountry. We have enjoyed all the days we speant there. The only mishap we had was at Westman Island. Upon fulfilling their dreams of playing at the “BEST” swimming pool in Iceland, A1 came out of the locker room without his long sleeve shirt, underwear (!!!) and his half of his REI pants (we unzipped the lower part of the pant legs to dry from our earlier beach outting). The pool front desk told us that it was the second incident that day. Once the staffs found out that A1 had no change of clothes, they went into the closet of all the abandoned clothes and gave him a smashing outfit. In the track pants he received, there was 1000 IKS. A1 did the right thing and returned the 1000 to the pool staffs. This is one incident that left all of us slightly puzzled, grossed out and tickeled.
Day 2 - Golden Circle (Þingvellir, Strokkur, Gullfoss, Kerið)
The second day of the trip was all about the Golden Circle. If you have just a short time (say 2-3 days) in Iceland, it’s definitely spending a day here. There’s plenty of tour companies that will take you around if you don’t have a car. We pretty much did the standard tour of Þingvellir, Strokkur, Gullfoss, and Kerið.
Þingvellir is our first real taste of the stunning scenery of Iceland. Even the bathroom had a really good view, though you had to pay for that privilege.

The kids also had a ton of fun playing by the river. The only thing is there are a TON of flies which I couldn’t stand. That’s one thing you will notice in most of the places – there are a TON of flies!

Strokkur Geysir is another standard stop on the Golden Circle. It supposedly was the first geyser described in a printed source and the first known to modern Europeans. The English word geyser derives from Geysir. We were told the geysir erupts every 10 minutes or so, which seems about right. We saw quite a few eruptions when we were there.

It’s also worth doing the little hike up to the top of the “hill” to see the beautiful view of the whole valley.

The third stop of Golden Circle is Gullfoss waterfall. This is the first waterfall we saw in Iceland and was definitely worth seeing. It is also one of the waterfalls you need to have waterproof jacket on if you want to get close to it.

The final stop for the Golden Circle was Kerið, which is a volcanic crater lake created as the land moved over a localized hotspot (according to Wikipedia). Kerið’s caldera is one of the three most recognizable volcanic craters because at approximately 3,000 years old, it is only half the age of most of the surrounding volcanic features.
A2 the explorer had a ton of fun walking around the lake (twice!). One thing to remember is the walk down to the lake is pretty steep sand surface. A2 had quite a scare as she RAN down hill by mistake and I couldn’t reach her fast enough. She was smart enough to grab onto the back of a bench, otherwise she would have been swimming in the lake.
B Notes: This is another reasons to wear good grip shoes!

As we were driving back from the Golden Circle, we also found a few unexpected places. One of them is an abandoned (and creepy looking) hotel (64.019916,-21.397170) that has a geothermal pool next to it. B and the kids thought that was a great discovery as the only way we saw the pool is after we hiked up a uncharted steep hill.
B Notes: Although it was spooky to find an abandon hotel and desserted geothermal pool. I wish we could spend more time to take this special find in. There were no other tourist in sight except us.

Day 3 - Into the Glacier, Driving to Westfjords
On day 3, we departed our Reykjavik apartment and ready to head up to Westfjords. We first stopped by Bónus as the Westfjords guesthouse owner told us to make sure we stock up on food before going there because the closest supermarket is like 140 kilometers away.
Before Westfjords, we went to our our Into the Glacier Adventure Tour. Into the Glacier offers various tours to Iceland‘s most significant new attraction, the man – made ice cave. The ice tunnel and the caves are located high on Europe‘s second largest glacier, Langjökull.
After driving a couple hours to Húsafell, we took the tour bus to the Klaki base camp (~30-40 minutes). The road from Húsafell to Klaki is a F road, which means 2WD cars cannot drive there. However, if you had your own 4WD, you can drive to the base camp yourself. And then from there, we took another ~30 minute ride on a glacier truck to get to the entrance of the glacier tunnel (64.627748, -20.486248). The glacier UN truck apparently is from Germany and was used to transport missiles.

Here are some interesting facts about the glacier tunnel:
- It took 4 years to prepare for the project and 14 months for the excavation.
- 5,500 m^3 of ice were exacavated for the tunnel and that only makes up 0.00275% of the overall glacier.
- The tunnel is 500 meters long and the largest of its kind in the world.
- We were 40 meters below the surface of the glacier, with 200 meters of solid ice still benneath us.
- One of the crevasse we walked by is 40 meters deep and a few hundred meters long.
- Sadly, the overall surface of the Langjökull glacier is receding at 2 meters per year due to global warming.


The kids had a lot of fun checking out the tunnels and tasting the glacier water. In fact, they said this is one of the best attractions in Iceland.
B Notes: Glacier water is delicious!! The Iceland often claims that we are drinking 1000 year old water! Glacier fuilfills 80% of Iceland’s water supplies.

After the glacier tour, we started our long drive to Ólafsfjörður, Westfjords where our guest house awaits. The road into Westfjords was mostly paved until we hit the fjords. From there, we were driving mostly on gravel roads. We didn’t know it at the time, but those roads were actually pretty good compared to what was to come.

The drive took us longer than expected partly because of the gravel road, but also partly because of the beautiful sceneries of the fjords. We stopped countless times to try to capture the stunning views. It was around 9:30PM when we noticed the sunset and it lasted until almost midnight.

Day 4 - Dynjandi, Swimming Pool, Látrabjarg
Our schedule on day 4 was a bit tough as I had a work call that I needed to take mid-afternoon. Thanks to the long days (~22 hours of day light), we were able to break our day into 2 halves and went to Dynjandi waterfall in the morning and went to Látrabjarg in the evening.
After a quick breakfast, we started driving to the waterfall. Again, it was gravel roads the whole time, and this time a bit worse than the gravel roads on the way into Westfjords. We also stopped at many places to take pictures. There was lakes and streams like this picture (65.646911,-23.265231) everywhere.

We also saw beautiful cloud-covered valleys. And all these were before we even got to our destination.

Finally we arrived at Dynjandi waterfall, which is actually a series of waterfalls with a cumulative height of 100 metres (330 ft). It is by far one of the most beautiful waterfalls we saw in Iceland. I think all of us rated it the highest amongst all of the waterfalls we visited.
B Notes: If you are there early, there may still be fog covering the top of the waterfall. Like A2 said…“it looked like it was pouring out of the sky.” A sight to be treasured for a long time to come…


Later in the evening, after my call and some swimming time for the kids, we headed out to Látrabjarg. It is described as
The cliffs of all cliffs, Látrabjarg, are home to birds in unfathomable numbers. This westernmost point of Iceland (and Europe if Greenland and the Azores are not counted) is really a line of several cliffs, 14 kilometres long and up to 441 m high. And it’s as steep as it gets, dizzyingly so.

Also, according to Wikipedia:
The cliffs are home to millions of birds, including puffins, northern gannets, guillemots and razorbills. It is vital for their survival as it hosts up to 40% of the world population for some species e.g. the Razorbill. It is Europe’s largest bird cliff, 14km long and up to 440m high.

The drive to Látrabjarg is by far one of the worst. The gravel road going there is full of potholes and sharp rocks. We even saw a big SUV had one of its tires blow out. I don’t think I drove more than 40 kmh most of the time. But at the end we think it’s well worth it.
B Notes: If you plan to go see the puffins, please go in the evening. You will likely to catch more (with your camera) because they are home for a much needed rest after a day out at sea for food. This is a spot I could stay long to take more pictures…or in hope to get better pictures.
Day 5 - Reykjafjardarlaug Hot Pool, Melanesrif
The guest house owner recommended the Reykjafjardarlaug Hot Pool (65.623331, -23.468465) to us. It is next to an abandoned swimming pool. There’s a shack where one can change. It turned out to be a great little spot where some visitors will stop and take a dip in this naturally heated pool. The hot pool has three sections with each having a different temperature. B really wanted to go so we went and spent sometime bathing in it.
Melanesrif is another recommendation from the owner. Westfjords is known for its miles-and-miles of golden sand beach and this is one of them.

We got there during tide change, and was able to watch the tide come in (actually got chased by the tide a bit). You can see from the following picture of the before and after of the beach. The tide also made these really interesting patterns.
B Notes: Be aware of the tide schedule. I can imagine it could get dicey if you have little ones in tow and are not careful.

Day 6 - Erpsstadir Cottage, Driving to Ólafsfjörður
Day 6 - time for us to say goodbye to Westfjords. We had a long drive to Ólafsfjörður in the North. I originally planned to stop by a couple of places but ended up abandoning the plan as it will make the drive too long. We did however stop at Erpsstadir Cottage (65.000469, -21.625192) which has a solid reputation for artisan ice cream and a range of other small-batch dairy products.
We met the raven, which supposedly is a famous bird for some reason, that the owner kept as pet, saw the cows (and pigs) and bought some ice cream and white chocolate they produced. I would say this is a place worth stopping if it’s on your way (which for most people driving the ring road it should be), but no need to make a special out-of-way trip for it.

The North in general is flatter and more green.

Maybe we were spoiled by the beautiful sceneries in Westfjords, we didn’t find the drive to the North as pretty. Well, until we saw the snow covered mountains surrounded by clouds, over the ocean. From there, we made multiple stops trying to capture the view, but ultimately failed.

Day 7 - Ólafsfjörður Swimming Pool, Tvistur Horseback Riding
Day 7 is a slow day. I originally planned for us to go whale watching, but B insisted that we let the kids sleep in and take it easy, given they had a long day stuck in the car. After the kids woke up, they went down to the public swimming pool (see the yellow spiral tube in the picture below) and spent a couple of hours there. One thing I will say is the Icelanders sure knows how to build public pools that are fun for the kids.

In the afternoon, we went for a nice horseback riding tour at Tvistur Horse Rental. We rode along a river and enjoyed the sceneries there.
B Notes: It was great fun for the whole family to ride together. Althought none of us are horse connoisseurs to fully appreciate the unique offerings of Icelandic horses, we had a great time riding with the owners of the horse farm. They took us along the river and actually crossing the river on horsebacks! Sidenotes: I also fell off my horse because of loose saddle. Luckily I grabbed onto the horse’s mane before falling off completely. Also, taking pictures on horseback is a challenge. My iPhone fell off my hand. The horses took pity on me and didn’t stepped on it.

Day 8 - Góðafoss, Grjótagjá, Myvatn Nature Baths
On day 8, we drove to the Lake Myvatn area. The first stop is the Góðafoss, or the waterfall of the gods. It is one of the more spectacular waterfalls in Iceland due to the width of 30 meters! While the waterfall is great, the kids had more fun jumping from rock to rock.

The second stop is the Grjótagjá cave. It was a popular bathing place until the 1975-84 vulcanic eruptions at Krafla brought magma streams under the area resulting in a sharp rise in water temperature to nearly 60 degrees centigrade. Today the water is around 43-46 degrees. In the following picture you can see steam coming from the heated water. The water itself is extremely clear and even with a blue tint.
It is also somewhat famous as it was featured in Game of Thrones where Jon Snow broke his vows in the cave (this is a kids friendly blog!) You can see A1 doing a bit of spelunking here.
If you are going to this cave, don’t follow Google Maps. This is one of the very few occasions that Google Maps failed us. It’s actually pretty easy to find as it’s right on Road 860. Just turn into 860 from Highway 1 and you will see a small parking lot after driving a bit.

The last stop of the day is to the Myvatn Nature Baths. We chose to go to this one instead of the Blue Lagoon because it’s less touristy according to many who went there. Later on we were told that the Blue Lagoon doesn’t drain! (Not fact checked so take it with a grain of salt.)

Day 9 - Dettifoss, Driving to Höfn
We departed the North (Ólafsfjörður, Akureyri, Lake Myvatn) on day 9 and started our journey to Höfn. However, we had to make one more stop at the Dettifoss waterfall, which is considered one of the most powerful waterfall in Europe, and the largest in Iceland by volume discharged. It is 100 metres (330 ft) wide and have a drop of 45 metres (150 ft) down to the Jökulsárgljúfur canyon, and have an average water flow of 193 m^3/second. Raincoat definitely recommended for this one.

The drive to Höfn was made complicated because we were driving through heavy fog in several areas. In one case we drove probably for a good 20-30 minutes in heavy fog where we had a hard time seeing the car infront and the one behind. We also took the Öxi pass which is a gravel road that has steep inclines and declines. The locals generally don’t recommend it as it doesn’t save much time and it’s closed during the winter.
We stayed at the Dynjandi Guesthouse right outside of Höfn. The owner is a Icelandic native, and is extremely nice and very passionate about Iceland. She gave us a tour of her farm where she kept 35 horses and 40+ sheeps. Also explained many of the Icelandic traditions to us, as well as recommended several places to visit.

Day 10 - Edge of Glacier, Ice Lagoon Zodiac Boat Tour, Driving to Vik
On the Dynjandi Guesthouse owner’s recommendation, we headed out in the morning to see the glacier by Hoffell. It took us a good 30 minutes to drive 5 kilometers of gravel road to finally get to the edge of the glacier (64.418780,-15.403394).

Day 10’s main event is the Ice Lagoon Zodiac Boat Tour. It is by far a better tour compare to the Amphibian Boat Tour, if you can stomach the ride to the glacier wall, as the rides on high speed rafts can be quite bumpy. The tour actually doesn’t recommend bringing children under the age of 10, but A2 was 8 and was fine. She was grinning ear to ear while she bummed along for the long ride to the edge of the glacier.

On the Zodiac we are able to cover large areas of the lagoon and get closer to the icebergs than on the amphibian. When possible the Zodiac goes almost all the way up to the glacier (as close as safe). Passengers are provided with flotation suites (very warm) and a life jacket.

The kids also had a lot of fun playing by the lagoon and making ice stacks.

After the lagoon, we drove straight to Vik.
Day 11 - Reynisfjara, Vestmannaeyjum, Seljalandsfoss, Driving to Reykjanesbær
According to Guide to Iceland,
Reynisfjara is a black pebble beach and features an amazing cliff of regular basalt columns resembling a rocky step pyramid, which is called Gardar. Out in the sea are the spectacularly shaped basalt sea stacks Reynisdrangar. The area has a rich birdlife, including puffins, fulmars and guillemots.
We went down to Reynisfjara on the morning of day 11 and spent some time there. The kids loved the beach and played in the water even though it was cold. The view was certainly magnificent.

After the beach, we took the ferry (Herjolfur) to Vestmannaeyjum, or the Westman Islands. According to Wikipedia,
Vestmannaeyjar is a town and archipelago off the south coast of Iceland. The largest island, Heimaey, has a population of 4,135. The other islands are uninhabited, although six have single hunting cabins.
We spent most of our time there at the public pool and eating the best meal in Iceland.

Our last attraction stop of the Iceland trip is the Seljalandsfoss waterfall which is interesting because visitors can go behind the waterfall via a small trail. Again, waterproof jacket highly recommended.

Day 12 - Shopping, Departure
Day 12 and our final day in Iceland before heading back to the US. We did mostly shopping in the morning before returning the car to IceRentalCars and taking the shuttle to the airport.
B Notes: We didn’t eat fermented shark or other exotic treats but we had an amazing time in beautiful Iceland. We are bequeathed with fond memories by vast and picturesque landscape as well as genersity of Icelanders. This trip has opened our hearts and taught us more things than we have ever expected.









Security Companies in Silicon Valley 10 Jun 2016 8:57 PM (8 years ago)
Here’s a Google map of the security companies in Silicon Valley.
A Modern App Developer and An Old School System Developer Walk Into a Bar 14 Feb 2016 9:57 AM (9 years ago)
Note: Thanks for all the great comments and feedback here and on Hacker News. Please keep them coming. I learned a ton and I am sure others will also.
Happy Valentine’s Day!
A modern app developer and an old school system developer walk into a bar. They had a couple drinks and started talking about the current state of security on the Internet. In a flash of genius, they both decided it would be useful to map the Internet and see what IPs have vulnerable ports open. After some discussion, they decided on the following
- They will port scan all of the IPv4 address (2^32=4,294,967,296) on a monthly basis
- They will focus on a total of 20 ports including some well-known ports such as FTP (20, 21), telnet (23), ssh (22), SMTP (25), etc
- They will use nmap to scan the IPs and ports
- They need to store the port states as open, closed, filtered, unfiltered, openfiltered and closedfiltered
- They also need to store whether the host is up or down. One of the following two conditions must be met for a host to be “up”:
- If the host has any of the ports open, it would be considered up
- If the host responds to ping, it would be considered up
- They will store the results so they can post process to generate reports, e.g.,
- Count the Number of “Up” Hosts
- Determine the Up/Down State of a Specific Host
- Determine Which Hosts are “Up” in a Particular /24 Subnet
- Count the Number of Hosts That Have Each of the Ports Open
- How Many Total Hosts Were Seen as “Up” in the Past 3 Months?
- How Many Hosts Changed State This Month (was “up” but now “down”, or was “down” but now “up”)
- How Many Hosts Were “Down” Last Month But Now It’s “Up”
- How Many Hosts Were “Up” Last Month But Now It’s “Down”
Modern App Developer vs Old School Developer
Let’s assume 300 million IPs are up, and has an average of 3 ports open.
- How would you architect this?
- Which approach is faster for each of these tasks?
- Which approach is easier to extend, e.g., add more ports?
- Which approach is more resource (cpu, memory, disk) intensive?
Disclaimer: I don’t know ElasticSearch all that well, so feel free to correct me on any of the following.
Choose a Language
Modern App Developer:
I will use Python. It’s quick to get started and easy to understaind/maintain.
Old School Developer:
I will use Go. It’s fast, performant, and easy to understand/maintain!
Store the Host and Port States
Modern App Developer:
I will use JSON! It’s human-readable, easy to parse (i.e., built in libraries), and everyone knows it!
{
"ip": "10.1.1.1",
"state": "up",
"ports": {
"20": "closed",
"21": "closed",
"22": "open",
"23": "closed",
.
.
.
}
}
For each host, I will need approximately 400 bytes to represent the host, the up/down state and the 20 port states.
For 300 million IPs, it will take me about 112GB of space to store all host and port states.
Old School System Developer:
I will use one bit array (memory mapped file) to store the host state, with 1 bit per host. If the bit is 1, then the host up; if it’s 0, then the host is down.
Given there are 2^32 IPv4 addresses, the bit array will be 2^32 / 8=536,870,912 or 512MBs
I don’t need to store the IP address separately since the IPv4 address will convert into a number, which can then be used to index into the bit array.
I will then use a second bit array (memory mapped file) to store the port states. Given there are 6 port states, I will use 3 bits to represent each port state, and 60 bits to represent the 20 port states. I will basically use one uint64 to represent the port states for each host.
For all 4B IPs, I will need approximately 32GB of space to store the port states. Together, it will take me about 33GB of space to store all host and port states.
I can probably use EWAH bitmap compression to gain some space efficiency, but let’s assume we are not compressing for now. Also if I do EWAH bitmap compression, I may lose out on the ability to do population counting (see below).
Count the Number of “Up” Hosts
Modern App Developer:
This is a big data problem. Let’s use Hadoop!
I will write a map/reduce hadoop job to process all 300 million host JSON results (documents), and count all the IPs that are “up”.
Maybe this is a search problem. Let’s use ElasticSearch!
I will index all 300M JSON documents with ElasticSearch (ES) on the “state” field. Then I can just run a query that counts the results of the search where “state” is “up”.
I do realize there’s additional storage required for the ES index. Let’s assume it’s 1⁄8 of the original document sizes. This means there’s possibly another 14GB of index data, bringing the total to 126GB.
Old School System Developer:
This is a bit counting, or popcount(), problem. It’s just simple math. I can iterate through the array of uint64’s (~8.4M uint64’s), count the bits for each, and add them up!
I can also split the work by creating multiple goroutines (assuming Go), similar to map/reduce, to gain faster calculation.
Determine the Up/Down State of a Specific Host
Modern App Developer:
I know, this is a search problem. Let’s use ElasticSearch!
I will have ElasticSearch index the “ip” field, in addition to the “state” field from earlier. Then for any IP, I can search for the document where “ip” equals the requested IP. From that document, I can then find the value of the “state”.
Old School System Developer:
This should be easy. I just need to index into the bit array using the integer value of the IPv4, and find out if the bit value is 1 or 0.
Determine Which Hosts are “Up” in a Particular /24 Subnet
Modern App Developer:
This is similar to searching for a single IP. I will search for documents where IP is in the subnet (using CIDR notation search in ES) AND the “state” is “up”. This will return a list of search results which I can then iterate and retrieve the host IP.
Or
This is a map reduce job that I can write to process the 300 million JSON documents and return all the host IPs that are “up” in that /24 subnet.
Old School System Developer:
This is just another bit iteration problem. I will use the first IP address of the subnet to determine where in the bit array I should start. Then I calculate the number of IPs in that subnet. From there, I just iterate through the bit array and for every bit that’s 1, I convert the index of that bit into an IPv4 address and add to the list of “Up” hosts.
Count the Number of Hosts That Have Each of the Ports Open
For example, the report could simply be:
20: 3,023
21: 3,023
22: 1,203,840
.
.
.
Modern App Developer:
This is a big data problem. I will use Hadoop and write a map/reduce job. The job will return the host count for each of the port.
This can probably also be done with ElasticSearch. It would require the port state to be index, which will increase the index size. I can then count the results for the search for ports 22 = “open”, and repeat for each port.
Old School System Developer:
This is a simple counting problem. I will walk through the host state bit array, and for every host that’s up, I will use the bit index to index into the port state uint64 array and get the uint64 that represents all the port states for that host. I will then walk through each of the 3-bit bundles for the ports, and add up the counts if the port is “open”.
Again, this can easily be paralleized by creating multiple goroutines (assuming Go).
How Many Total Hosts Were Seen as “Up” in the Past 3 Months
Modern App Developer:
I can retrieve the “Up” host list for each month, and then go through all 3 lists and dedup into a single list. This would require quite a bit of processing and iteration.
Old School System Developer:
I can perform a simple OR operation on the 3 monthly bit arrays, and then count the number of “1” bits.
_Note: I fixed the original AND to OR based on a comment from HN. Not sure what I was thinking when I typed AND…duh!
How Many Hosts Changed State This Month (was “up” but now “down”, or was “down” but now “up”)
Modern App Developer:
Hm…I am not sure how to do that easily. I guess I can just iterate through last month’s hosts, and for each host check to see if it changed state this month. Then for each host that I haven’t checked this month, iterate and check that list against last month’s result.
Old School System Developer:
I can perform a simple XOR operation on the bit arrays from this and last month. Then count the number of “1” bits of the resulting bit array.
How Many Hosts Were “Up” Last Month But Now It’s “Down”
Modern App Developer:
I can retrieve the “Up” hosts from last month from ES, then for each “Up” host, search for it with the state equals to “Down” this month, and accumulate the results.
Old School System Developer:
I can perform this opeartion:
(this_month XOR last_month) AND last_month. This will return a bit array that has the bit set if the host was “up” last month but now it’s “down”. Then count the number of “1” bits of the resulting bit array.
How Many Hosts Were “Down” Last Month But Now It’s “Up”
Modern App Developer:
I can retrieve the “Down” hosts from last month from ES, then for each “Down” host, search for it with the state equals to “Up” this month, and accumulate the results.
Old School System Developer:
I can perform this opeartion:
(this_month XOR last_month) XOR this_month. This will return a bit array that has the bit set if the host was “down” last month but now it’s “up”. Then count the number of “1” bits of the resulting bit array.
2016: Analyzing Security Trends Using RSA Exhibitor Descriptions 5 Feb 2016 9:57 AM (9 years ago)
The data used for this post is available here. A word of warning, I only have complete data set for 2014-2016. For 2008-2013, I have what I consider to be representative samples. So please take the result set with a big bucket of salt.
Continuing my analysis from last year, this post analyzes the exhibitors’ descriptions from the annual security conference, RSA 2016. Intuitively, the vendor marketing messages should have a high degree of correlation to what customers care about, even if the messages trail the actual pain points slightly.
Some interesting findings:
- The word hunt has appeared for the first time since 2008. It only appeared 6 times and ranked pretty low, but that’s a first nonetheless.
- The word iot jumped 881 spots to 192 in 2016, after showing up for the first time in 2015. This may indicate the strong interest in IoT security.
- There’s no mention of docker in any of the years, and only 5 mentions of container in 2016. This is a bit of a surprise given the noise docker/container is making. This is likely due to most customers care more about management for new technologies than security.
- The word firewall dropped 151 spots in 2016. I want to speculate that it is due to the dissolving of perimeters, but I can’t be sure of that.
- As much as noise as blockchain is making, there’s no mention of the word.
- The word behavior (as in behavioral analysis) has also gained drastically over the past few years, going from #370 in 2012 to #78 in 2016.
- See other findings below.
Top Words
The top words that vendors use to describe themselves haven’t changed much. The following table shows the top 10 words used in RSA conference exhibitor descriptions since 2008. You can find the complete word list here.
| # | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | secure | secure | secure | secure | secure | secure | secure | secure | secure |
| 2 | solution | solution | solution | solution | solution | solution | solution | solution | solution |
| 3 | network | manage | manage | network | provide | provide | provide | provide | provide |
| 4 | provide | provide | network | provide | manage | manage | network | data | data |
| 5 | manage | data | protect | manage | network | service | manage | network | threat |
| 6 | enterprise | network | provide | data | information | more | data | protect | network |
| 7 | data | company | data | information | software | software | protect | threat | protect |
| 8 | product | service | organization | enterprise | enterprise | information | threat | manage | manage |
| 9 | technology | software | information | technology | data | enterprise | service | service | enterprise |
| 10 | application | busy | risk | product | more | customer | enterprise | enterprise | service |
Here’s a word cloud that shows the 2016 top words. You can also find word clouds for 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015.

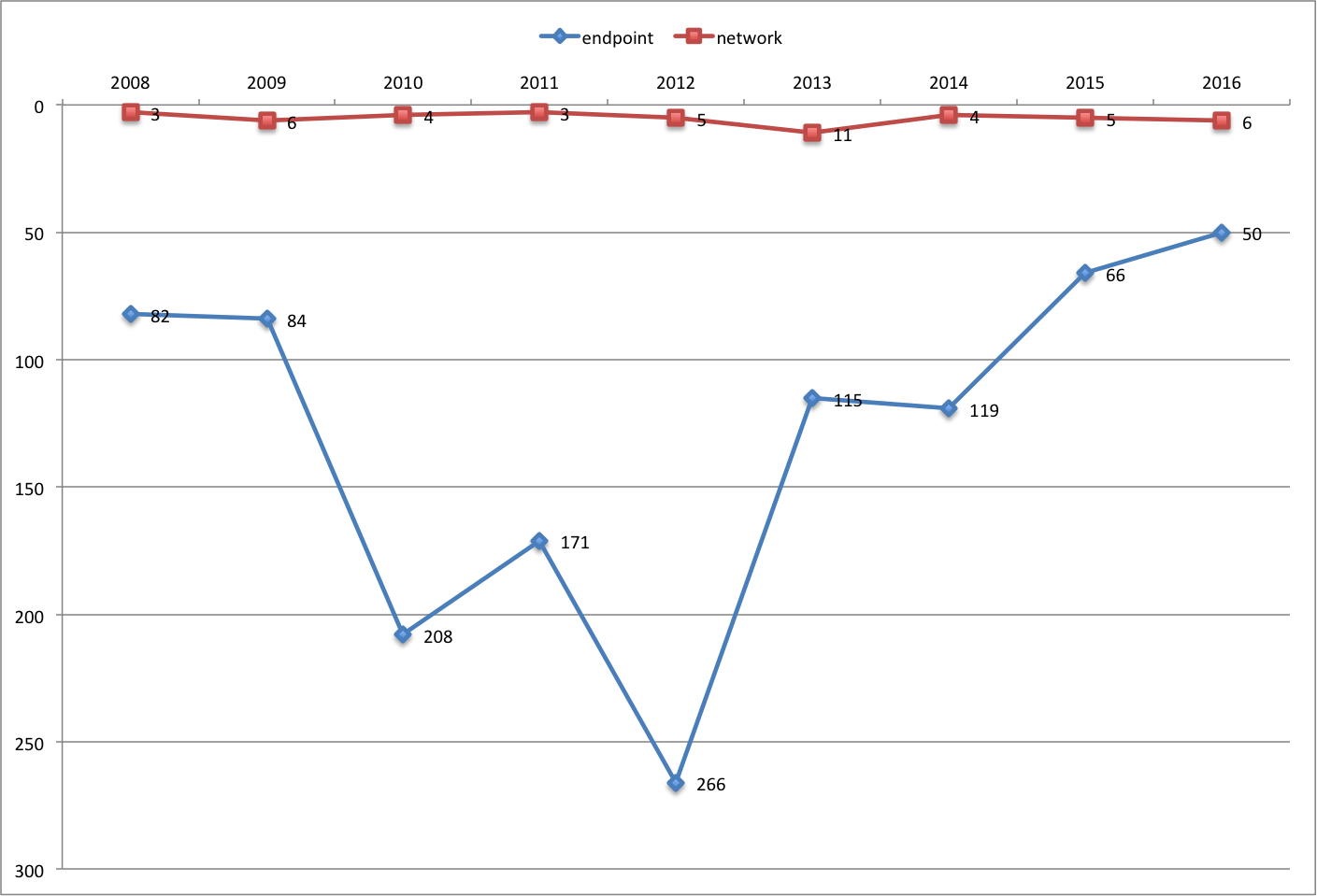
Endpoint vs. Network
While the word network has mostly maintained its top 10 position (except 2013 when it fell to #11), the big gainer is the word endpoint, which improved drastically from #266 in 2012 to 2016’s #50. This may indicate that enterprises are much more accepting of endpoint technologies.
I also speculate that there might be a correlation between the increase in cloud and the increase in endpoint. As the perimeters get dissolved due to the move to cloud, it’s much more difficult to use network security technologies. So enterprises are looking at endpoint technologies to secure their critical assets.
Compliance vs. Threat
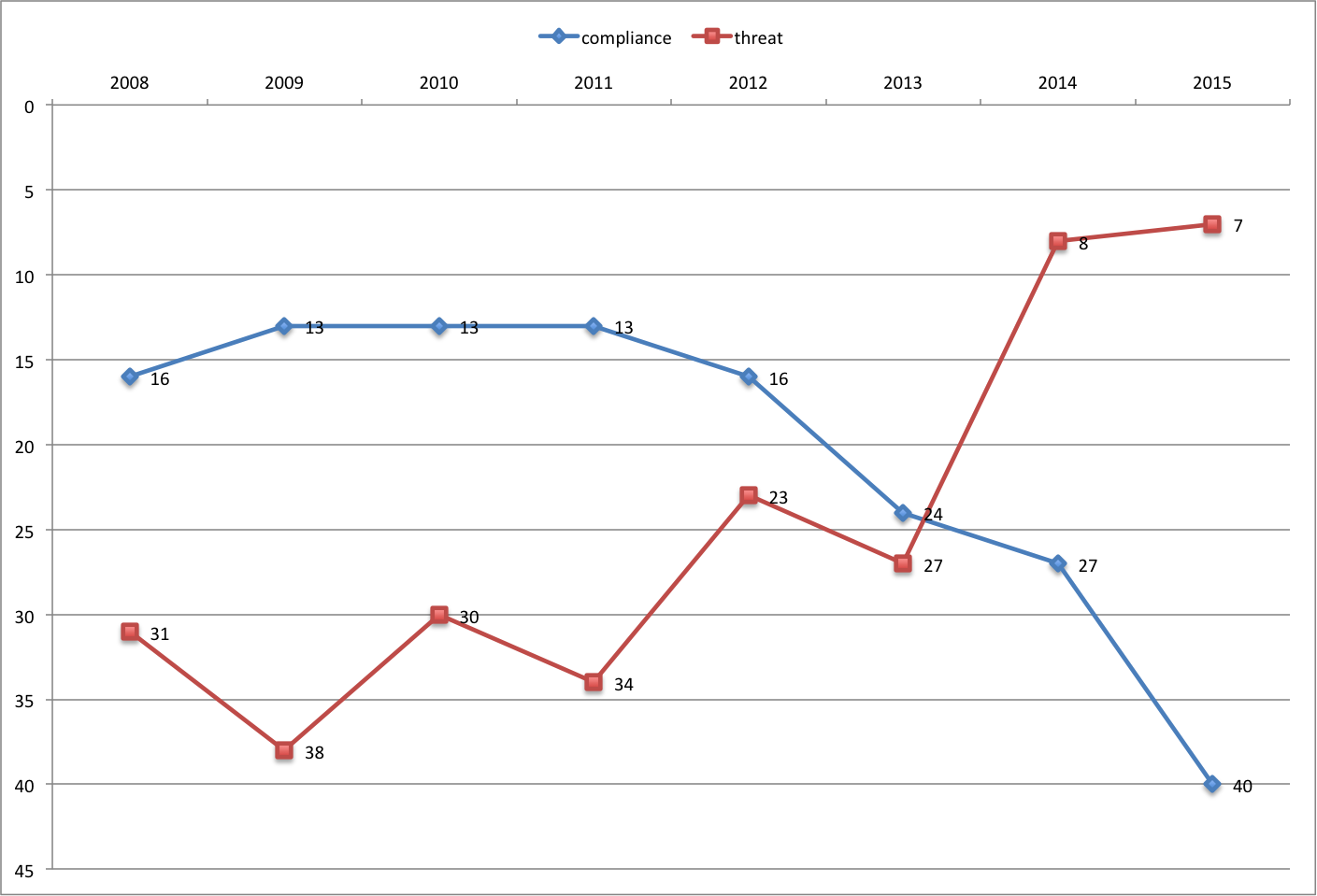
Not surprisingly, the use of the word compliance continues to go down, and the word threat continues to go up.
The number of mentions for threat intelligence remained at 22 for both 2015 and 2016, after jumping from 12 in 2014.

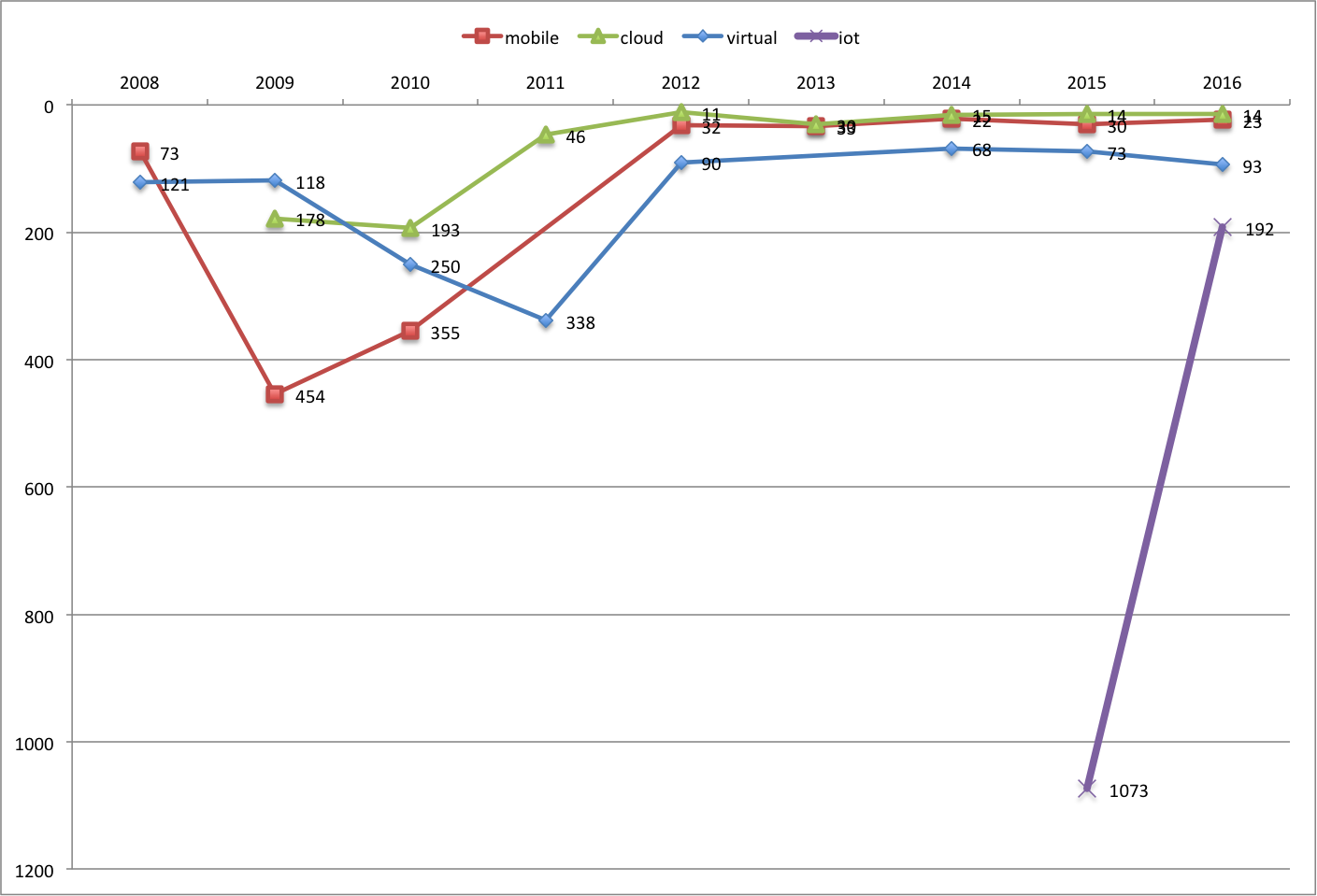
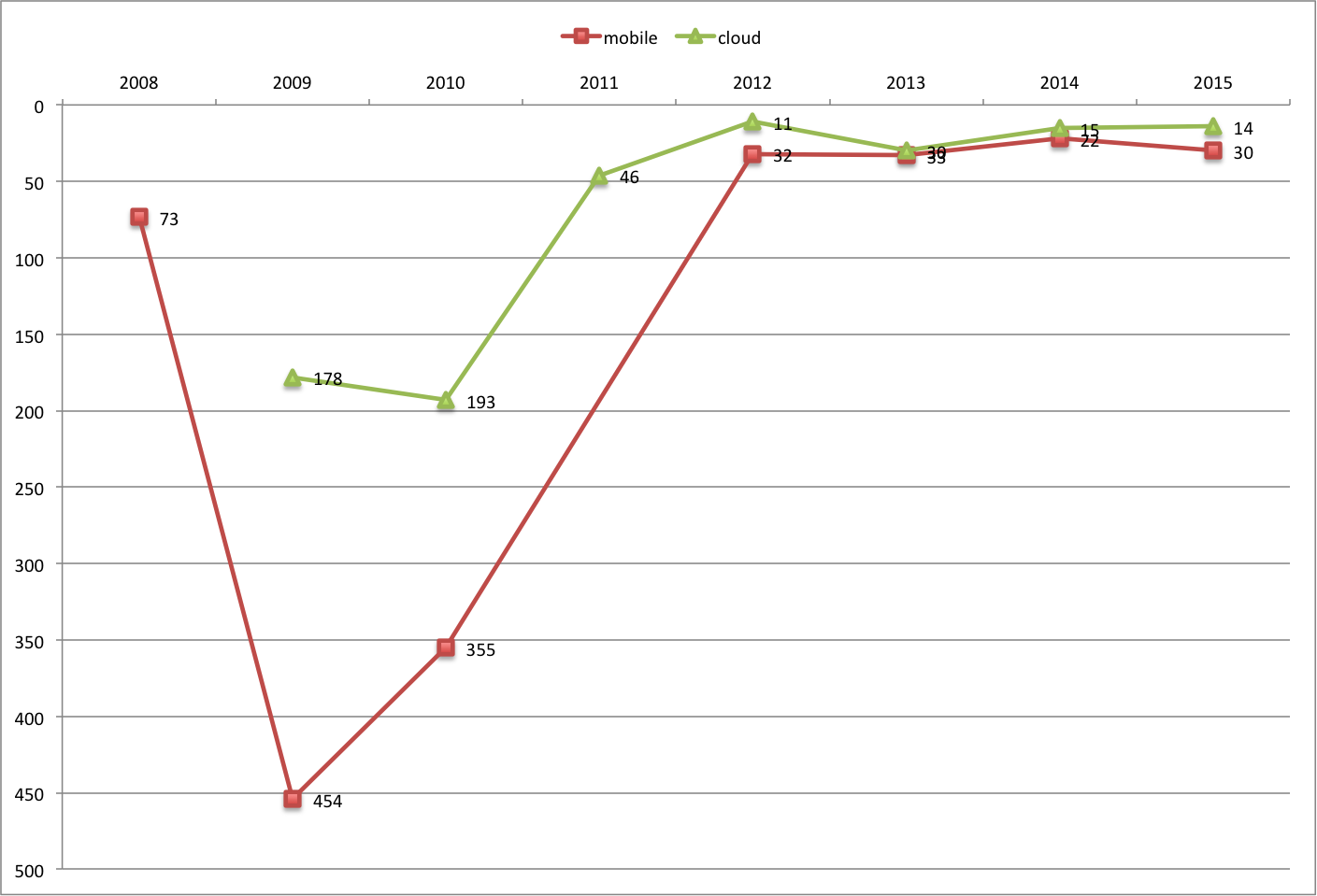
Mobile, Cloud, Virtual and IoT
While the words mobile and cloud maintained their relative positioning in 2016, we can also see virtual continues its slight downward trend.
Interestingly, the word iot made a big jump, going from position #1073 in 2015 to #193 in 2016. This potentially indicates a strong interest in security for internet of things. In general, the IoT space has seen some major activities, including Cisco’s recent acquisition of Jasper.
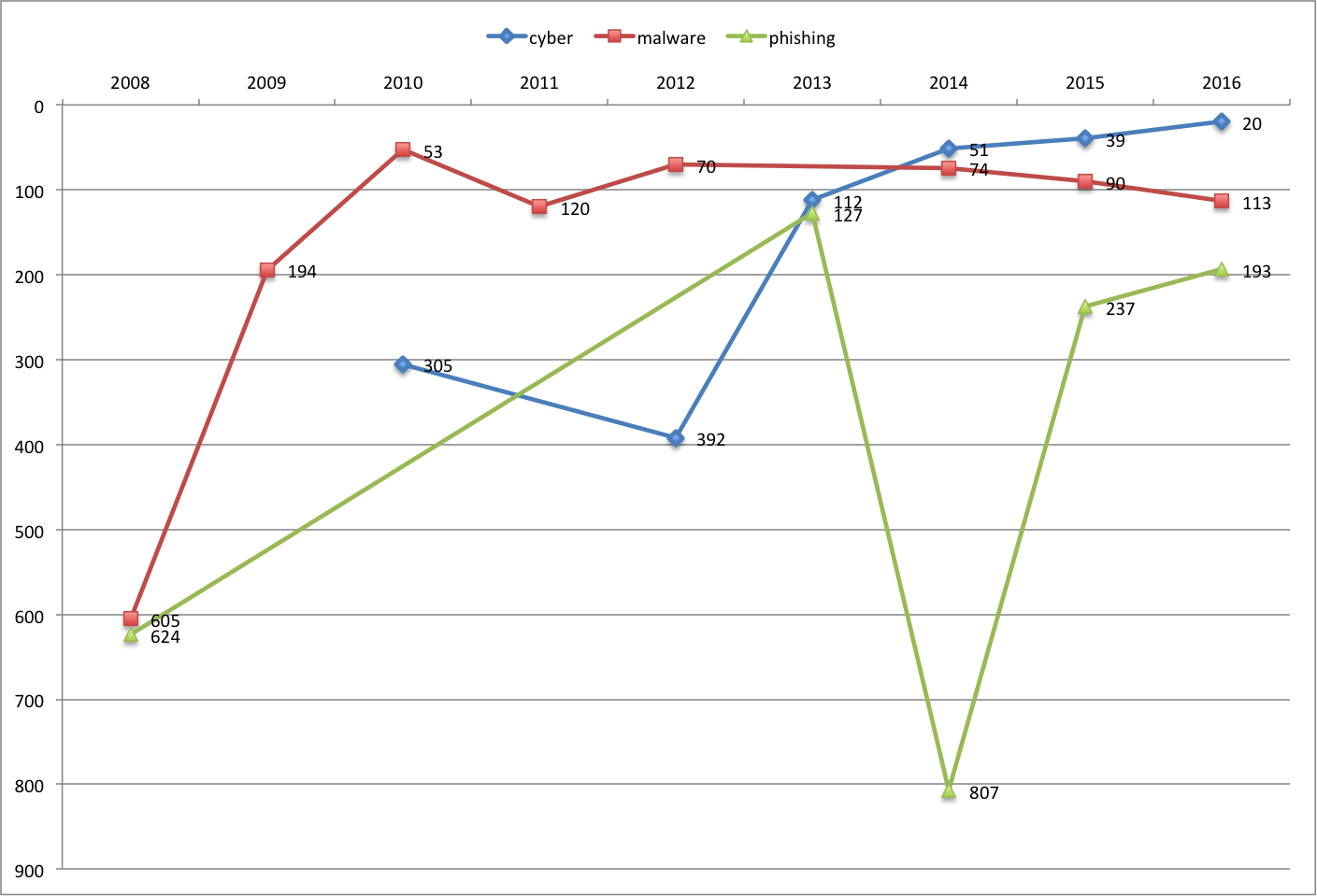
Cyber, Malware and Phishing
The word cyber continues to gain popularity in the past 4 years; however, the word malware has fell below the top 100, a position it maintained since 2010.
The word phishing made drastic gains since 2014, jumping from #807 to #193 in 2016. This may indicate that enterprises are seeing more attacks from phishing, and vendors are targeting that specific attack vector.
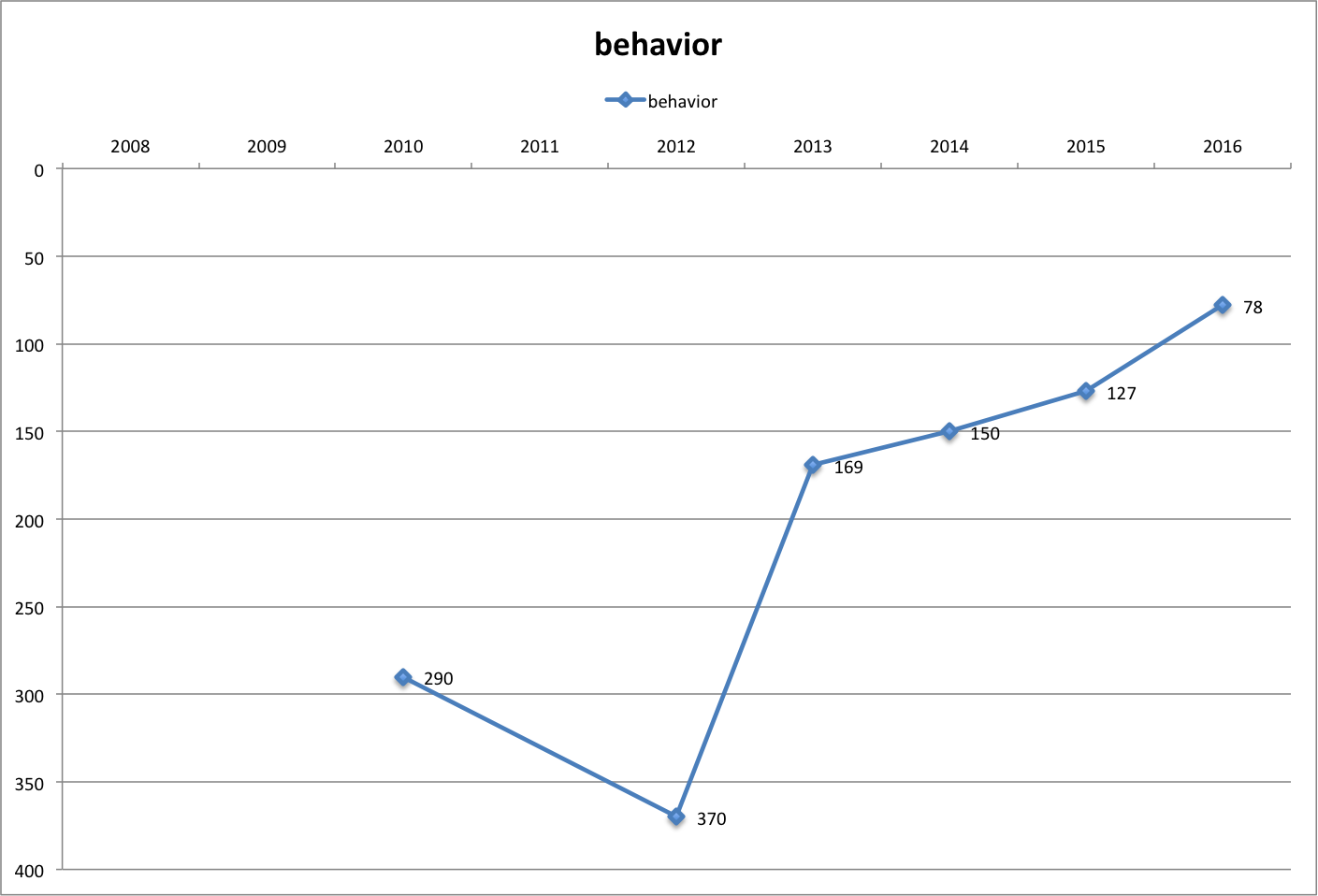
It’s all about Behavior!
The word behavior (as in behavioral analysis) has also gained drastically over the past few years, going from #370 in 2012 to #78 in 2016.
Credits
- The word clouds and word rankings are generated using Word Cloud.
- The actual vendor descriptions are gathered from the RSA web site as well as press releases from Business Wire and others.
- Charts are generated using Excel, which continues to be one of the best friends for data analysts (not that I consider myself one).
Installing Windows 7 on Macbook Late 2008 20 Apr 2015 8:32 PM (10 years ago)
Over the weekend I wanted to install Windows in a bootcamp partition so the kids can use it to do their Chinese homework. The Chinese homework CD unfortunately only works in Windows so I had no choice!! I guess I could have taken other routes, like installing Windows in a VM or something, but I figure that Mac has this awesome tool called bootcamp, why not use that?
Well, how wrong I was! I went through a whole day of head-scratching, temper-inducing, word-cussing, USB-swapping and machine-rebooting exercise of getting Windows installed in the bootcamp partition. I almost went as far as buying a replacement superdrive for the macbook, but at the end I finally was able to get Windows 7 onto the Macbook.
To start, my laptop is a Macbook, Aluminum, Late 2008 (MB467LL/A) with a busted optical drive (superdrive). I originally had Mavericks running on it but before this exercise I wiped it clean and installed Yosemite on it. Because the optical drive is busted, I cannot use the Windows 7 DVD, so I had to do this using a USB flash drive.
Below are the steps I took to make this work. I can’t guarantee that these steps will work for you, but it’s probably good as a reference. Having seen a ton of articles on the problems people had with bootcamp, I hope no one has to go through the troubles I went through.
- It took me a while to figure this out (after reading numerous online posts), if your Mac has an optical drive, Boot Camp Assistant will NOT create a USB flash drive-based install disk. The only way to trick the system to do that is to do the following: (Though it turns out at the end that this step is quite useless, since the USB install disk created by Boot Camp Assistant couldn’t boot! So you could really skip this step.)
- Modify Boot Camp Assistant’s Info.plist as described here.
- After the modification, you need to resign Boot Camp Assistant, or else it will keep crashing. To do that, following the instructions here. For the impatient, run the command
sudo codesign -fs - /Applications/Utilities/Boot\ Camp\ Assistant.app.
- Start “Boot Camp Assistant”, and select the options “Download the latest Windows Support”, and “Install Windows 7 or later versions”.
- Note I am not selecting the option to create a Windows install disk. It turned out the USB install disk didn’t boot. I keep getting the “non-system disk, press any key to continue” error, and basically that’s the end.
- In any case, these two tasks should download the bootcamp drivers onto a USB drive, and also partition the Mac’s HD into two partitions. One of the parititions is the BOOTCAMP partition, which will be used to install Windows 7.
- Once that’s done, I needed to create a bootable Windows 7 USB Flash drive.
- If you search the web, you will find that most people run into two problems. The first is the bootcamp-created flash drive giving the “non-system disk” error, and the second is the boot up hangs with a blank screen and a flash underscore cursor at the top left corner. I’ve ran into both. You will also find some articles that explain how to make the flash drives bootable using fdisk, but that didn’t work for me either.
- Finally I found a post online that pointed to the Windows USB/DVD Download Tool. It’s a Windows program that can create a bootable USB flash drive from a Windows 7 or 8 ISO file.
- Note though, not all the USB flash drives are created equal. The PNY 16GB drive I used didn’t work. WUDT ended with an error that says it couldn’t run bootsect to create the boot sectors on the flash drive. The one that worked for me was Kingston Data Traveler 4GB.
- Now that I have the bootable USB flash drive, I plugged that into the Mac and started it up. This time the installation process got started.
- When Boot Camp Assistant created the BOOTCAMP partition, it did not format it to NTFS. So the first thing I noticed was that when I select the BOOTCAMP partition, the installer said it cannot be used because it’s not NTFS.
- The option to format the partition is not immediately obvious, but I had to click on “Drive options (advanced)” and select the option to format the partition.
- Once that’s done, I encountered another error that says the drive may not be bootable and I need to change the BIOS setting. Yeah at this point I was pretty ticked and the computer heard a few choice words from me. Doesn’t matter what I do it doesn’t seem to let me pass this point.
- I did a bunch more readings and research, but nothing seem to have worked. I finally decided to turn the computer off and come back to it. Magically it worked the second time I tried to install it. I was no longer getting the non-bootable disk error. My guess is that after the NTFS formatting, the installer needs to be completely restarted.
- In any case, at this point, it was fairly smooth sailing. The installation process took a bit of time but overall everything seemed to have worked.
- After the installation, I plugged int the bootcamp flash drive with the WindowsSupport files, and installed them.
I am still not a 100% yet. The trackpad still doesn’t behave like when it’s on the Mac. For example, I can’t use the two finger drag to scroll the windows, and for the life of me, I cannot figure out how to easily (and correctly) set the brightness of display. But at least now I have a working Windows 7 laptop!
Analyzing Security Trends Using RSA Exhibitor Descriptions 22 Mar 2015 9:57 AM (10 years ago)
The data used for this post is available here. A word of warning, I only have complete data set for 2014 and 2015. For 2008-2013, I have what I consider to be representative samples. So please take the result set with a big bucket of salt.
After going through this analysis, the big question I wonder out loud is:
How can vendors differentiate from each other and stand above the crowd when everyone is using the same words to describe themselves?
The annual security conference, RSA 2015, is right around the corner. Close to 30,000 attendees will descend into San Francisco Moscone Center to attend 400+ sessions, listen to 600+ speakers and talk to close to 600 vendors and exhibitors.
For me, the most interesting aspect of RSA is walking the expo floor, and listening to how vendors describe their products. Intuitively, the vendor marketing messages should have a high degree of correlation to what customers care about, even if the messages trail the actual pain points slightly.
This post highlights some of the unsurprising findings from analyzing 8 years worth of RSA Conference exihibitor descriptions.
It is interesting how almost all vendor descriptions use the same set of words to describe themselves, and these words mostly haven’t changed over the past 8 years. For example, the following table shows the top 10 words used in RSA conference exhibitor descriptions for the past 8 years. You can find the complete word list at …
| # | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 |
|---|---|---|---|---|---|---|---|---|
| 1 | secure | secure | secure | secure | secure | secure | secure | secure |
| 2 | solution | solution | solution | solution | solution | solution | solution | solution |
| 3 | network | manage | manage | network | provide | provide | provide | provide |
| 4 | provide | provide | network | provide | manage | manage | network | data |
| 5 | manage | data | protect | manage | network | service | manage | network |
| 6 | enterprise | network | provide | data | information | more | data | protect |
| 7 | data | company | data | information | software | software | protect | threat |
| 8 | product | service | organization | enterprise | enterprise | information | threat | manage |
| 9 | technology | software | information | technology | data | enterprise | service | service |
| 10 | application | busy | risk | product | more | customer | enterprise | enterprise |
Here’s a word cloud that shows the 2015 top words. You can also find word clouds for 2008, 2009, 2010, 2011, 2012, 2013, 2014.

Compliance Down, Threats Up
While the macro trend has not changed dramatically for the exhibitor descriptions, there have been some micro trends. Here are a couple of examples.
First, the use of the word compliance has gone down over the years, while the word threat has gone up. After 2013, they changed places with each other.
This finding is probably not surprising. At the end of 2013, one of the biggest breaches, Target, happened. And over the next two years we’ve seen major breaches of Sony, Anthem, Home Depot, Premera and many others. Threats to both the corporate infrastructure as well as top executive jobs (just ask Target’s CEO Gregg Steinhafel, or Sony’s Co-Chairwoman Amy Pascal) are becoming real. So it seems natural for the marketers to start using the word threat to highlight their solutions.
Compliance was a big use case in security for many years, and many vendors have leveraged the need for compliance to build their company and revenue pipeline since the mid-2000s. However, use cases can only remain in fashion for so long before customers get sick of hearing about them, and vendors need new ways of selling their wares to customers. So it looks like compliance is finally out of fashion around 2011 and started declining in exhibitor descriptions.
Mobile and Cloud Up
The words mobile and cloud has gained dramatically in rankings over past 8 years. In fact, it’s been consistently one of the top words used in the last 4. For anyone who hasn’t been hiding under a rock in the past few years, this is completely unsurprising.
The cloud war started to heat up back in 2009 when most major service providers have felt the Amazon Web Services threat and all wanted to build their own clouds. In fact, I joined VMware in 2009 to build out their emerging cloud infrastructure group to specifically help service providers build their cloud infrastructures. Eventually, in 2011, VMware decided to get into the game and I built the initial product and engineering team that developed what it’s now known as vCloud Air (still have no idea why this name is chosen).
As more and more workloads move to the cloud, requirements for protecting cloud workloads quickly appeared, and vendors natually started to position their products for the cloud. So the rise in cloud rankings matches what I’ve experiened.
About the same time (2010, 2011 or so), more and more corporations are providing their employees smartphones, and workers are becoming more and more mobile. The need for mobile security became a major requirement, and a whole slueth of mobile security startup came into the scene. So natually the mobile word rose in rankings.
Virtual and Real-Time Regaining Ground
The words virtual and real-time dropped dramatically in rankings for a couple of years (2010, 2011) but have since regained all the lost ground and more. I have no precise reasons on why that’s the case but I have some theories. These theories are probably completely wrong, and if you have better explanations I would love to hear from you.
- Virtual lost to cloud during that timeframe as every vendor is trying to position their products for the cloud era. However, virtual infrastructures haven’t gone away and in fact continue to experience strong growth. So in the past couple of years, marketers are covering their basis and starting to message both virtual and cloud.
- The drop in rankings for real-time is potentially due to the peak of compliance use case, which is usually report-based and does not have real-time requirements. Also, I suspect another reason is that SIEM, which real-time is critical, is going out of fashion somewhat due to the high cost of ownership and lack of trust in the tools. However, given the recent rise of threats, natually real-time becomes critical again.
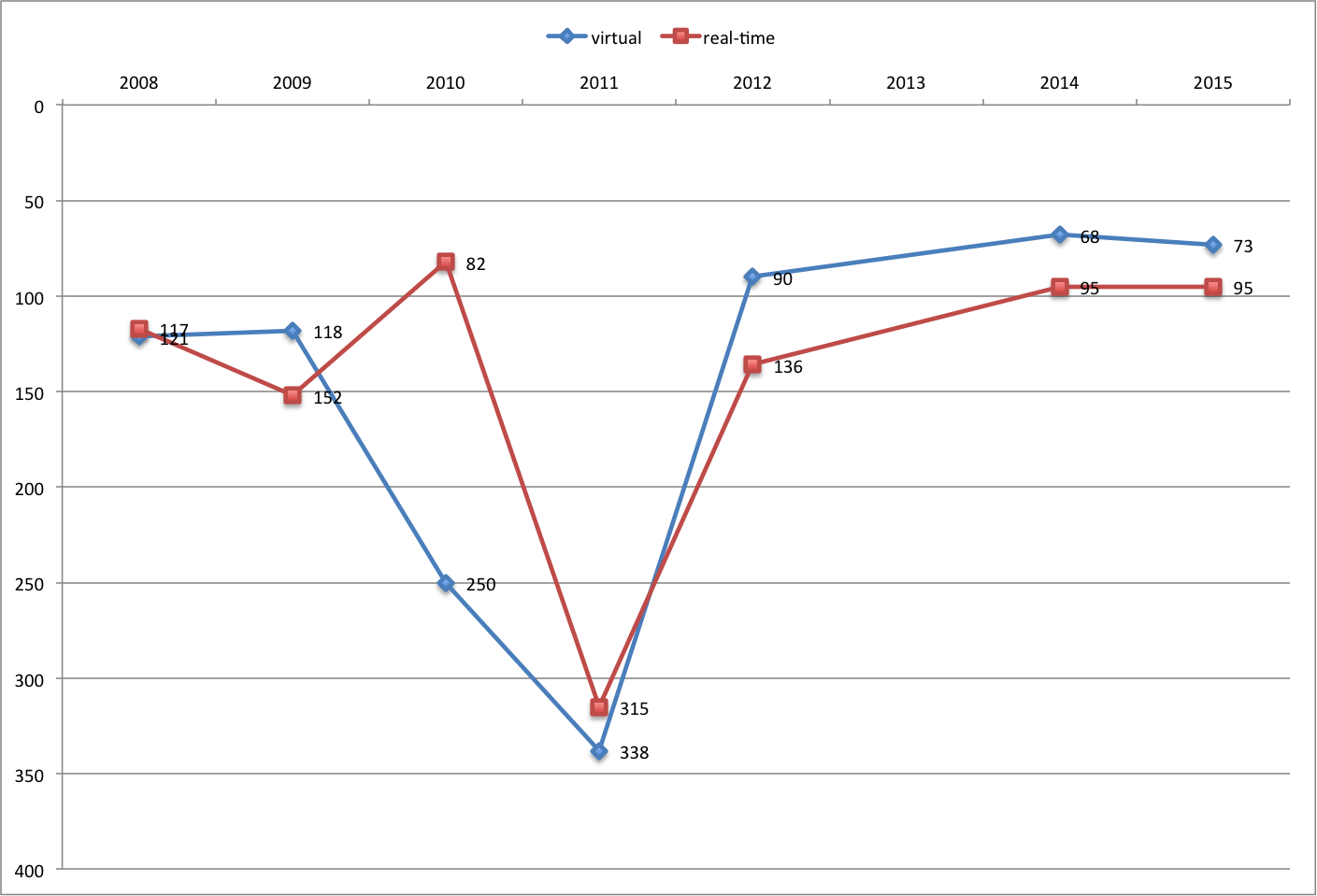
Other Findings
The word cyber gained huge popularity in the past 3 years, likely due to the U.S. government’s focus on cyber security. The word malware has been fairly consistently at the top 100 words since 2010.
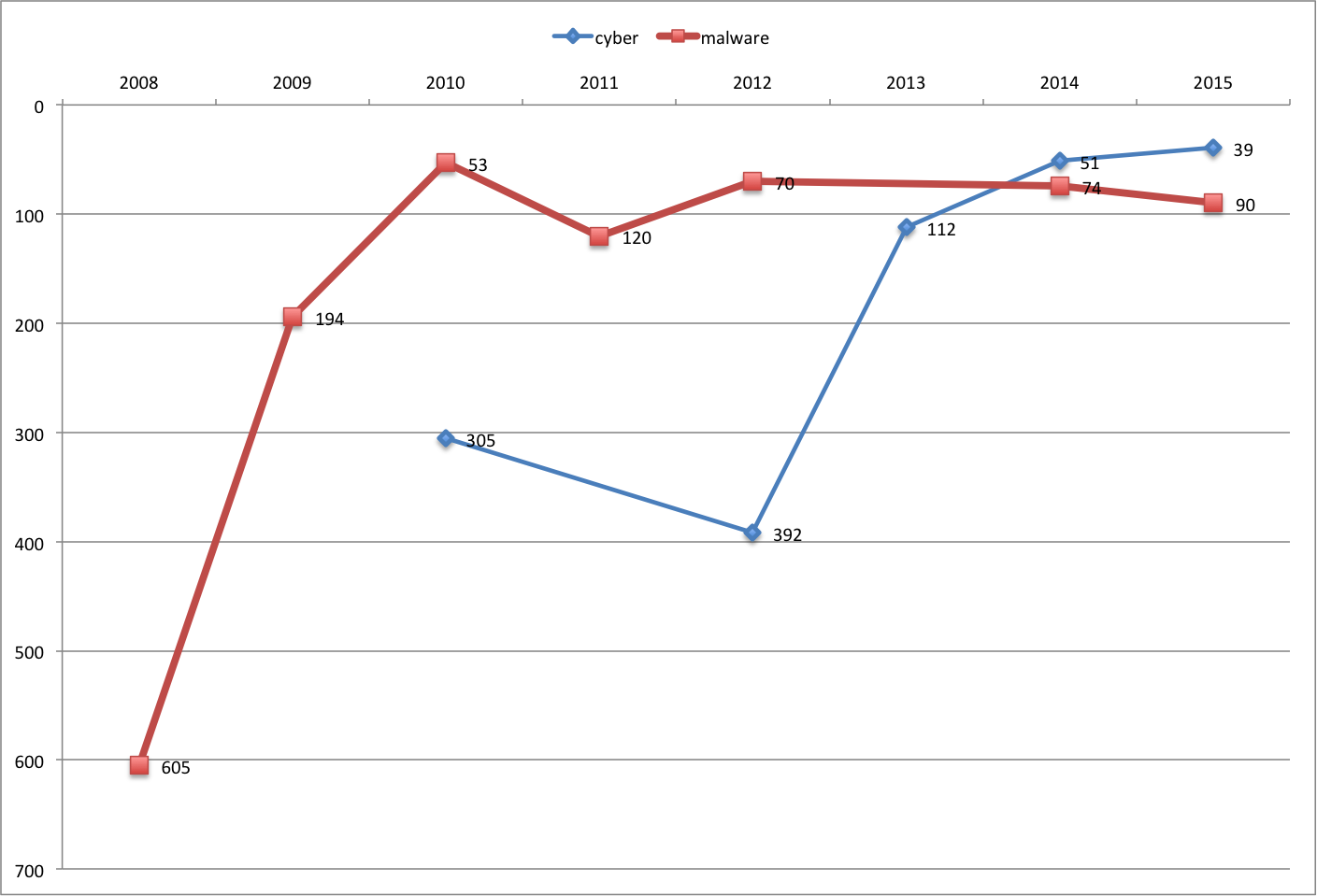
The words product and service switched places in 2013, likely due to the increase in number of security software-as-a-service plays.

Credits
- The word clouds and word rankings are generated using Word Cloud.
- The actual vendor descriptions are gathered from the RSA web site as well as press releases from Business Wire and others.
- Charts are generated using Excel, which continues to be one of the best friends for data analysts (not that I consider myself one).
Papers I Read: 2015 Week 8 22 Feb 2015 6:57 PM (10 years ago)
Random Ramblings
Another week, another report of hacks. This time, The Great Bank Robbery, where up to 100 financial institutions have been hit.Total financial losses could be as a high as $1bn. You can download the full report and learn all about it.
Sony spent $15M to clean up and remediate their hack. I wonder how much these banks are going to spend on tracing the footsteps of their intruders and trying to figure out exactly where they have gone, what they have done and what they have taken.
I didn’t make much progress this week on either sequence or surgemq because of busy work schedule and my son getting sick AGAIN!! But I did merge the few surgemq pull requests that the community has graciously contributed. One of them actually got it tested on Raspberry! That’s pretty cool.
I also did manage to finish up the experimental json scanner that I’ve been working on for the past couple of weeks. I will write more about it in the next sequence article.
Actually I am starting to feel a bit overwhelmed by having both projects. Both of them are very interesting and I can see both move forward in very positive ways. Lots of ideas in my head but not enough time to do them. Now that I am getting feature requests, issues and pull requests, I feel even worse because I haven’t spent enough time on them. <sigh>
Papers I Read
Memory is rapidly becoming a precious resource in many data processing environments. This paper introduces a new data structure called a Compressed Buffer Tree (CBT). Using a combination of buffering, compression, and lazy aggregation, CBTs can improve the memoryefficiency of the GroupBy-Aggregate abstraction which forms the basis of many data processing models like MapReduce and databases. We evaluate CBTs in the context of MapReduce aggregation, and show that CBTs can provide significant advantages over existing hashbased aggregation techniques: up to 2× less memory and 1.5× the throughput, at the cost of 2.5× CPU.
Stream processing has become a key means for gaining rapid insights from webserver-captured data. Challenges include how to scale to numerous, concurrently running streaming jobs, to coordinate across those jobs to share insights, to make online changes to job functions to adapt to new requirements or data characteristics, and for each job, to efficiently operate over different time windows. The ELF stream processing system addresses these new challenges. Implemented over a set of agents enriching the web tier of datacenter systems, ELF obtains scalability by using a decentralized “many masters” architecture where for each job, live data is extracted directly from webservers, and placed into memory-efficient compressed buffer trees (CBTs) for local parsing and temporary storage, followed by subsequent aggregation using shared reducer trees (SRTs) mapped to sets of worker processes. Job masters at the roots of SRTs can dynamically customize worker actions, obtain aggregated results for end user delivery and/or coordinate with other jobs.
Not just a paper, it’s a whole book w/ 800+ pages.
The purpose of this book is to help you program shared-memory parallel machines without risking your sanity.1 We hope that this book’s design principles will help you avoid at least some parallel-programming pitfalls. That said, you should think of this book as a foundation on which to build, rather than as a completed cathedral. Your mission, if you choose to accept, is to help make further progress in the exciting field of parallel programming—progress that will in time render this book obsolete. Parallel programming is not as hard as some say, and we hope that this book makes your parallel-programming projects easier and more fun.
Papers I Read: 2015 Week 7 15 Feb 2015 6:57 PM (10 years ago)
Random Ramblings
Well, another week, another big data breach. This time is Anthem, one of the nation’s largest health insurers. Ok, maybe it was last week that it happend. But this week they revealed that hackers had access … going back as far as 2004. WSJ blamed Anthem for not encrypting the data. Though I have to agree with Rich Mogull over at Securosis that “even if Anthem had encrypted, it probably wouldn’t have helped”.
I feel bad for saying this but there’s one positive side effect from all these data breaches. Security is now officially a boardroom topic. Anthem’s CEO, Joseph Swedish, is now under the gun because top level executives are no longer immune to major security breaches that affect the company’s top line. Just ask Target’s CEO Gregg Steinhafel, or Sony’s Co-Chairwoman Amy Pascal.
Brian Krebs wrote a detailed piece analyzing the various pieces of information available relating to the Anthem hack. Quite an interesting read.
One chart in the artile that Brian referred to is the time difference between the “time to compromise” and the “time to discovery”, taken from Verizon’s 2014 Data Breach Investigations Report. As Brian summaries, “TL;DR: That gap is not improving, but instead is widening.”
What this really says is that, you will get hacked. So how do you shorten the time between getting hacked, and finding out that you are hacked so you can quickly remediate the problem before worse things happen?
With all these data breaches as backdrop, this week we also saw “President Barack Obama signed an executive order on Friday designed to spur businesses and the Federal Government to share with each other information related to cybersecurity, hacking and data breaches for the purpose of safeguarding U.S. infrastructure, economics and citizens from cyber attacks.” (Gigaom)
In general I don’t really think government mandates like this will work. The industry has to feel the pain enough that they are willing to participate, otherwise it’s just a waste of paper and ink. Facebook seems to be taking a lead in security information sharing and launched their ThreatExchange security framework this week. along with Pinterest, Tumblr, Twitter, and Yahoo. Good for them! I hope this is not a temporary PR thing, and that they keep funding and supporting the framework.
Papers I Read
Another great resource of computer science papers is Adrian Coyler’s the morning paper. He selects and summarizes “an interesting/influential/important paper from the world of CS every weekday morning”.
I read this paper when I was trying to figure out how to make the FSAs smaller for the Effective TLD matcher I created. The FSM I generated is 212,294 lines long. That’s just absolutely crazy. This paper seems to present an interesting way of compressing them.
I am not exactly sure if PublicSuffix uses a similar representation but it basically represents a FSA as an array of bytes, and then walk the bytes like a binary search tree. It’s interesting for sure.
This paper is a follow-up to Jan Daciuk’s experiments on space-efficient finite state automata representation that can be used directly for traversals in main memory [4]. We investigate several techniques of reducing the memory footprint of minimal automata, mainly exploiting the fact that transition labels and transition pointer offset values are not evenly distributed and so are suitable for compression. We achieve a size gain of around 20–30% compared to the original representation given in [4]. This result is comparable to the state-of-the-art dictionary compression techniques like the LZ-trie [12] method, but remains memory and CPU efficient during construction.
This work presents integrated model for active security response model. The proposed model introduces Active Response Mechanism (ARM) for tracing anonymous attacks in the network back to their source. This work is motivated by the increased frequency and sophistication of denial-of-service attacks and by the difficulty in tracing packets with incorrect, or “spoofed”, source addresses. This paper presents within the proposed model two tracing approaches based on: • Sleepy Watermark Tracing (SWT) for unauthorized access attacks. • Probabilistic Packet Marking (PPM) in the network for Denial of Service (DoS) and Distributed Denial of Service (DDoS) attacks.
Here we introduce the design of Dapper, Google’s production distributed systems tracing infrastructure, and describe how our design goals of low overhead, application-level transparency, and ubiquitous deployment on a very large scale system were met. Dapper shares conceptual similarities with other tracing systems, particularly Magpie [3] and X-Trace [12], but certain design choices were made that have been key to its success in our environment, such as the use of sampling and restricting the instrumentation to a rather small number of common libraries.
Not a paper, but a good write up nonetheless.
Some people call it stream processing. Others call it Event Sourcing or CQRS. Some even call it Complex Event Processing. Sometimes, such self-important buzzwords are just smoke and mirrors, invented by companies who want to sell you stuff. But sometimes, they contain a kernel of wisdom which can really help us design better systems. In this talk, we will go in search of the wisdom behind the buzzwords. We will discuss how event streams can help make your application more scalable, more reliable and more maintainable.
Sequence: Optimizing Go For the High Performance Log Scanner 13 Feb 2015 12:03 AM (10 years ago)
Information here maybe outdated. Please visit http://sequencer.io for latest.
This is part 3 of the sequence series.
- Part 1 is about the high performance parser that can parse 100,000-200,000 MPs.
- Part 2 is about automating the process of reducing 100 of 1000’s of log messages down to dozens of unique patterns.
- Part 3 is about optimizing Go to achieve very high performance (200,000 - 500,000 MPS depending on message size and core count) for scanning and tokenizing log messages
I would love to learn more about the state-of-the-art approaches that log vendors are using. These attempts are about scratching my own itch and trying to realize ideas I’ve had in my mind. Given some of these ideas are 5 to 10 years old, they may already be outdated. Personally I just haven’t heard of any groundbreaking approaches.
In any case, if you know of some of the more innovative ways people are approaching these problems, please please please comment below as I would love to hear from you.
tl;dr
- The
sequencescanner is designed to tokenize free-form log messages.- It can scan between 200K to 500K log messages per second depending on message size and core count.
- It recognizes time stamps, hex strings, IP (v4, v6) addresses, URLs, MAC addresses, integers and floating point numbers.
- The design is based mostly on finite-state machines.
- The performance was achieved by the following techniques:
- Go Through the String Once and Only Once
- Avoid Indexing into the String
- Reduce Heap Allocation
- Reduce Data Copying
- Mind the Data Struture
- Avoid Interfaces If Possible
- Find Ways to Short Circuit Checks
Background
In computer science, lexical analysis is the process of converting a sequence of characters into a sequence of tokens, i.e. meaningful character strings. A program or function that performs lexical analysis is called a lexical analyzer, lexer, tokenizer, or scanner. - Wikipedia
One of the most critical functions in the sequence parser is the message tokenization. At a very high level, message tokenization means taking a single log message and breaking it into a list of tokens.
Functional Requirements
The challenge is knowing where the token break points are. Most log messages are free-form text, which means there’s no common structure to them.
As an example, the following log message can be tokenized into the sequence of tokens below. As you can see, one cannot depend on white spaces to tokenize, as the timestamp would be broken into 3 parts; nor can one use punctuations like “;” or “:“, as they would break the log mesage into useless parts.
jan 14 10:15:56 testserver sudo: gonner : tty=pts/3 ; pwd=/home/gonner ; user=root ; command=/bin/su - ustream
# 0: { Field="%funknown%", Type="%ts%", Value="jan 14 10:15:56" }
# 1: { Field="%funknown%", Type="%literal%", Value="testserver" }
# 2: { Field="%funknown%", Type="%literal%", Value="sudo" }
# 3: { Field="%funknown%", Type="%literal%", Value=":" }
# 4: { Field="%funknown%", Type="%literal%", Value="gonner" }
# 5: { Field="%funknown%", Type="%literal%", Value=":" }
# 6: { Field="%funknown%", Type="%literal%", Value="tty" }
# 7: { Field="%funknown%", Type="%literal%", Value="=" }
# 8: { Field="%funknown%", Type="%string%", Value="pts/3" }
# 9: { Field="%funknown%", Type="%literal%", Value=";" }
# 10: { Field="%funknown%", Type="%literal%", Value="pwd" }
# 11: { Field="%funknown%", Type="%literal%", Value="=" }
# 12: { Field="%funknown%", Type="%string%", Value="/home/gonner" }
# 13: { Field="%funknown%", Type="%literal%", Value=";" }
# 14: { Field="%funknown%", Type="%literal%", Value="user" }
# 15: { Field="%funknown%", Type="%literal%", Value="=" }
# 16: { Field="%funknown%", Type="%string%", Value="root" }
# 17: { Field="%funknown%", Type="%literal%", Value=";" }
# 18: { Field="%funknown%", Type="%literal%", Value="command" }
# 19: { Field="%funknown%", Type="%literal%", Value="=" }
# 20: { Field="%funknown%", Type="%string%", Value="/bin/su" }
# 21: { Field="%funknown%", Type="%literal%", Value="-" }
# 22: { Field="%funknown%", Type="%literal%", Value="ustream" }
So a log message scanner or tokenizer (we will use these terms interchangeably) must understand common components such as timestamp, URL, hex strings, IP addresses (v4 or v6), and mac addresses, so it can break the messages into meaningful components.
Performance Requirements
From a performance requirements perspective, I really didn’t start out with any expectations. However, after achieving 100-200K MPS for parsing (not just tokenizing), I have a strong desire to keep the performance at that level. So the more I can optimize the scanner to tokenize faster, the more head room I have for parsing.
One may ask, who can POSSIBLY use such performance? Many organizations that I know are generating between 50-100M messages per second (MPS), that’s only 1,200 MPS. Some larger organizations I know are generating 60GB of Bluecoat logs per day, 8 years ago!! That’s a good 3,000 MPS assuming an average of 250 bytes per message. Even if log rate grows at 15%, that’s still only 10K MPS today.
To run through an example, at EMC, 1.4 billion log messages are generated daily on average, at a rate of one terabyte a day. That’s 16,200 messages per second, and about 714 bytes per message. (Btw, what system can possibly generate messages that are 714 bytes long? That’s crazy and completely inefficient!) These EMC numbers are from 2013, so they have likely increased by now.
The sequence parser, with a single CPU core, can process about 270,000 MPS for messages averaging 98 bytes. Assuming the performance is linear compare to the message size (which is pretty close to the truth), we can process 37,000 MPS for messages averaging 714 bytes. That’s just enough to parse the 16,2000 MPS, with a little head room to do other types of analysis or future growth.
Obviously one can throw more hardware at solving the scale problem, but then again, why do that if you don’t need to. Just because you have the hardware doesn’t mean you should waste the money! Besides, there are much more interesting analytics problems your hardware can be used for than just tokenizing a message.
In any case, I want to squeeze every oz of performance out of the scanner so I can have more time in the back to parse and analyze. So let’s set a goal of keeping at least 200,000 MPS for 100 bytes per message (BPM).
Yes, go ahead and tell me I shouldn’t worry about micro-optimization, because this post is all about that. :)
Sequence Scanner
In the sequence package, we implemented a general log message scanner, called GeneralScanner. GeneralScanner is a sequential lexical analyzer that breaks a log message into a sequence of tokens. It is sequential because it goes through log message sequentially tokentizing each part of the message, without the use of regular expressions. The scanner currently recognizes time stamps, hex strings, IP (v4, v6) addresses, URLs, MAC addresses, integers and floating point numbers.
This implementation was able to achieve both the functional and performance requirements. The following performance benchmarks are run on a single 4-core (2.8Ghz i7) MacBook Pro, although the tests were only using 1 or 2 cores. The first file is a bunch of sshd logs, averaging 98 bytes per message. The second is a Cisco ASA log file, averaging 180 bytes per message. Last is a mix of ASA, sshd and sudo logs, averaging 136 bytes per message.
$ ./sequence bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.78 secs, ~ 272869.35 msgs/sec
$ ./sequence bench scan -i ../../data/allasa.log
Scanned 234815 messages in 1.43 secs, ~ 163827.61 msgs/sec
$ ./sequence bench scan -i ../../data/allasassh.log
Scanned 447745 messages in 2.27 secs, ~ 197258.42 msgs/sec
Performance can be improved by adding more cores:
$ GOMAXPROCS=2 ./sequence bench scan -i ../../data/sshd.all -w 2
Scanned 212897 messages in 0.43 secs, ~ 496961.52 msgs/sec
$ GOMAXPROCS=2 ./sequenceo bench scan -i ../../data/allasa.log -w 2
Scanned 234815 messages in 0.80 secs, ~ 292015.98 msgs/sec
$ GOMAXPROCS=2 ./sequence bench scan -i ../../data/allasassh.log -w 2
Scanned 447745 messages in 1.20 secs, ~ 373170.45 msgs/sec
Concepts
To understand the scanner, you have to understand the following concepts that are part of the package.
A Token is a piece of information extracted from the original log message. It is a struct that contains fields for TokenType, FieldType, and Value.
A TokenType indicates whether the token is a literal string (one that does not change), a variable string (one that could have different values), an IPv4 or IPv6 address, a MAC address, an integer, a floating point number, or a timestamp.
A FieldType indicates the semantic meaning of the token. For example, a token could be a source IP address (%srcipv4%), or a user (%srcuser% or %dstuser%), an action (%action%) or a status (%status%).
A Sequence is a list of Tokens. It is the key data structure consumed and returned by the Scanner, Analyzer, and the Parser.
Basically, the scanner takes a log message string, tokenizes it and returns a Sequence with the recognized TokenType marked. This Sequence is then fed into the analyzer or parser, and the analyzer or parser in turn returns another Sequence that has the recognized FieldType marked.
Design
Tokenizers or scanners are usually implemented using finite-state machines. Each FSM (or FSA, finite state automata) understands a specific sequences of characters that make up a type of token.
In the sequence scanner, there are three FSMs: Time, HexString and General.
- The Time FSM understands a list of time formats. This list of time formats are commonly seen in log messages. It is also fairly easy to add to this list if needed.
- The HexString FSM is designed to understand IPv6 addresses (dead:beef:1234:5678:223:32ff:feb1:2e50 or f0f0:f::1), MAC addresses (00:04:c1:8b:d8:82), fingerprints or signatures (de:ad:be:ef:74:a6:bb:45:45:52:71:de:b2:12:34:56).
- The General FSM that recognizes URLs, IPv4 addresses, and any literal or strings.
Each character in the log string are run through all three FSMs.
- If a time format is matched, that’s what it will be returned.
- Next if a hex string is matched, it is also returned.
- We mark anything with 5 colon characters and no successive colons like “::” to be a MAC address.
- Anything that has 7 colons and no successive colons are marked as IPv6 address.
- Anything that has less than 7 colons but has only 1 set of successive colons like “::” are marked as IPv6 address.
- Everything else is just a literal.
- Finally if neither of the above matched, we return what the general FSM has matched.
- The general FSM recognizes these quote characters: “, ‘ and <. If these characters are encountered, then it will consider anything between the quotes to be a single token.
- Anything that starts with http:// or https:// are considered URLs.
- Anything that matches 4 integer octets are considered IP addresses.
- Anything that matches two integers with a dot in between are considered floats.
- Anything that matches just numbers are considered integers.
- Everything else are literals.
Performance
To achieve the performance requirements, the following rules and optimizations are followed. Some of these are Go specific, and some are general recommendations.
1. Go Through the String Once and Only Once
This is a hard requirement, otherwise we can’t call this project a sequential parser. :)
This is probably a pretty obvious technique. The more times you loop through loop through a string, the lower the performance. If you used regular expressions to parse logs, you will likely go through parts of the log message multiple times due to back tracking or look forward, etc.
I took great pain to ensure that I don’t need to look forward or look backward in the log string to determine the current token type, and I think the effort paid off.
In reality though, while I am only looping through the log string once, and only once, I do run each character through three different FSMs. However, it is still much less expensive than looping through three times, each time checking a single FSM. However, the more FSMs I run the characters through, the slower it gets.
This was apparently when I updated the scanner to support IPv6 and hex strings. I tried a couple of different approaches. First, I added an IPv6 specific FSM. So in addition to the original time, mac and general FSMs, there are now 4. That dropped performance by like 15%!!! That’s just unacceptable.
The second approach, which is the one I checked in, combines the MAC, IPv6 and general hex strings into a single FSM. That helped somewhat. I was able to regain about 5% of the performance hit. However, because I can no longer short circuit the MAC address check (by string length and colon positions), I was still experiencing a 8-10% hit.
What this means is that for most tokens, instead of checking just 2 FSMs because I can short circuit the MAC check pretty early, I have to now check all 3 FSMs.
So the more FSMs, the more comlicated the FSMs, the more performance hits there will be.
2. Avoid Indexing into the String
This is really a Go-specific recommentation. Each time you index into a slice or string, Go will perform bounds checking for you, which means there’s extra operations it’s doing, and also means lower performance. As an example, here are results from two benchmark runs. The first is with bounds checking enabled, which is default Go behavior. The second disables bounds checking.
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.79 secs, ~ 268673.91 msgs/sec
$ go run -gcflags=-B ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.77 secs, ~ 277479.58 msgs/sec
The performance difference is approximately 3.5%! However, while it’s fun to see the difference, I would never recommend disable bounds checking in production. So the next best thing is to remove as many operations that index into a string or slice as possible. Specifically:
- Use “range” in the loops, e.g.
for i, r := range strinstead offor i := 0; i < len(str); i++ { if str[i] == ... } - If you are checking a specific character in the string/slice multiple times, assign it to a variable and use the variable instead. This will avoid indexing into the slice/string multiple times.
- If there are multiple conditions in an
ifstatement, try to move (or add) the non-indexing checks to the front of the statement. This sometimes will help short circuit the checks and avoid the slice-indexing checks.
One might question if this is worth optimizing, but like I said, I am trying to squeeze every oz of performance so 3.5% is still good for me. Unfornately I do know I won’t get 3.5% since I can’t remove every operation that index into slice/string.
3. Reduce Heap Allocation
This is true for all languages (where you can have some control of stack vs heap allocation), and it’s even more true in Go. Mainly in Go, if you allocate a new slice, Go will “zero” out the allocated memory. This is great from a safety perspective, but it does add to the overhead.
As an example, in the scanner I originally allocated a new Sequence (slice of Token) for every new message. However, when i changed it to re-use the existing slice, the performance increased by over 10%!
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.87 secs, ~ 246027.12 msgs/sec
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.77 secs, ~ 275038.83 msgs/sec
The best thing to do is to run Go’s builtin CPU profiler, and look at the numbers for Go internal functions such as runtime.makeslice, runtime.markscan, and runtime.memclr. Large percentages and numbers for these internal functions are dead giveaway that you are probably allocating too much stuff on the heap.
I religiously go through the SVGs generated from the Go profiler to help me identify hot spots where I can optimize.
Here’s also a couple of tips I picked up from the go-nuts mailing list:
- Maps are bad–even if they’re storing integers or other non-pointer structs. The implementation appears to have lots of pointers inside which must be evaluated and followed during mark/sweep GC. Using structures with pointers magnifies the expense.
- Slices are surprisingly bad (including strings and substrings of existing strings). A slice is a pointer to the backing array with a length and capacity. It would appear that the internal pointer that causes the trouble because GC wants to inspect it.
4. Reduce Data Copying
Data copying is expensive. It means the run time has to allocate new space and copy the data over. It’s even more expensive when you can’t have do memcpy of a slice in Go like you can in C. Again, direct memory copying is not Go’s design goal. It is also much safer if you can prevent users from playing with memory directly too much. However, it is still a good idea to avoid any copying of data, whether it’s string or slice.
As much as I can, I try to do in place processing of the data. Every Sequence is worked on locally and I try not to copy Sequence or string unless I absolutely have to.
Unfortunately I don’t have any comparison numbers for this one, because I learned from previous projects that I should avoid copying as much as possible.
5. Mind the Data Struture
If there’s one thing I learned over the past year, is to use the right data structure for the right job. I’ve written about other data structures such as ring buffer, bloom filters, and skiplist before.
However, finite-state automata or machine is my latest love and I’ve been using it at various projects such as my porter2 and effective TLD. Ok, technical FSM itself is not a data structure and can be implemented in different ways. In the sequence project, I used both a tree representation as well as a bunch of switch-case statements. For the porter2 FSMs, I used switch-case to implement them.
Interestingly, swtich-case doesn’t always win. I tested the time FSM using both tree and switch-case implementations, and the tree actually won out. (Below, 1 is tree, 2 is switch-case.) So guess which one is checked in?
BenchmarkTimeStep1 2000000 696 ns/op
BenchmarkTimeStep2 2000000 772 ns/op
Writing this actually reminds me that in the parser, I am currently using a tree to parse the sequences. While parsing, there could be multiple paths that the sequence will match. Currently I walk all the matched paths fully, before choosing one that has the highest score. What I should do is to do a weighted walk, and always walk the highest score nodes first. If at the end I get a perfect score, I can just return that path and not have to walk the other paths. (Note to self, more parser optimization to do).
6. Avoid Interfaces If Possible
This is probably not a great advice to give to Go developers. Interface is probably one of the best Go features and everyone should learn to use it. However, if you want high performane, avoid interfaces as it provides additional layers of indirection. I don’t have performance numbers for the sequence project since I tried to avoid interfaces in high performance areas from the start. However, previous in the ring buffer project, the version that uses interface is 140% slower than the version that didn’t.
I don’t have the direct link but someone on the go-nuts mailing list also said:
If you really want high performance, I would suggest avoiding interfaces and, in general, function calls like the plague, since they are quite expensive in Go (compared to C). We have implemented basically the same for our internal web framework (to be released some day) and we’re almost 4x faster than encoding/json without doing too much optimization. I’m sure we could make this even faster.
7. Find Ways to Short Circuit Checks
Find ways to quickly eliminate the need to run a section of the code has been tremendously helpful to improve performance. For example, here are a couple of place where I tried to do that.
In this first example, I simply added l == 1 before the actual equality check of the string values. The first output is before the add, the second is after. The difference is about 2% performance increase.
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.78 secs, ~ 272303.79 msgs/sec
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.76 secs, ~ 278433.34 msgs/sec
In the second example, I added a quick check to make sure the remaining string is at least as long as the shortest time format. If there’s not enough characters, then don’t run the time FSM. The performance difference is about 2.5%.
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.78 secs, ~ 272059.04 msgs/sec
$ go run ./sequence.go bench scan -i ../../data/sshd.all
Scanned 212897 messages in 0.76 secs, ~ 279388.47 msgs/sec
So by simply adding a couple of checks, I’ve increased perfromance by close to 5%.
Conclusion
At this point I think I have squeezed every bit of performance out of the scanner, to the extend of my knowledge. It’s performing relatively well and it’s given the parser plenty of head room to do other things. I hope some of these lessons are helpful to whatever you are doing.
Feel free to take a look at the sequence project and try it out if you. If you have any issues/comments, please don’t hestiate to open a github issue.
Sequence: Automated Analyzer for Reducing 100,000's of Log Messages to 10's of Patterns 10 Feb 2015 5:40 AM (10 years ago)
Information here maybe outdated. Please visit http://sequencer.io for latest.
This is part 2 of the sequence series.
- Part 1 is about the high performance parser that can parse 100,000-200,000 MPs.
- Part 2 is about automating the process of reducing 100 of 1000’s of log messages down to dozens of unique patterns.
- Part 3 is about optimizing Go to achieve very high performance (200,000 - 500,000 MPS depending on message size) for scanning and tokenizing log messages
Background
This post really takes me down the memory lane. Back in 2005, while I was at LogLogic, we envisioned an automated approach to tagging, or labeling, log messages. More specifically, we wanted to automatically tag specific components within the log messages with their semantic label, such as a source IP address, or a target user.
At the time, much like it is still today, the message parsing process is performed manually. This means someone has to manually look at the object and decided that the object should be labeled “user” or “targetUser.” An analyst has to go through the log data, create a regular expression that extracts the useful strings out, and then finally assigning these to a specific label. This is extremely time consuming and error-prone.
At that time, the vision was to provide an automated approach to universally parse and analyze ANY log data. The key phrase being “automated approach.” This means the users should only need to provide minimum guidance to the system, if any, for the platforms to be able to analyze the log data. LogLogic never did much with this, unfortunately.
However, the tagging concept was later on adopted by (and I know how this got into CEE :) the Common Event Expression, or CEE effort by Mitre. This idea of tags also inspired liblognorm to develop their libee library and tagging system. Rsyslog’s mmnormalize module is based on liblognorm.
And then there’s Fedora’s Project Lumberjack, which “is an open-source project to update and enhance the event log architecture” and “aims to improve the creation and standardize the content of event logs by implementing the concepts and specifications proposed by the Common Event Expression (CEE).”
Then finally logstash has their grok filter that basically does similar extraction of unstructured data into a structured and queryable format. However, it seems like there might be some performance bottlenecks.
However, none of these efforts attempted to solve the automated tagging/labeling problem. They mostly just try to provide a parser for log messages.
Also, it looks like many of these efforts have all been abandoned or put in hibernation, and haven’t been updated since 2012 or 2013. liblognrom did put out a couple of updates in the past couple of years. Logstash’s grok obviously is being maintained and developed with the Elasticsearch backing.
It is understandable, unfortunately. Log parsing is BORING. I mean, who wants to sit there and stare at logs all day and try to come up with regular expressions or other types of parsing rules? LogLogic used to have a team of LogLabs analysts that did that, and I have to say I truly appreciated their effort and patience, because I cannot do that.
The End Result
So instead of writing rules all day long, I decided to create an analyzer that can help us get at least 75% of the way there. The end result is the Analyzer, written in Go, in the sequence project I created. Here are some preliminary results. Below, we analyzed 2 files. The first is a file with over 200,000 sshd messages. The second is a file with a mixture of ASA, sshd, sudo and su log messages. It contains almost 450,000 messages.
By running the analyzer over these logs, the pure sshd log file returned 45 individual patterns, and the second returned 103 unique patterns.
$ go run sequence.go analyze -i ../../data/sshd.all -o sshd.analyze
Analyzed 212897 messages, found 45 unique patterns, 45 are new.
$ go run sequence.go analyze -i ../../data/asasshsudo.log -o asasshsudo.analyze
Analyzed 447745 messages, found 103 unique patterns, 103 are new.
And the output file has entries such as:
%msgtime% %apphost% %appname% [ %sessionid% ] : %status% %method% for %srcuser% from %srcipv4% port %srcport% ssh2
# Jan 15 19:39:26 irc sshd[7778]: Accepted password for jlz from 108.61.8.124 port 57630 ssh2
%msgtime% %appipv4% %appname% : %action% outbound %protocol% connection %sessionid% for %string% : %srcipv4% / %srcport% ( %ipv4% / %integer% ) to %string% : %dstipv4% / %dstport% ( %ipv4% / %integer% )
# 2012-04-05 18:46:18 172.23.0.1 %ASA-6-302013: Built outbound TCP connection 1424575 for outside:10.32.0.100/80 (10.32.0.100/80) to inside:172.23.73.72/2522 (10.32.0.1/54702)
%msgtime% %apphost% %appname% : %string% : tty = %string% ; pwd = %string% ; user = %srcuser% ; command = %command% - %string%
# Jan 15 14:09:11 irc sudo: jlz : TTY=pts/1 ; PWD=/home/jlz ; USER=root ; COMMAND=/bin/su - irc
As you can see, the output is not 100%, but it gets us pretty close. Once the analyst goes through and updates the rules, he/she can re-run the analyzer anytime with any file to determine if there’s new patterns. For example, below, we ran the sshd log file with an existing pattern file, and got 4 new log patterns.
$ go run sequence.go analyze -i ../../data/sshd.all -p ../../patterns/sshd.txt -o sshd.analyze
Analyzed 212897 messages, found 39 unique patterns, 4 are new.
Parser - Quick Review
I wrote about the sequence parser a couple of weeks back. It is a high performance sequential log parser. It sequentially goes through a log message, parses out the meaningful parts, without the use regular expressions. It can achieve high performance parsing of 100,000 - 200,000 messages per second (MPS) without the need to separate parsing rules by log source type. Underneath the hood, the sequence parser basically constructs a tree based on the sequential rules, walks the tree to identify all the possible paths, and returns the path that has the best match (highest weight) for the message.
While the analyzer is about reducing a large corupus of raw log messages down to a small set of unique patterns, the parser is all about matching log messages to an existing set of patters and determining whether a specific pattern has matched. Based on the pattern, it returns a sequence of tokens that basically extracts out the important pieces of information from the logs. The analysts can then take this sequence and perform other types of analysis.
The approach taken by the sequence parser is pretty much the same as liblognorm or other tree-based approaches.
Sequence Analyzer
In the following section I will go through additional details of how the sequence analyzer reduces 100 of 1000’s of raw log messages down to just 10’s of unique patterns, and then determining how to label the individual tokens.
Identifying Unique Patterns
Analyzer builds an analysis tree that represents all the Sequences from messages. It can be used to determine all of the unique patterns for a large body of messages.
It’s based on a single basic concept, that for multiple log messages, if tokens in the same position shares one same parent and one same child, then the tokens in that position is likely variable string, which means it’s something we can extract. For example, take a look at the following two messages:
Jan 12 06:49:42 irc sshd[7034]: Accepted password for root from 218.161.81.238 port 4228 ssh2
Jan 12 14:44:48 jlz sshd[11084]: Accepted publickey for jlz from 76.21.0.16 port 36609 ssh2
The first token of each message is a timestamp, and the 3rd token of each message is the literal “sshd”. For the literals “irc” and “jlz”, they both share a common parent, which is a timestamp. They also both share a common child, which is “sshd”. This means token in between these, the 2nd token in each message, likely represents a variable token in this message type. In this case, “irc” and “jlz” happens to represent the syslog host.
Looking further down the message, the literals “password” and “publickey” also share a common parent, “Accepted”, and a common child, “for”. So that means the token in this position is also a variable token (of type TokenString).
You can find several tokens that share common parent and child in these two messages, which means each of these tokens can be extracted. And finally, we can determine that the single pattern that will match both is:
%time% %string% sshd [ %integer% ] : Accepted %string% for %string% from %ipv4% port %integer% ssh2
If later we add another message to this mix:
Jan 12 06:49:42 irc sshd[7034]: Failed password for root from 218.161.81.238 port 4228 ssh2
The Analyzer will determine that the literals “Accepted” in the 1st message, and “Failed” in the 3rd message share a common parent “:” and a common child “password”, so it will determine that the token in this position is also a variable token. After all three messages are analyzed, the final pattern that will match all three messages is:
%time% %string% sshd [ %integer% ] : %string% %string% for %string% from %ipv4% port %integer% ssh2
By applying this concept, we can effectively identify all the unique patterns in a log file.
Determining the Correct Labels
Now that we have the unique patterns, we will scan the tokens to determine which labels we should apply to them.
System and network logs are mostly free form text. There’s no specific patterns to any of them. So it’s really difficult to determine how to label specific parts of the log message automatically. However, over the years, after looking at so many system and network log messages, some patterns will start to emerge.
There’s no “machine learning” here. This section is all about codifying these human learnings. I’ve created the following 6 rules to help label tokens in the log messages. By no means are these rules perfect. They are at best just guesses on how to label. But hopefully they can get us 75% of the way there and we human can just take it the rest of the way.
0. Parsing Email and Hostname Formats
This is technically not a labeling step. Before we actually start the labeling process, we wanted to first parse out a couple more formats like email and host names. The message tokenizer doesn’t recognize these because they are difficult to parse and will slow down the tokenizer. These specific formats are also not needed by the parser. So because the analyzer doesn’t care about performance as much, we can do this as post-processing step.
To recognize the hostname, we try to match the “effective TLD” using the xparse/etld package. It is an effective TLD matcher that returns the length of the effective domain name for the given string. It uses the data set from https://www.publicsuffix.org/list/effective_tld_names.dat.
1. Recognizing Syslog Headers
First we will try to see if we can regonize the syslog headers. We try to recogize both RFC5424 and RFC3164 syslog headers:
// RFC5424
// - "1 2003-10-11T22:14:15.003Z mymachine.example.com evntslog - ID47 ..."
// - "1 2003-08-24T05:14:15.000003-07:00 192.0.2.1 myproc 8710 - ..."
// - "1 2003-10-11T22:14:15.003Z mymachine.example.com su - ID47 ..."
// RFC3164
// - "Oct 11 22:14:15 mymachine su: ..."
// - "Aug 24 05:34:00 CST 1987 mymachine myproc[10]: ..."
// - "jan 12 06:49:56 irc last message repeated 6 times"
If the sequence pattern matches any of the above sequence, then we assume the first few tokens belong to the syslog header.
2. Marking Key and Value Pairs
The next step we perform is to mark known “keys”. There are two types of keys. First, we identify any token before the “=” as a key. For example, the message fw=TOPSEC priv=6 recorder=kernel type=conn contains 4 keys: fw, priv, recorder and type. These keys should be considered string literals, and should not be extracted. However, they can be used to determine how the value part should be labeled.
The second types of keys are determined by keywords that often appear in front of other tokens, I call these prekeys. For example, we know that the prekey from usually appears in front of any source host or IP address, and the prekey to usually appears in front of any destination host or IP address. Below are some examples of these prekeys.
from = [ "%srchost%", "%srcipv4%" ]
port = [ "%srcport%", "%dstport%" ]
proto = [ "%protocol%" ]
sport = [ "%srcport%" ]
src = [ "%srchost%", "%srcipv4%" ]
to = [ "%dsthost%", "%dstipv4%", "%dstuser%" ]
To help identify these prekeys, I wrote a quick program that goes through many of the logs I have to help identify what keywords appears before IP address, mac addresses, and other non-literal tokens. The result is put into the keymaps.go file. It’s not comprehensive, but it’s also not meant to be. We just need enough hints to help with labeling.
3. Labeling “Values” by Their Keys
Once the keys are labeled, we can label the values based on the mapping described above. For key/value pairs, we try to recognize both key=value or key="value" formats (or other quote characters like ‘ or <).
For the prekeys, we try to find the value token within 2 tokens of the key token. That means sequences such as from 192.168.1.1 and from ip 192.168.1.1 will identify 192.168.1.1 as the %srcipv4% based on the above mapping, but we will miss from ip address 192.168.1.1.
4. Identifying Known Keywords
Within most log messages, there are certain keywords that would indicate what actions were performed, what the state/status of the action was, and what objects the actions were performed on. CEE had a list that it identified, so I copied the list and added some of my own.
action = [
"access",
"alert",
"allocate",
"allow",
.
.
.
]
status = [
"accept",
"error",
"fail",
"failure",
"success"
]
object = [
"account",
"app",
"bios",
"driver",
.
.
.
]
In our labeling process, we basically goes through and identify all the string literals that are NOT marked as keys, and perform a porter2 stemming operation on the literal, then compare to the above list (which is also porter2 stemmed).
If a literal matches one of the above lists, then the corresponding label (action, status, object, srcuser, method, or protocol) is applied.
5. Determining Positions of Specific Types
In this next step, we are basically looking at the position of where some of the token types appear. Specifically, we are looking for %time%, %url%, %mac%, %ipv4%, %host%, and %email% tokens. Assuming the labels have not already been taken with the previous rules, the rules are as follows:
- The first %time% token is labeled as %msgtime%
- The first %url% token is labeled as %object%
- The first %mac% token is labeled as %srcmac% and the second is labeld as %dstmac%
- The first %ipv4% token is labeled as %srcipv4% and the second is labeld as %dstipv4%
- The first %host% token is labeled as %srchost% and the second is labeld as %dsthost%
- The first %email% token is labeled as %srcemail% and the second is labeld as %dstemail%
6. Scanning for ip/port or ip:port Pairs
Finally, after all that, we scan through the sequence again, and identify any numbers that follow an IP address, but separated by either a “/” or “:“. Then we label these numbers as either %srcport% or %dstport% based on how the previous IP address is labeled.
Summary
There are some limitations to the sequence parser and analyzer. For example, currently sequence does not handle multi-line logs. Each log message must appear as a single line. So if there’s multi-line logs, they must be first be converted into a single line. Also, sequence has been only tested with a limited set of system (Linux, AIX, sudo, ssh, su, dhcp, etc etc), network (ASA, PIX, Neoteris, CheckPoint, Juniper Firewall) and infrastructure application (apache, bluecoat, etc) logs.
Documentation is available at godoc: package, command.
There are some pattern files developed for ASA, Sudo and SSH in the patterns directory. The goal is to continue to develop a set of patterns for the various log messages, and along the way add additional features to the parser that can help make it even easier to parse log messages.
If you have a set of logs you would like me to test out, please feel free to open an issue and we can arrange a way for me to download and test your logs.
Stay tuned for more log patterns…
Papers I Read: 2015 Week 6 8 Feb 2015 6:57 PM (10 years ago)
Papers We Love has been making rounds lately and a lot of people are excited about it. I also think it’s kind of cool since I’ve been reading a lot of research papers over the past year or so. I have been killing some trees because of that.
My interests have been mostly around data analytics, but the specific focus areas have changed a few times. I have read papers on data structures (bloom filters, skiplist, bitmap compression, etc), security analytics, consumer behavioral analysis, loyalty analytics, and now back to security analytics. In fact, recently I started reading a few security research papers that I found on covert.io, put together by Jason Trost.
In any case, I thought it might be an interesting idea to share some of the papers I read/scan/skim on weekly basis. This way I can also track what I read over time.
Random Ramblings
This week has been a disaster. I was the last one in the family to catch the cold, but probably lasted the longest. In fact I am still only about 50%. This whole week I have been having headaches, body aches, and haven’t been able to concentrate. My body must be trying to catch up on sleep or something. For a couple days I actually slept for almost 12 hours a night!
I’ve been meaning to work on sequence and finish updating the analyzer, but really had a hard time concentrating. Any non-working hours are basically spent in bed if I could.
So this is probably the worst week to start the “Papers I Read” series since I only technically read 1 paper. But I am going to cheat a little, and list the papers I read over the past couple of weeks, pretty much all in my spare time.
This week we also saw Sony’s accouncement that last year’s hack cost them $15 million to investigate and remediate. It’s pretty crazy if you think about it.
Let’s assume that they hired a bunch of high-priced consultants, say $250/hour, to help comb through the logs and clean the systems. And let’s say 2⁄3 of the $15m is spent on these consultants. That’s $10m / $250 = 40,000 hours.
Let’s say these consultants worked full time, non-stop, no weekends, no breaks, for 2 months since the announcement on Nov 24, 2014, that would be a team of 56 people (40,000 hours / 60 days / 12 hours/day = 56) working 12 hour days!
I’ll tell ya, these security guys are raking it in. They make money upfront by selling products/services to protect the company, then they make money in the back by selling forensic services to clean up after the hack.
[Disclaimer: any mistake in my calculations/assumptions I blame on my drugged brain cells.]
Papers I Read
We present a novel system, Beehive, that attacks the problem of automatically mining and extracting knowledge from the dirty log data produced by a wide variety of security products in a large enterprise. We improve on signature-based approaches to detecting security incidents and instead identify suspicious host behaviors that Beehive reports as potential security incidents.
This chapter provides an overview of the Minnesota Intrusion Detection System (MINDS), which uses a suite of data mining based algorithms to address different aspects of cyber security. The various components of MINDS such as the scan detector, anomaly detector and the profiling module detect different types of attacks and intrusions on a computer network.
Key operational networking tasks, such as troubleshooting and defending against attacks, greatly benefit from attaining views of network activity that are unified across space and time. This means that data from heterogeneous devices and systems is treated in a uniformfashion, and that analyzing past activity and detecting future instances follow the same procedures. Based on previous ideas that formulated principles for comprehensive network visibility [AKP+08], we present the design and architecture of Visibility Across Space and Time (VAST), an intelligent database that serves as a single vantage point into the network. The system is based on a generic event model to handle network data from disparate sources and provides a query architecture that allows operators or remote applications to extract events matching a given condition. We implemented a proof-of-principle prototype that can archive and index events from a wide range of sources. Moreover, we conducted a preliminary performance evaluation to verify that our implementation works efficient and as expected.
Managed security service providers (MSSPs) must manage and monitor thousands of intrusion detection sensors. The sensors often vary by manufacturer and software version, making the problem of creating generalized tools to separate true attacks from false positives particularly difficult. Often times it is useful from an operations perspective to know if a particular sensor is acting out of character. We propose a solution to this problem using anomaly detection techniques over the set of alarms produced by the sensors. Similar to the manner in which an anomaly based sensor detects deviations from normal user or system behavior, we establish the baseline behavior of a sensor and detect deviations from this baseline. We show that departures from this profile by a sensor have a high probability of being artifacts of genuine attacks. We evaluate a set of time-based Markovian heuristics against a simple compression algorithm and show that we are able to detect the existence of all attacks which were manually identified by security personnel, drastically reduce the number of false positives, and identify attacks which were overlooked during manual evaluation.
Detection methods based on n-gram models have been widely studied for the identification of attacks and malicious software. These methods usually build on one of two learning schemes: anomaly detection, where a model of normality is constructed from n-grams, or classification, where a discrimination between benign and malicious n-grams is learned. Although successful in many security domains, previous work falls short of explaining why a particular scheme is used and more importantly what renders one favorable over the other for a given type of data. In this paper we provide a close look on n-gram models for intrusion detection. We specifically study anomaly detection and classification using n-grams and develop criteria for data being used in one or the other scheme. Furthermore, we apply these criteria in the scope of web intrusion detection and empirically validate their effectiveness with different learning-based detection methods for client-side and service-side attacks.
Ok, this is a blog post, not a research paper, but it’s somewhat interesting nonetheless.
This article describes how we met that challenge using an “old school”, brute-force approach, by eliminating layers and avoiding complex data structures. There are lessons here that you can apply to your own engineering challenges.
Sequence: A High Performance Sequential Semantic Log Parser at 175,000 MPS 1 Feb 2015 9:40 AM (10 years ago)
Information here maybe outdated. Please visit http://sequencer.io for latest.
This is part 1 of the sequence series.
- Part 1 is about the high performance parser that can parse 100,000-200,000 MPs.
- Part 2 is about automating the process of reducing 100 of 1000’s of log messages down to dozens of unique patterns.
- Part 3 is about optimizing Go to achieve very high performance (200,000 - 500,000 MPS depending on message size) for scanning and tokenizing log messages
Background
sequence is a high performance sequential log parser. It sequentially goes through a log message, parses out the meaningful parts, without the use regular expressions. It can achieve high performance parsing of 100,000 - 200,000 messages per second (MPS) without the need to separate parsing rules by log source type.
sequence is currently under active development and should be considered unstable until further notice.
If you have a set of logs you would like me to test out, please feel free to open an issue and we can arrange a way for me to download and test your logs.
Motivation
Log messages are notoriusly difficult to parse because they all have different formats. Industries (see Splunk, ArcSight, Tibco LogLogic, Sumo Logic, Logentries, Loggly, LogRhythm, etc etc etc) have been built to solve the problems of parsing, understanding and analyzing log messages.
Let’s say you have a bunch of log files you like to parse. The first problem you will typically run into is you have no way of telling how many DIFFERENT types of messages there are, so you have no idea how much work there will be to develop rules to parse all the messages. Not only that, you have hundreds of thousands, if not millions of messages, in front of you, and you have no idea what messages are worth parsing, and what’s not.
The typical workflow is develop a set of regular expressions and keeps testing against the logs until some magical moment where all the logs you want parsed are parsed. Ask anyone who does this for a living and they will tell you this process is long, frustrating and error-prone.
Even after you have developed a set of regular expressions that match the original set of messages, if new messages come in, you will have to determine which of the new messages need to be parsed. And if you develop a new set of regular expressions to parse those new messages, you still have no idea if the regular expressions will conflict with the ones you wrote before. If you write your regex parsers too liberally, it can easily parse the wrong messages.
After all that, you will end up finding out the regex parsers are quite slow. It can typically parse several thousands messages per second. Given enough CPU resources on a large enough machine, regex parsers can probably parse tens of thousands of messages per second. Even to achieve this type of performance, you will likely need to limit the number of regular expressions the parser has. The more regex rules, the slower the parser will go.
To work around this performance issue, companies have tried to separate the regex rules for different log message types into different parsers. For example, they will have a parser for Cisco ASA logs, a parser for sshd logs, a parser for Apache logs, etc etc. And then they will require the users to tell them which parser to use (usually by indicating the log source type of the originating IP address or host.)
Sequence is developed to make analyzing and parsing log messages a lot easier and faster.
Performance
The following performance benchmarks are run on a single 4-core (2.8Ghz i7) MacBook Pro. The first file is a bunch of sshd logs, averaging 98 bytes per message. The second is a Cisco ASA log file, averaging 180 bytes per message.
$ ./sequence bench -p ../../patterns/sshd.txt -i ../../data/sshd.all
Parsed 212897 messages in 1.69 secs, ~ 126319.27 msgs/sec
$ ./sequence bench -p ../../patterns/asa.txt -i ../../data/allasa.log
Parsed 234815 messages in 2.89 secs, ~ 81323.41 msgs/sec
$ ./sequence bench -d ../patterns -i ../data/asasshsudo.log
Parsed 447745 messages in 4.47 secs, ~ 100159.65 msgs/sec
Performance can be improved by adding more cores:
GOMAXPROCS=2 ./sequence bench -p ../../patterns/sshd.txt -i ../../data/sshd.all -w 2
Parsed 212897 messages in 1.00 secs, ~ 212711.83 msgs/sec
$ GOMAXPROCS=2 ./sequence bench -p ../../patterns/asa.txt -i ../../data/allasa.log -w 2
Parsed 234815 messages in 1.56 secs, ~ 150769.68 msgs/sec
$ GOMAXPROCS=2 ./sequence bench -d ../patterns -i ../data/asasshsudo.log -w 2
Parsed 447745 messages in 2.52 secs, ~ 177875.94 msgs/sec
Documentation
Documentation is available at godoc: package, command.
License
Copyright © 2014 Dataence, LLC. All rights reserved.
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Roadmap / Futures
There are some pattern files developed for ASA, Sudo and SSH in the patterns directory. The goal is to continue to develop a set of patterns for the various log messages, and along the way add additional features to the parser that can help make it even easier to parse log messages. So currently there’s not a set roadmap.
Concepts
The following concepts are part of the package:
A Token is a piece of information extracted from the original log message. It is a struct that contains fields for TokenType, FieldType, Value, and indicators of whether it’s a key or value in the key=value pair.
A TokenType indicates whether the token is a literal string (one that does not change), a variable string (one that could have different values), an IPv4 or IPv6 address, a MAC address, an integer, a floating point number, or a timestamp.
A FieldType indicates the semantic meaning of the token. For example, a token could be a source IP address (%srcipv4%), or a user (%srcuser% or %dstuser%), an action (%action%) or a status (%status%).
A Sequence is a list of Tokens. It is returned by the Tokenizer, and the Parser.
A Scanner is a sequential lexical analyzer that breaks a log message into a sequence of tokens. It is sequential because it goes through log message sequentially tokentizing each part of the message, without the use of regular expressions. The scanner currently recognizes time stamps, IPv4 addresses, URLs, MAC addresses, integers and floating point numbers. It also recgonizes key=value or key=“value” or key=‘value’ or key=
pairs. A Parser is a tree-based parsing engine for log messages. It builds a parsing tree based on pattern sequence supplied, and for each message sequence, returns the matching pattern sequence. Each of the message tokens will be marked with the semantic field types.
Sequence Command
The sequence command is developed to demonstrate the use of this package. You can find it in the sequence directory. The sequence command implements the sequential semantic log parser.
Usage:
sequence [command]
Available Commands:
scan scan will tokenize a log file or message and output a list of tokens
parse parse will parse a log file and output a list of parsed tokens for each of the log messages
bench benchmark the parsing of a log file, no output is provided
help [command] Help about any command
Scan
Usage:
sequence scan [flags]
Available Flags:
-h, --help=false: help for scan
-m, --msg="": message to tokenize
Example
$ ./sequence scan -m "jan 14 10:15:56 testserver sudo: gonner : tty=pts/3 ; pwd=/home/gonner ; user=root ; command=/bin/su - ustream"
# 0: { Field="%funknown%", Type="%ts%", Value="jan 14 10:15:56" }
# 1: { Field="%funknown%", Type="%literal%", Value="testserver" }
# 2: { Field="%funknown%", Type="%literal%", Value="sudo" }
# 3: { Field="%funknown%", Type="%literal%", Value=":" }
# 4: { Field="%funknown%", Type="%literal%", Value="gonner" }
# 5: { Field="%funknown%", Type="%literal%", Value=":" }
# 6: { Field="%funknown%", Type="%literal%", Value="tty" }
# 7: { Field="%funknown%", Type="%literal%", Value="=" }
# 8: { Field="%funknown%", Type="%string%", Value="pts/3" }
# 9: { Field="%funknown%", Type="%literal%", Value=";" }
# 10: { Field="%funknown%", Type="%literal%", Value="pwd" }
# 11: { Field="%funknown%", Type="%literal%", Value="=" }
# 12: { Field="%funknown%", Type="%string%", Value="/home/gonner" }
# 13: { Field="%funknown%", Type="%literal%", Value=";" }
# 14: { Field="%funknown%", Type="%literal%", Value="user" }
# 15: { Field="%funknown%", Type="%literal%", Value="=" }
# 16: { Field="%funknown%", Type="%string%", Value="root" }
# 17: { Field="%funknown%", Type="%literal%", Value=";" }
# 18: { Field="%funknown%", Type="%literal%", Value="command" }
# 19: { Field="%funknown%", Type="%literal%", Value="=" }
# 20: { Field="%funknown%", Type="%string%", Value="/bin/su" }
# 21: { Field="%funknown%", Type="%literal%", Value="-" }
# 22: { Field="%funknown%", Type="%literal%", Value="ustream" }
Parse
Usage:
sequence parse [flags]
Available Flags:
-h, --help=false: help for parse
-i, --infile="": input file, required
-o, --outfile="": output file, if empty, to stdout
-d, --patdir="": pattern directory,, all files in directory will be used
-p, --patfile="": initial pattern file, required
The following command parses a file based on existing rules. Note that the performance number (9570.20 msgs/sec) is mostly due to reading/writing to disk. To get a more realistic performance number, see the benchmark section below.
$ ./sequence parse -d ../../patterns -i ../../data/sshd.all -o parsed.sshd
Parsed 212897 messages in 22.25 secs, ~ 9570.20 msgs/sec
This is an entry from the output file:
Jan 15 19:39:26 jlz sshd[7778]: pam_unix(sshd:session): session opened for user jlz by (uid=0)
# 0: { Field="%createtime%", Type="%ts%", Value="jan 15 19:39:26" }
# 1: { Field="%apphost%", Type="%string%", Value="jlz" }
# 2: { Field="%appname%", Type="%string%", Value="sshd" }
# 3: { Field="%funknown%", Type="%literal%", Value="[" }
# 4: { Field="%sessionid%", Type="%integer%", Value="7778" }
# 5: { Field="%funknown%", Type="%literal%", Value="]" }
# 6: { Field="%funknown%", Type="%literal%", Value=":" }
# 7: { Field="%funknown%", Type="%string%", Value="pam_unix" }
# 8: { Field="%funknown%", Type="%literal%", Value="(" }
# 9: { Field="%funknown%", Type="%literal%", Value="sshd" }
# 10: { Field="%funknown%", Type="%literal%", Value=":" }
# 11: { Field="%funknown%", Type="%string%", Value="session" }
# 12: { Field="%funknown%", Type="%literal%", Value=")" }
# 13: { Field="%funknown%", Type="%literal%", Value=":" }
# 14: { Field="%object%", Type="%string%", Value="session" }
# 15: { Field="%action%", Type="%string%", Value="opened" }
# 16: { Field="%funknown%", Type="%literal%", Value="for" }
# 17: { Field="%funknown%", Type="%literal%", Value="user" }
# 18: { Field="%dstuser%", Type="%string%", Value="jlz" }
# 19: { Field="%funknown%", Type="%literal%", Value="by" }
# 20: { Field="%funknown%", Type="%literal%", Value="(" }
# 21: { Field="%funknown%", Type="%literal%", Value="uid" }
# 22: { Field="%funknown%", Type="%literal%", Value="=" }
# 23: { Field="%funknown%", Type="%integer%", Value="0" }
# 24: { Field="%funknown%", Type="%literal%", Value=")" }
Benchmark
Usage:
sequence bench [flags]
Available Flags:
-c, --cpuprofile="": CPU profile filename
-h, --help=false: help for bench
-i, --infile="": input file, required
-d, --patdir="": pattern directory,, all files in directory will be used
-p, --patfile="": pattern file, required
-w, --workers=1: number of parsing workers
The following command will benchmark the parsing of two files. First file is a bunch of sshd logs, averaging 98 bytes per message. The second is a Cisco ASA log file, averaging 180 bytes per message.
$ ./sequence bench -p ../../patterns/sshd.txt -i ../../data/sshd.all
Parsed 212897 messages in 1.69 secs, ~ 126319.27 msgs/sec
$ ./sequence bench -p ../../patterns/asa.txt -i ../../data/allasa.log
Parsed 234815 messages in 2.89 secs, ~ 81323.41 msgs/sec
Performance can be improved by adding more cores:
GOMAXPROCS=2 ./sequence bench -p ../../patterns/sshd.txt -i ../../data/sshd.all -w 2
Parsed 212897 messages in 1.00 secs, ~ 212711.83 msgs/sec
$ GOMAXPROCS=2 ./sequence bench -p ../../patterns/asa.txt -i ../../data/allasa.log -w 2
Parsed 234815 messages in 1.56 secs, ~ 150769.68 msgs/sec
Generating Porter2 FSM For Fun and Performance in Go 21 Jan 2015 7:48 PM (10 years ago)

tl;dr
- This post describes the Porter2 package I implemented. It is written in Go (#golang).
- By using a finite-state-machine approach to Porter2 stemming, I was able to achieve 660% better performance compare to other Go implementations.
- FSM-based approach is great for known/fixed data set, but obviously not workable if the data set changes at runtime.
- Hand-coding FSM is a PITA!!! Automate if possible.
Introduction
In a personal project I am working on, I had the need to perform word stemming in two scenarios. First, I need to perform stemming for all the string literals in a LARGE corpus and then determine if the words are in a fixed set of literals. Second, I need to perform stemming for a subset of words in real-time, as messages stream in.
In the first case, performance is important but not critical; in the second case, performance is a huge factor.
Stemming
To start, according to wikipedia:
Stemming is the term used in linguistic morphology and information retrieval to describe the process for reducing inflected (or sometimes derived) words to their word stem, base or root form—generally a written word form.
As a quick example, the words fail, failed, and failing all mean something has failed. By stemming these three words, I will get a single form which is fail. I can then just use fail going forward instead of having to compare all three forms all the time.
The Porter stemming algorithm is by far the most commonly used stemmer and also considered to be one of the most gentle stemmers. The Porter stemming algorithm (or ‘Porter stemmer’) works by removing the commoner morphological and inflexional endings from words in English. Its main use is as part of a term normalisation process that is usually done when setting up Information Retrieval systems. (ref)
Porter2 is universally considered to be an enhancement over the original Porter algorithm. Porter2 has an improved set of rules and it’s widely used as well.
Implementation
This package, Porter2, implements the Porter2 stemmer. It is written completely using finite state machines to perform suffix comparison, rather than the usual string-based or tree-based approaches. As a result, it is 660% faster compare to string comparison-based approach written in the same (Go) language.
This implementation has been successfully validated with the dataset from http://snowball.tartarus.org/algorithms/english/, so it should be in a usable state. If you encounter any issues, please feel free to open an issue.
Usage is fairly simple:
import "github.com/surgebase/porter2"
fmt.Println(porter2.Stem("seaweed")) // should get seawe
Performance
This implementation by far has the highest performance of the various Go-based implementations, AFAICT. I tested a few of the implementations and the results are below.
| Implementation | Time | Algorithm |
|---|---|---|
| surgebase | 319.009358ms | Porter2 |
| dchest | 2.106912401s | Porter2 |
| kljensen | 5.725917198s | Porter2 |
To run the test again, you can run compare.go (go run compare.go).
State Machines
Most of the implementations, like the ones in the table above, rely completely on suffix string comparison. Basically there’s a list of suffixes, and the code will loop through the list to see if there’s a match. Given most of the time you are looking for the longest match, so you order the list so the longest is the first one. So if you are luckly, the match will be early on the list. But regardless that’s a huge performance hit.
This implementation is based completely on finite state machines to perform suffix comparison. You compare each chacter of the string starting at the last character going backwards. The state machines will determine what the longest suffix is.
As an example, let’s look at the 3 suffixes from step0 of the porte2 algorithm. The goal, and it’s the same for all the other steps, it’s to find the longest matching suffix.
'
's
's'
If you were to build a non-space-optimized suffix tree, you would get this, where R is the root of the tree, and any node with * is designated as a final state:
R
/ \
'* s
/ \
s '*
/
'*
This is a fairly easy tree to build, and we actually did that in the FSM generator we will talk about later. However, to build a working suffix tree in Go, we would need to use a map[rune]*node structure at each of the nodes. And then search the map for each rune we encounter.
To test the performance of using a switch statement vs using a map, I wrote a quick test:
switch: 4.956523ms
map: 10.016601ms
The test basically runs a switch statement and a map each for 1,000,000 times. So it seems like using a switch statement is faster than a map. Though I think the compiler basically builds a map for all the switch case statements. (Maybe we should call this post Microbenchmarking for fun and performance?)
In any case, let’s go with the switch approach. We basically need to unroll the suffix tree into a finite state machine.
R0
/ \
'1* s2
/ \
s3 '4*
/
'5*
To do that, we need to assign a state number to each of the nodes in the suffix tree, and output each of the states and the transitions based on the rune encountered. The tree above is the same as the one before, but now has a state number assigned to each node.
Generator
I actually started building all the porter2 FSMs manually with a completely different approach than what I am describing here. I won’t go into details here but needless to say, it was disastrous. Not only was hand coding state machines extremely error-prone, the approach I was taking also had a lot of potential for bugs. It took me MANY HOURS to hand build those FSMs but at the end, I was happy to abandon all of them for the approach I am taking now.
To reduce errors and make updating the FSM easier, I wrote a quick tool called suffixfsm to generate the FSMs. The tool basically takes a list of suffixes, creates a suffix tree as described above, and unrolls the tree into a set of states using the switch statement.
It took me just a couple hours to write and debug the tool, and I was well on my way to fixing other bugs!
For example, running the command go run suffixfsm.go step0.txt generated the following code. This is a complete function for step0 of the porter2 algorithm. The only thing missing is what to do with each of the final states, which are in the last switch statement.
var (
l int = len(rs) // string length
m int // suffix length
s int // state
f int // end state of longgest suffix
r rune // current rune
)
loop:
for i := 0; i < l; i++ {
r = rs[l-i-1]
switch s {
case 0:
switch r {
case '\'':
s = 1
m = 1
f = 1
// ' - final
case 's':
s = 2
default:
break loop
}
case 1:
switch r {
case 's':
s = 4
default:
break loop
}
case 2:
switch r {
case '\'':
s = 3
m = 2
f = 3
// 's - final
default:
break loop
}
case 4:
switch r {
case '\'':
s = 5
m = 3
f = 5
// 's' - final
default:
break loop
}
default:
break loop
}
}
switch f {
case 1:
// ' - final
case 3:
// 's - final
case 5:
// 's' - final
}
return rs
Finally
This is a technique that can probably be applied to any fixed data set. The performance may vary based on the size of the state machine so test it with both maps and FSM to see what works best.
Happy Go’ing!
Go: From a Non-Programmer's Perspective 13 Jan 2015 12:30 PM (10 years ago)
Warning: Long Post. Over 3900 words according to wc. So read at your own risk. :)
Go is a fairly recent programming language created by Robert Griesemer, Rob Pike and Ken Thompson of Google. It has risen in popularity over the the past few years, especially since Go 1.0 was released.
There are a ton of posts out there that talks about the pros and cons of Go, and why one would use it or not. In addition, there’s a bunch of posts out there written by different developers coming from different perspectives, such as Python, Ruby, Node, Rust, etc, etc. Recently I even read a couple of Chinese blog posts on why Go is popular in China, and why some of the Chinese developers have abandoned Go, which are quite interesting as well.
This post is my perspective of Go, how I picked it up, and what I think of it after using it for a while. It is not a post about why Go is better or worse than other languages.
In short, I like Go. It’s the first programming language I’ve used in recent years that I can actually build some interesting projects, e.g., SurgeMQ (detailed post), in my limited spare time.
My Background
I am not a programmer/developer. Not full-time, not part-time, not moonlight. I tell my colleagues and teams that “I am not technical.”
But I do have a technical background. I have a MSCS degree from way back when, and have spent the first 6-7 years of my career performing security audits and penetration tests, and building one of the world’s largest managed security services (at least at the time).
My programming langauge progression, when I was technical, has been BASIC (high school), Pascal and C (college), Perl, PHP, Java, and Javascript (during my technical career). I can’t claim to be an “expert” in any of these languages, but I consider myself quite proficient in each at the time I was using them.
I was also reasonably network and system savvy, in the sense that I can get myself in and around the Solaris and Linux (UN*X) systems pretty well, and understand the networking stack sufficiently. I consider myself fairly proficient with the various system commands and tools.
For the past 12 years, however, I have not been a developer, nor a systems guy, nor a networking guy. Instead, I have been running product management for various startups and large companies in the security and infrastructure space.
Since the career change, I’ve not done any meaningful code development. I’ve written a script here and there, but nothing that I would consider to be “software.” However, I’ve managed engineering teams as part of my resonsibility, in addition to product management, to produce large scale software.
In the past 12 years, my most used IDE is called Microsoft Office. So, in short, I am probably semi-technical, and know just enough to be dangerous.
My History with Go
In 2011⁄2012, I had the responsibility of building a brand new engineering team (I was already running product management) at VMware to embark on a new strategic initiative. The nature of the product/service is not important now. However, at the time, because the team is brand new, we had some leeway in choosing a language for the project. VMware at the time was heavily Java, and specifically Spring given the 2009 acquisition of SpringSource. While the new team had mostly Java experience, there was desire to choose something less bloated, and something that had good support for the emerging patterns of distributed software.
First Touch
Some of the team members had experience with Scala, so that became an obvious option. I did some research on the web, and found some discussions of Go. At the time, Go hasn’t reached 1.0 yet, but there was already a buzz around it. I looked on Amazon, and found The Way to Go, which was probably the only Go book around at the time. For $3 on the Kindle, it was well worth it. However, due to the nascent nature of Go (pre 1.0), it was not a comfortable choice so I didn’t put that as an option. But this was my first touch of Go and it felt relatively painless.
At the end, the team chose Scala because of existing experience, and that in theory, people with Java experience should move fairly easily to Scala. We were the first team in VMware to use Scala and we were pretty excited about it.
However, to this date, I am still not sure we made the right decision to move to Scala (not that it’s wrong either.) The learning curve I believe was higher than we originally anticipated. Many of the developers wrote Java code w/ Scala syntax. And hiring also became an issue. Basically every new developer that came onboard must be sent to Typesafe for training. It was simply not easy for most developers who came from a non-functional mindset to jump into a totally functional mindset. Lastly, the knowledge differences of new Scala developers and experienced ones made it more difficult for them to collaborate.
I also tried to read up Scala and at least understand the concept. I even tried to take the online course on Coursera offered by Martin Odersky. However, I just could not get my non-functional mind to wrap around the functional Scala. And since I really didn’t need to code (nor the developers want me to), I gave up on learning Scala.
Second Touch
In any case, fast forward 2 years to Q3 of 2013. I had since left VMware and joined my current company, Jolata, to build a big data network analytics solutions for mobile carriers and high-frequency trading financial services firms. We are a small startup that’s trying to do a ton of things. So even though I run products, I have to get my hands dirty often.
One of the things we had to do as a company is to build a repeatable demo environment. The goal is to have a prebuilt vagrant VM that we can run on our Macs, and we can demonstrate our product without connecting to the network. The requirement was that we had an interesting set of data in the database so we can walk through different scenarios.
The data set we needed was network flow data. And to make the UI look realistic, interesting and non-blocky, we wanted to generate noisy data so the UI looks like it’s monitoring a real network. Because all of the developers are focused on feature development, I took on the task of building out the data set.
By now, Go has released v1.1 and on its way to 1.2. It was then I started seriously considering Go as a candidate for this project. To build a tool that can generate the data set, we needed two libraries. The first is a Perlin Noise generator, and the second is Google’s Cityhash. Neither of these were available in Go (or not that I remember). I thought this would be a great opportunity to test out Go. The end results were my Go Learn Projects #0 Perlin, and #1 Cityhash.
Both of these projects were relatively simple since I didn’t have to spend a lot of time figuring out HOW to write them. Perlin Noise has well-established C libraries and algorithms, and Cityhash was written in C so it was easy to translate to Go. However, these projects gave me a good feel of how Go works.
In the end, I wrote the data generator in Go (private repo) and got the first taste of goroutines. Again, this second touch with Go was also relatively painless. The only confusion I had at the time was the Go source tree structure. Trying to understand $GOROOT, $GOPATH and other Go environment variables were all new to me. This was also the first time in 10 years that I really spent time writing a piece of software, so I just considered the confusion as my inexperience.
Third Touch and Beyond
Today, I no longer code at work as we have more developers now. Also, the Jolata product is mostly C/C++, Java and Node, so Go is also no longer in the mix. However, After getting a taste of Go in the first couple of Go projects, I’ve since spent a tremendous amount of my limited personal spare time working with it.
I have since written various libraries for bitmap compression, integer compression, bloom filters, skiplist, and many others. And I have blogged my journey along the way as I learn. With these projects, I’ve learned how to use the Go toolchain, how to write idiomatic Go, how to write tests with Go, and more importantly, how to optimize Go.
Interestingly, one of my most popular posts is Go vs Java: Decoding Billions of Integers Per Second. This tells me that a lot of Java developers are potentially looking to adopt Go.
All these have allowed me to learn Go enough to build a real project, SurgeMQ. It is by far my most popular project and one that I expect to continue developing.
My Views on Go
Go is not just a langauge, it also has a very active community around it. The views are based on my observation over the past 1.5 years of using Go. My Go environment is primary Sublime Text 3 with GoSublime plugin.
As a Language…
I am not a language theorist, nor do I claim to be a language expert. In fact, prior to actually using Go, I’ve barely heard of generics, communicating sequential processes, and other “cool” and “advanced” concepts. I’ve heard of all the new cool programming languages such as Clojure and Rust, but have never looked at any of the code. So my view of Go is basically one of a developer n00b.
In a way, I consider that to be an advantage coming in to a new programming language, in that I have no preconceived notion of how things “SHOULD” be. I can learn the language and use the constructs as they were intended, and not have to question WHY it was designed that way because it’s different than what I know.
Others may consider this to be a huge disadvantage, since I don’t know any better. There maybe constructs in other languages that would make my work a lot easier, or make my code a lot simpler.
However, as long as the language doesn’t slow me down, then I feel it’s serving my needs.
Go is Simple
As a language for a new deverloper, Go was very easy to pick up. Go’s design is fairly simple and minimalistic. You can sit down and read through the Language Specification fairly quickly in an idle afternoon. I actually didn’t find the language reference until later. My first touch of Go was by scanning through the book The Way To Go. Regardless, there’s not a lot to the language so it’s relatively easy for someone like myself to pick up the basics. (Btw, I’ve also never gone through the Go Tour. I know it’s highly recommended to all new Go developers. I just never did it.)
There are more advanced concepts in Go, such as interface, channel, and goroutine. Channel in general is a fairly straightforward concept. Most new programmers should be able to understand that quickly. You write stuff in, you read stuff out. It’s that simple. From there, you can slowly expand on the concept as you go along by adding buffered channels, or ranging over channels, or checking if the read is ok, or using quit channels.
For anyone coming from a language with threads, goroutine is not a difficult concept to understand. It’s basically a light-weight thread that can be executed concurrently. You can run any function as a goroutine.
The more difficult concept is interface. That’s because it’s a fairly new concept that doesn’t really exist in concept that’s fairly different than other languages. Once you understand what interfaces are, it’s fairly easy to start using them. However, designing your own interfaces is a different story.
The one thing I’ve seen most developers complain about Go is the lack of generics. Egon made a nice Summary of Go Generics Discussions that you can read through. For me personally, I don’t know any better. I have never used generics and I haven’t found a situation where I strongly require it.
As a language a team, the simplicity of Go is HUGE. It allows develoeprs to quickly come up to speed and be productive in the shortest period of time. And in this case, time is literally money.
Go is Opinionated
Go is opinionated in many ways. For example, probably one of the most frustrating thing about Go is how to structure the code directory. Unlike other languages where you can just create a directory and get started, Go wants you to put things in $GOPATH. It took a few readings of How to Write Go Code for me to grasp what’s going on, and it took even longer for me to really get the hang of code organization, and how Go imports packages (e.g., go get).
If I go back and look at my first internal project, I would probably cry because it’s all organized in a non-idiomatic way. However, once I got the hang of how Go expects things to be organized, it no longer was a obstacle for me. Instead of fighting the way things should be organized in Go, I learned to go with the flow. At the end of the day, the $GOPATH organizational structure actually helps me track the different packages I import.
Another way Go is opinionated is code formatting. Go, and Go developers, expect that all Go programs are formatted with go fmt. A lot of developers hate it and some even listed it as a top reason for leaving Go. However, this is one of those things that you just have to learn to go with the flow. Personally I love it.
And as a team language it will save a ton of argument time. Again, time is money for a new team. When my new VMware team got started, we probably spent a good 30 person-hours debating code formatting. That’s $2700 at a $180K fully-burdened rate. And that’s not counting all the issues we will run into later trying to reformat code that’s not properly formatted.
Go is also very opininated in terms of variable use and package import. If a variable is declared but not used, the Go compiler will complain. If a package is imported but not used, the Go compiler will complain. Personally, I like the compiler complaining about the unused variables. It keeps the code clean, and reduce the chance of unexpected bugs. I am less concerned about unused packages but have also learned to live with the compiler complains. I use goimports in Sublime Text 3 to effectively and quickly take care of the import statements. In fact, in 99% of the cases I don’t even need to type in the import statements myself.
Go is Safe
Go is safe for a couple of reasons. For a new developer, Go does not make it easy for you to be lazy. For example, Go is a statically typed language, which means every variable must explicitly have a type associated with it. The Go compiler does infer types under certain situations, but regardless, there’s a type for every variable. This may feel uncomfortable for developers coming from dynamic languages, but the benefit definitely outweighs the cost. I’ve experience first hand, as a product person waiting for bugs to be fixed, how long it takes to troubleshoot problems in Node. Having static types gives you a feeling of “correctness” after you have written the code.
Another example of Go not allowing you to be lazy is that Go’s error handling is through the return of error from functions. There has been a ton of discussions and debates on the merit of error vs exception handling so I won’t go through it here. However, for a new programmer, it really requires your explicit attention to handle the errors. And I consider that to be a good thing as you know what to expect at each step of the program.
Making things explicit and making it harder for developers to be lazy are a couple of the reasons that make Go safe.
Another reason is that Go has a garbage collector. This makes it different from C/C++ as it no longer require developers to perform memory management. The difficulty in memory management is the single biggest source of memory leaks in C/C++ programs. Having a GC removes that burden from developers and makes the overall program much safer. Having said that, there’s much improvement to be made to the GC given its nascent state. And, as I learned over the past 1.5 years, to write high performance programs in Go today, developers need to make serious efforts to reduce GC pressure.
Again, as a team langauge, the safety aspect is very important. The team will likely end up spending much less time dealing with memory bugs and focus more on feature development.
Go is Powerful
What makes Go powerful are its simplicity, its high performance, and advanced concepts such as channels, goroutines, interfaces, type composition, etc. We have discussed all of these in previous sections.
In addition to all that, one of the killer feature of Go is that all Go programs are statically compiled into a single binary. There’s no shared libraries to worry about. There’s no jar files to worry about. There’s no packages to bundle. It’s just a single binary. And that’s an extremely powerful feature from the deployment and maintenance perspectives. To deploy a Go program, you just need to copy a single Go binary over. To update it, copy a single Go binary over.
In contrast, to deploy a Node.js application, you may end up downloading hundreds of little packages at deployment time. And you have to worry about whether all these packages are compatible. The Node community has obviously developed a lot of good tools to manage dependencies and version control. But still, every time I see a Node app get deployed on a new machine, and have to download literally hundreds of little packages, I die a little inside.
Also, if you deploy C/C++ programs and depend on shared libraries, now you have to worry about OS and shared library version compatibility issues.
Another powerful feature of Go is that you can mix C and assembly code with Go code in a single program. I haven’t used this extensively, but in my attempt to optimize the integer compression library, I added different C and assembly snippets to try to squeeze the last ounce of performance out of Go. It was fairly easy and straightforward to do.
One last thing, Go has a very large and complete standard library. It enables developers to do most, if not all, of their work quickly and efficiently. As the language matures and the community grows, there will be more and more 3rd party open source libraries one can leverage.
As a Community
Today, Go has a very active community behind it. Specifically, the information sources I’ve followed and gotten help from include #go-nuts IRC, golang subreddit, and obviously the golang-nuts mailing list.
I spent quite a bit of time in IRC when I first started. I’ve gotten help from quite a few people such as dsal, tv42, and others, and I am grateful for that. I am spending less time there now because of the limited time I have (remember, my day job is not development. :)
There’s been some sentiments in the developer community that Go developers (gophers) are Google worshippers, don’t accept any feedbacks on language changes, harsh to new comers who come from different languages, difficult to ask questions because the sample code is not on play.golang.org, etc etc.
To be clear, I’ve never really spent much time with the different language communites, even when I was technical. So I have nothing else to compare to. So I can only speak from a human interaction level.
I can see it from both perspectives. For example, developers coming from different language backgrounds sometimes have experience with a different way of doing things. When they want to perfrom the same tasks in Go, they ask the question by saying here’s how I solved this problem in language X, how do I translate that to Go?
In some cases I’ve definitely seen people responding by saying that’s not how Go works and you are doing it wrong. That type of response can quickly create negative sentiment and kill the conversation.
Another type of response I’ve seen is some developers telling the original poster (OP) that they are not asking questions the right way, and then promptly sending the OP a link to some web page on how to properly ask questions. Again, I can see how the OP can have a negative view on the matter.
I’ve expereinced some of this myself. When I implemented a Bloom Filter package last year, I did a bunch of performance tests and wrote a blog post about the it. As a newbie learning Go, I felt like I accomplished something and I was pretty happy with it. I posted the link to reddit, and the first comment I got was
Downvoted because I dislike this pattern of learning a new language and then immediately publishing performance data about it, before you know how to write idiomatic or performant code in it.
Ouch!! As a new Go developer, this is not the response I expected. In the end though, the commenter also pointed out something that helped me improve the performance of the implementation. I was grateful for that. It was also then I realized how important it is to reduce the number of allocation in order to reduce the Go GC pressure.
In hindsight, the comment has a very valid point. I can understand why some developers would feel annoyed about benchmarks from people who have no idea on what they are doing. Regardless, being nice is not a bad thing. Saying things like “WTF is wrong with you” (not related to the bloom filter post) will only push new developers away.
I quickly got over the sting because I am just too old to care about what others think I should or should not do. I continued my learning process by writing and optimizing Go packages, and posting the results in my blog. In fact, the Go vs Java: Decoding Billions of Integers Per Second post has many of the optimization techniques I tried to increase the performance of Go programs.
Overall though, I felt I’ve learned a ton from the Go community. People have generally been helpful and are willing to offer solutions to problems. I have nothing to compare to, but I feel that the positives of the Go community far outweighs any negatives.
Conclusion
In conclusion, it has been a tremendous 1.5 years of working with Go, and seeing Go grow both as a language and as a community has been very rewarding.
My focus now, in my limited spare personal time, is to continue the development of SurgeMQ, which is a high performance MQTT broker and client library that aims to be fully compliant with MQTT 3.1 and 3.1.1 specs.
PingMQ: A SurgeMQ-based ICMP Monitoring Tool 24 Dec 2014 11:00 PM (10 years ago)
pingmq is developed to demonstrate the different use cases one can use SurgeMQ, a high performance MQTT server and client library. In this simplified use case, a network administrator can setup server uptime monitoring system by periodically sending ICMP ECHO_REQUEST to all the IPs in their network, and send the results to SurgeMQ.
Then multiple clients can subscribe to results based on their different needs. For example, a client maybe only interested in any failed ping attempts, as that would indicate a host might be down. After a certain number of failures the client may then raise some type of flag to indicate host down.
There are three benefits of using SurgeMQ for this use case.
- First, with all the different monitoring tools out there that wants to know if hosts are up or down, they can all now subscribe to a single source of information. They no longer need to write their own uptime tools.
- Second, assuming there are 5 monitoring tools on the network that wants to ping each and every host, the small packets are going to congest the network. The company can save 80% on their uptime monitoring bandwidth by having a single tool that pings the hosts, and have the rest subscribe to the results.
- Third/last, the company can enhance their security posture by placing tighter restrictions on their firewalls if there’s only a single host that can send ICMP ECHO_REQUESTS to all other hosts.
The following commands will run pingmq as a server, pinging the 8.8.8.0/28 CIDR block, and publishing the results to /ping/success/{ip} and /ping/failure/{ip} topics every 30 seconds. sudo is needed because we are using RAW sockets and that requires root privilege.
$ go build
$ sudo ./pingmq server -p 8.8.8.0/28 -i 30
The following command will run pingmq as a client, subscribing to /ping/failure/+ topic and receiving any failed ping attempts.
$ ./pingmq client -t /ping/failure/+
8.8.8.6: Request timed out for seq 1
The following command will run pingmq as a client, subscribing to /ping/failure/+ topic and receiving any failed ping attempts.
$ ./pingmq client -t /ping/success/+
8 bytes from 8.8.8.8: seq=1 ttl=56 tos=32 time=21.753711ms
One can also subscribe to a specific IP by using the following command.
$ ./pingmq client -t /ping/+/8.8.8.8
8 bytes from 8.8.8.8: seq=1 ttl=56 tos=32 time=21.753711ms
Commands
There are two builtin commands for pingmq.
pingmq server
Usage:
pingmq server [flags]
Available Flags:
-h, --help=false: help for server
-i, --interval=60: ping interval in seconds
-p, --ping=[]: Comma separated list of IPv4 addresses to ping
-q, --quiet=false: print out ping results
-u, --uri="tcp://:5836": URI to run the server on
pingmq client
Usage:
pingmq client [flags]
Available Flags:
-h, --help=false: help for client
-s, --server="tcp://127.0.0.1:5836": PingMQ server to connect to
-t, --topic=[]: Comma separated list of topics to subscribe to
IP Addresses
To list IPs you like to use with pingmq, you can use the following formats:
10.1.1.1 -> 10.1.1.1
10.1.1.1,2 -> 10.1.1.1, 10.1.1.2
10.1.1,2.1 -> 10.1.1.1, 10.1.2.1
10.1.1,2.1,2 -> 10.1.1.1, 10.1.1.2 10.1.2.1, 10.1.2.2
10.1.1.1-2 -> 10.1.1.1, 10.1.1.2
10.1.1.-2 -> 10.1.1.0, 10.1.1.1, 10.1.1.2
10.1.1.1-10 -> 10.1.1.1, 10.1.1.2 ... 10.1.1.10
10.1.1.1- -> 10.1.1.1 ... 10.1.1.254, 10.1.1.255
10.1.1-3.1 -> 10.1.1.1, 10.1.2.1, 10.1.3.1
10.1-3.1-3.1 -> 10.1.1.1, 10.1.2.1, 10.1.3.1, 10.2.1.1, 10.2.2.1, 10.2.3.1, 10.3.1.1, 10.3.2.1, 10.3.3.1
10.1.1 -> 10.1.1.0, 10.1.1.1 ... 10.1.1.254, 10.1.1.255
10.1.1-2 -> 10.1.1.0, 10.1.1.1 ... 10.1.1.255, 10.1.2.0, 10.1.2.1 ... 10.1.2.255
10.1-2 -> 10.1.0.0, 10.1.0,1 ... 10.2.255.254, 10..2.255.255
10 -> 10.0.0.0 ... 10.255.255.255
10.1.1.2,3,4 -> 10.1.1.1, 10.1.1.2, 10.1.1.3, 10.1.1.4
10.1.1,2 -> 10.1.1.0, 10.1.1.1 ... 10.1.1.255, 10.1.2.0, 10.1.2.1 ... 10.1.2.255
10.1.1/28 -> 10.1.1.0 ... 10.1.1.255
10.1.1.0/28 -> 10.1.1.0 ... 10.1.1.15
10.1.1.0/30 -> 10.1.1.0, 10.1.1.1, 10.1.1.2, 10.1.1.3
10.1.1.128/25 -> 10.1.1.128 ... 10.1.1.255
Topic Format
TO subscribe to the pingmq results, you can use the following formats:
/ping/#will subscribe to both success and failed pings for all IP addressesping/success/+will subscribe to success pings for all IP addressesping/failure/+will subscribe to failed pings for all IP addressesping/+/8.8.8.8will subscribe to both success and failed pings for all IP 8.8.8.8
Building
To build pingmq, you need to have installed Go 1.3.3 or 1.4. Then run the following:
# go get github.com/surge/surgemq
# cd surgemq/examples/pingmq
# go build
After that, you should see the pingmq command in the pingmq directory.